Laborum voluptate pariatur ex culpa magna nostrud est incididunt fugiat pariatur do dolor ipsum enim. Consequat tempor do dolor eu. Non id id anim anim excepteur excepteur pariatur nostrud qui irure ullamco.
用 Python 搭一个本地 AI 知识库
本文使用的技术栈为python+qdrant(docker 镜像)+ollama(使用嵌入模型 bge-m3)+deepseek(兼容 openai 接口)。如果连大模型都想用本地部署的,只需要用ollama再下载个deepseek大模型,将配置改成本地即可。
预先启动向量数据库及嵌入模型服务。
$ docker run -d -ti -p 6333:6333 qdrant/qdrant # 启动向量数据库
$ ollama pull bge-m3 # 启动本地嵌入模型 bge-m3,注意,嵌入模型的好坏影响匹配结果
以下是整个应用的整体流程。
1. init_collection:初始化向量数据库(qdrant),生成知识库对应的 collection;
2. embed(作为 ingest 的子步骤):通过嵌入模型(bge-m3)将知识库的内容生成对应的嵌入向量(embed);
3. ingest:将嵌入向量及其对应的知识库内容一一匹配地插入向量数据库(qdrant);
4. search:将客户端搜索的内容(question)进行向量化(embed)之后传到向量数据库(qdrant)进行匹配,获取匹配分数高的数据(context),这里可以根据需要稍微获取多一些匹配的数据(limit),减少嵌入模型(bge-m3)的误差,但也不能太大,一般 3-5 即可,否则把不相关的内容也塞给大模型,反而干扰回答;
5. chat:将向量数据库中匹配到的知识库内容(context)和客户端搜索的内容(question)一起作为查询内容传给大模型(deepseek)进行处理,这就是传说中的 RAG(Retrieval-Augmented Generation,检索增强生成)了;
6. main:将大模型(deepseek)返回的数据返回给客户端;
代码如下,由于兼容openai的接口,根据实际情况修改自己的base_url、api_key和model即可。
import os
from openai import OpenAI
import requests
# ─── 配置 ─────────────────────────────────────────────────
OLLAMA_URL = "http://localhost:11434"
OLLAMA_EMBED_MODEL = "bge-m3" # 嵌入模型,这个对中文支持比较好,其它支持不好的模型可能很难获取到预期效果
QDRANT_URL = "http://localhost:6333"
COLLECTION = "product_kb" # 类似于关系型数据库的“table”概念
client = OpenAI(
base_url=os.environ.get("LLM_BASE_URL", "https://api.deepseek.com/v1"),
api_key=os.environ.get("LLM_API_KEY", "sk-xxx"),
)
LLM_MODEL = os.environ.get("LLM_MODEL", "deepseek-chat")
# ─── 嵌入模型 ─────────────────────────────────────────────
def embed(text: str) -> list:
res = requests.post(f"{OLLAMA_URL}/api/embed", json={
"model": OLLAMA_EMBED_MODEL,
"input": text,
})
return res.json()["embeddings"][0]
# ─── Qdrant ───────────────────────────────────────────────
def qdrant(method: str, path: str, body: dict = None):
res = requests.request(method, f"{QDRANT_URL}{path}", json=body)
return res.json()
# ─── 初始化 Collection ────────────────────────────────────
def init_collection():
qdrant("DELETE", f"/collections/{COLLECTION}")
qdrant("PUT", f"/collections/{COLLECTION}", {
"vectors": {"size": 1024, "distance": "Cosine"},
})
print("Collection 创建完成")
# ─── 导入知识库 ───────────────────────────────────────────
def ingest(docs):
points = []
for doc in docs:
print(f"嵌入中:{doc['text'][:20]}...")
points.append({
"id": doc["id"],
"vector": embed(doc["text"]),
"payload": {"text": doc["text"]},
})
qdrant("PUT", f"/collections/{COLLECTION}/points", {"points": points})
print("知识库导入完成")
# ─── 检索 ─────────────────────────────────────────────────
def search(question: str, limit: int = 2) -> list:
vector = embed(question)
result = qdrant("POST", f"/collections/{COLLECTION}/points/search", {
"vector": vector,
"limit": limit,
"with_payload": True,
})
hits = result["result"]
for h in hits:
print(f"分数: {h['score']:.4f} | {h['payload']['text'][:30]}")
return [h["payload"]["text"] for h in hits]
# ─── LLM 调用 ─────────────────────────────────────────────
def chat(question: str, context: str) -> str:
res = client.chat.completions.create(
model=LLM_MODEL,
messages=[
{"role": "system", "content": "你是知识库助手,根据提供的知识库内容自由回答。"},
{"role": "user", "content": f"知识库:\n{context}\n\n问题:{question}"},
],
)
print("\n知识库:")
print(context)
return res.choices[0].message.content
# ─── 主流程 ───────────────────────────────────────────────
def ask(question: str) -> str:
docs = search(question)
context = "\n".join(docs)
return chat(question, context)
if __name__ == "__main__":
knowledge = [
{"id": 1, "text": "退款流程:在订单页面点击申请退款,填写原因,3个工作日内处理完成。"},
{"id": 2, "text": "发货时间:下单后24小时内发货,节假日顺延。"},
{"id": 3, "text": "保修政策:产品自购买日起享有一年免费保修服务。"},
]
my_question = "我想退款,怎么操作?"
init_collection()
ingest(knowledge)
print(f"\n问题:{my_question}")
print(f"\n回答:\n{ask(my_question)}")
大模型使用工具的能力怎么来的
大模型会提供一个叫Tool Calls(也有的叫Function Calls)的功能,看起来很神奇,实际上就是LLM根据对话内容提取出需要使用的工具及其参数,再将其以结构化的形式返回给客户端,客户端通过响应的内容判断是否存在“使用工具”这个操作,如果存在,则从中获取所需使用的“工具名”及“参数”来使用工具。
看以下python写的一个示例。
import json
import os
import sys
from openai import OpenAI
API_KEY = "sk-xxx"
client = OpenAI(api_key=API_KEY, base_url="https://api.deepseek.com")
ESC = "\033"
COLOR_FAIL = ESC + "[31m"
COLOR_SUCCESS = ESC + "[32m"
MSG_FAIL = "fail"
MSG_SUCCESS = "success"
RESET = ESC + "[0m"
def pretty_msg(msg, color=COLOR_FAIL):
"""美化提示"""
colors = {MSG_FAIL: COLOR_FAIL, MSG_SUCCESS: COLOR_SUCCESS}
color = COLOR_FAIL if colors.get(color) is None else colors.get(color)
return f"{color}{msg}{RESET}"
def code(name):
"""执行代码生成任务"""
try:
print(COLOR_FAIL + "+" * 50 + "\n" + COLOR_SUCCESS, sep="", end="")
os.system('ls -l ~')
print(COLOR_FAIL + "-" * 50 + RESET, sep="")
return "用 {} 写一个简单的字符串反转函数".format(name)
except Exception as e:
print(pretty_msg("内部执行错误: {}".format(str(e))))
sys.exit(1)
def safe_chat_completion(**kwargs):
"""安全的 API 调用包装器"""
try:
return client.chat.completions.create(**kwargs)
except Exception as e:
print(pretty_msg("调用失败: {}".format(str(e))))
sys.exit(1)
def main(content):
"""主函数"""
print("正在处理请求...")
content = "如果你从这段话'{}'中获取到编程语言的名称,就调用 code 函数,并将编程语言的名称作为 name 参数。".format(content)
# 第一次调用:检测是否需要调用工具
response = safe_chat_completion(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": content},
],
tools=[
{
"type": "function",
"function": {
"name": "code",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
}
},
"required": ["name"]
}
},
}
],
tool_choice="auto"
)
message = response.choices[0].message
# 输出第一次响应
if message.content:
print('first:', message.content)
else:
print('first: (无文本内容)')
# 处理工具调用
if hasattr(message, 'tool_calls') and message.tool_calls:
for tool_call in message.tool_calls:
if tool_call.function.name == "code":
try:
arguments = json.loads(tool_call.function.arguments)
name = arguments.get("name", "未知语言")
result = code(name)
# 第二次调用:带工具结果的流式响应
second_response = safe_chat_completion(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": content},
message, # 模型的 tool call 响应
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
}
],
stream=True
)
print("\nsecond:")
for chunk in second_response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")
print() # 换行
except json.JSONDecodeError:
print(pretty_msg("错误:无法解析工具调用参数"))
sys.exit(1)
except KeyError as e:
print(pretty_msg("错误:缺少必需参数 {}".format(str(e))))
sys.exit(1)
except Exception as e:
print(pretty_msg("执行错误 {}".format(str(e))))
sys.exit(1)
else:
if message.content:
print('first:', message.content)
else:
print("未检测到工具调用")
if __name__ == "__main__":
try:
content = "你知道吗?python 是世界最好的语言。"
main(content)
except KeyboardInterrupt:
print(pretty_msg("用户中断执行"))
sys.exit(1)
except Exception as e:
print(pretty_msg("未预期的错误:{}".format(str(e))))
sys.exit(1)
以上代码会从让LLM从用户的对话中判断是否存在编程语言的名称,如果存在,则返回Tool Calls响应,客户端针对该响应进行调用code工具,再将code工具的返回内容进行再次对话。
随便唠唠异步
再看操作系统原理时,又“吸收”了一个名词“页缓存”,跟ChatGPT扯了下之后,就有了更深刻的理解,于是灵光一现问了以下问题:
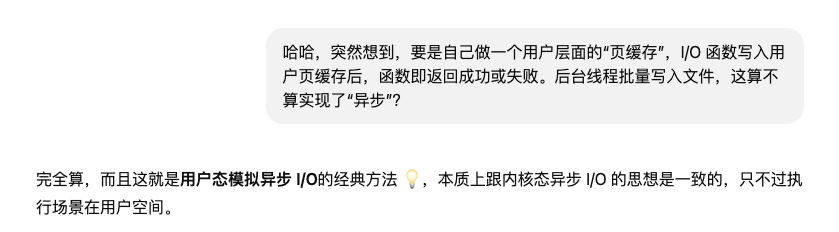
异步I/O的本质就是提交I/O后,不会阻塞调用者,并在I/O完成后通知调用者结果。
现在分析一下我的问题。在用户层面实现I/O函数,并通过用户层面实现的“页缓存”(本质上就是内存)来处理数据。也就是说,在数据落盘前,I/O函数只需要跟内存打交道,只要在内存层面处理好数据即可返回处理结果,因此实际上I/O操作并不会阻塞调用者,而可以在后台线程统一对这些用户层面的“页缓存”同步到I/O设备,完成后再通知业务线程。所以这种实现方式在原理上可行的,当然实际上还有很多细节要处理。
最近PHP社区讨论异步RFC闹得沸沸扬扬,哎,不知道该怎么评价,大部分社区成员都希望保持PHP的简单性,不希望引入复杂的异步,无共享架构深入人心了,而且添加异步是否会影响现存的大量项目也是很多人纠结的。也有很多社区声音觉得PHP应该抛弃沉重的包袱,大胆更新。目前看讨论情况,估计是难了,异步功能庞大,推动的人应该只能说只有一个,挺佩服作者的,单枪匹马坚持了一年多;另外PHP社区中缺少相应领域的编译器专家,即使功能是好的,但能审核的人也没几个,大家对自己不懂的东西还是很保守的。
数组越界导致的函数调用
C语言中数组越界是未定义行为,因此以下代码在不同的编译器或者不同版本的同一编译器行为是不可预测的。在gcc某些版本中,以下代码会出现有意思的行为。
// demo.c
#include <stdio.h>
#include <stdlib.h>
void jmp() {
printf("Hello jmp\n");
exit(1);
}
void func() {
long arr[2];
arr[3] = (long)jmp;
}
int main() {
func();
printf("Hello main\n");
return 0;
}
编译使用的gcc信息如下:
$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/12/lto-wrapper
OFFLOAD_TARGET_NAMES=nvptx-none:amdgcn-amdhsa
OFFLOAD_TARGET_DEFAULT=1
Target: x86_64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Debian 12.2.0-14' --with-bugurl=file:///usr/share/doc/gcc-12/README.Bugs --enable-languages=c,ada,c++,go,d,fortran,objc,obj-c++,m2 --prefix=/usr --with-gcc-major-version-only --program-suffix=-12 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --enable-default-pie --with-system-zlib --enable-libphobos-checking=release --with-target-system-zlib=auto --enable-objc-gc=auto --enable-multiarch --disable-werror --enable-cet --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none=/build/gcc-12-bTRWOB/gcc-12-12.2.0/debian/tmp-nvptx/usr,amdgcn-amdhsa=/build/gcc-12-bTRWOB/gcc-12-12.2.0/debian/tmp-gcn/usr --enable-offload-defaulted --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu
Thread model: posix
Supported LTO compression algorithms: zlib zstd
gcc version 12.2.0 (Debian 12.2.0-14)
行为如下:
浅谈 FrankenPHP 对 PHP 的影响
今年PHP基金会宣布了一件事30 years of PHP: FrankenPHP is now part of the PHP organisation。那么FrankenPHP是什么?为何得到青睐?
示例
对官网的自定义示例进行了一点调整,毕竟那个有点正式框架的影子,刚开始也让我有点摸不着头脑。
<?php
// index.php
ini_set('display_errors', 'on');
ignore_user_abort(true);
$handler = static function () {
header('Content-Type: application/json;charset=utf-8');
echo json_encode(['name' => 'william'], JSON_UNESCAPED_UNICODE|JSON_UNESCAPED_SLASHES);
};
$maxRequests = (int)($_SERVER['MAX_REQUESTS'] ?? 0);
for ($nbRequests = 0; !$maxRequests || $nbRequests < $maxRequests; ++$nbRequests) {
$keepRunning = frankenphp_handle_request($handler);
gc_collect_cycles();
if (!$keepRunning) {
break;
}
}
观察以上代码,FrankenPHP常驻内存的原理很简单,先解释执行worker脚本,脚本的核心就是一个循环(视情况可以无限循环,如果不放心,处理指定次数即可退出启动新
worker进程),FrankenPHP通过frankenphp_handle_request同步阻塞接收HTTP请求,接收请求后调用$handler函数,$handler
函数就是实际的代码逻辑,在这之前的代码可以是核心功能如加载路由类、数据库类等等,后续每次请求-响应周期都不再需要加载核心类。看到到这里,
FrankenPHP的worker模式提升性能的原因显而易见,常规的fpm项目,每次请求-响应都需要重新解释(有OpCache
则可省略这一步)执行,申请内存,甚至动态加载文件频繁IO操作,在大量请求时,累计的差距就会非常大。
但由于大部分fpm下的生态发展多年,架构天生无共享短生命周期,很多开发者的代码都不一定会考虑内存常驻的情况,直接迁移到
FrankenPHP的worker模式可能会水土不服,甚至需要改动项目逻辑。因此最好开始不要用worker模式,classic模式即可直接适配。
如果要改造自己的项目,对$handler函数进行修改,判断$_SERVER['REQUEST_URI']作为路由调用对应的控制器,如此这般,就是一个简单的框架。
运行
-l参数是监听地址,--worker参数是作为worker模式脚本的文件,--watch用于热更新。
$ frankenphp-mac-arm64 php-server -l 0.0.0.0:9292 --worker=./index.php,20 --watch ./index.php
测试
对比fpm脚本,同样20个worker进程。测试是在资源受限的云服务器docker容器中,数据会比一般开发机稍差。
<?php
// fpm.php
header('Content-Type: application/json;charset=utf-8');
echo json_encode(['name' => 'william'], JSON_UNESCAPED_UNICODE|JSON_UNESCAPED_SLASHES);
$ wrk http://localhost/fpm.php
Running 10s test @ http://localhost/fpm.php
2 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 3.57ms 4.03ms 78.87ms 94.31%
Req/Sec 1.59k 382.27 2.58k 72.50%
31700 requests in 10.00s, 6.95MB read
Requests/sec: 3168.86
Transfer/sec: 711.74KB
$ wrk http://localhost:9292/
Running 10s test @ http://localhost:9292/
2 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.52ms 2.23ms 31.96ms 92.20%
Req/Sec 4.90k 528.36 6.20k 73.50%
97580 requests in 10.00s, 16.84MB read
Requests/sec: 9757.60
Transfer/sec: 1.68MB
FrankenPHP的worker模式RPS达到9757.60,虽然只是一个简单的输出,跟php-fpm
相比,提升可谓非常大,这就是它得到青睐的最大原因。**需要注意的是:FrankenPHP 能大幅提升性能的前提是响应周期很短,如果服务端业务比较复杂,对性能的提升效果并没有想象中那么大,毕竟它的核心原理就是减少每次响应时的准备步骤,如果程序大部分时间都消耗在运行中,那么与其相比,节省的准备时间倒显得微乎其微。**有兴趣可以继续测试以下对比脚本,看看FrankenPHP的优势还剩多少。
用 composer 将 packagist 第三方库变成本地库
之所以有这个想法,是因为部分第三方库版本约束没有做好,导致版本不匹配的库也可以安装,库版本不兼容到运行时才得以暴露,影响很大。
以workerman/mqtt为例,2.1版本跟workerman/workerman:^4.0是不兼容的,但 composer.json 的require是"workerman/workerman" : "^4.0 | ^5.0"。当然直接composer require workerman/mqtt:2.1是没有问题的,如果是在已有的workerman/workerman:^4.0项目中require可以安装2.1版本,但运行时就会产生不兼容的错误提示。
Fatal error: Declaration of Workerman\Mqtt\Protocols\Mqtt::input(string $buffer, Workerman\Connection\ConnectionInterface $connection): int must be compatible with Workerman\Protocols\ProtocolInterface::input($recv_buffer, Workerman\Connection\ConnectionInterface $connection) in /usr/share/php/programming_practice/php/php-frameworks-test/workerman4_mqtt2/vendor/workerman/mqtt/src/Protocols/Mqtt.php on line 136
如果第三方库没有及时修改,我们就需要自己来调整一下。composer默认会从packagist查询依赖地址并依此下载,在将第三方库变成本地库时,可以沿用composer的依赖加载机制。
首先将有问题的库移出vendor目录统一放到项目根目录的third_party目录中,并将当前使用的库版本"version": "2.1"记录到库的composer.json中,再将workerman/workerman的版本约束改为^5.0。
$ mkdir third_party
$ mv vendor/workerman/mqtt third_party
$ vim third_party/mqtt/composer.json
{
"version": "2.1",
"require": {
"php": "^8.0",
"workerman/workerman" : "^5.0"
},
// ... 此处省略其它 key:value
}
接着给项目的composer.json添加搜索本地路径的键值对。
$ vim composer.json
{
"repositories": [
{
"type": "path",
"url": "./third_party/mqtt"
}
],
// ... 此处省略其它 key:value
}
现在可以再次composer require workerman:mqtt:2.1了,得到以下提示:
用 Workerman 及 EMQX 做一个简单的 MQTT 示例
$ docker run -d --name emqx -e EMQX_DASHBOARD__DEFAULT_PASSWORD=admin --network=lnmp -ti -p 18083:18083 -p 1883:1883 -p 8083-8084:8083-8084 -p 4370:4370 -p 5369:5369 emqx/emqx:5.8
$ composer require workerman/mqtt:2.1
<?php
use Workerman\Timer;
use Workerman\Worker;
require_once __DIR__ . '/vendor/autoload.php';
$worker = new Worker();
$worker->onWorkerStart = function () {
$mqttClients = [];
for ($i = 0; $i < 10000; $i++) {
$mqttClients[$i] = new Workerman\Mqtt\Client('mqtt://emqx:1883');
$mqttClients[$i]->onConnect = function ($mqttClient) {
$mqttClient->subscribe('test');
};
$mqttClients[$i]->onMessage = function ($topic, $content) use ($i) {
echo $i, "\t", $topic, "\t", $content, "\n";
};
$mqttClients[$i]->connect();
}
$num = 1;
Timer::add(1, function () use ($mqttClients, &$num) {
try {
$mqttClients[0]->publish('test', 'hello ' . $num);
$num += 1;
} catch (Throwable $e) {
echo "Throwable:", $e->getMessage(), "\n";
}
});
};
try {
Worker::runAll();
} catch (Throwable $e) {
echo $e->getMessage(), "\n";
}
字节码缓存提升程序性能的原理浅谈
像Java这类语言,编译器会把代码预先编译为字节码,JVM直接解释执行这些字节码,程序就可以运行起来了。PHP使用者在性能优化时可能也会遇到OPcache这个名词,所谓OPcache其实就是opcode的cache,opcode其实类似于字节码,虽然本质上有点差异,但可以类比为同一种事物。
PHP在开启OPcache扩展后,传统的PHP程序运行速度会提升很多,究其原因,就是OPcache扩展会将代码编译中间结果opcode进行缓存,而php-fpm的运行模式又是每次请求都会重新解释代码,也就是每次请求都会省略了前面的编译过程,所以单位时间内就能节省很多实际运行时间。与之相反,php-cli运行模式下的程序,OPcache对其起到的作用不大,因为php-cli下,程序由于常驻内存而只需要解释一次执行多次。
代码
以下是一个用PHP写的小型编译器。
<?php
class Token
{
public string $type;
public mixed $value;
public function __construct($type, $value = null)
{
$this->type = $type;
$this->value = $value;
}
}
class TokenType
{
const T_INT = 'INT';
const T_PRINT = 'PRINT';
const T_IF = 'IF';
const T_ELSE = 'ELSE';
const T_WHILE = 'WHILE';
const T_FUNCTION = 'FUNCTION';
const T_RETURN = 'RETURN';
const T_IDENTIFIER = 'IDENTIFIER';
const T_NUMBER = 'NUMBER';
const T_PLUS = 'PLUS';
const T_MINUS = 'MINUS';
const T_MULTIPLY = 'MULTIPLY';
const T_DIVIDE = 'DIVIDE';
const T_LPAREN = 'LPAREN';
const T_RPAREN = 'RPAREN';
const T_LBRACE = 'LBRACE';
const T_RBRACE = 'RBRACE';
const T_SEMICOLON = 'SEMICOLON';
const T_COMMA = 'COMMA';
const T_ASSIGN = 'ASSIGN';
const T_LT = 'LT';
const T_GT = 'GT';
const T_EQ = 'EQ';
const T_NEQ = 'NEQ';
const T_LE = 'LE';
const T_GE = 'GE';
const T_AND = 'AND';
const T_OR = 'OR';
const T_NOT = 'NOT';
const T_EOF = 'EOF';
}
class Lexer
{
private string $source;
private int $pos;
private ?string $currentChar;
public function __construct($source)
{
$this->source = $source;
$this->pos = 0;
$this->currentChar = $source[0] ?? null;
}
private function advance(): void
{
$this->pos++;
if ($this->pos < strlen($this->source)) {
$this->currentChar = $this->source[$this->pos];
} else {
$this->currentChar = null;
}
}
private function skipWhitespace(): void
{
while (ctype_space($this->currentChar)) {
$this->advance();
}
}
private function number(): Token
{
$result = '';
while (ctype_digit($this->currentChar)) {
$result .= $this->currentChar;
$this->advance();
}
return new Token(TokenType::T_NUMBER, intval($result));
}
private function identifier(): Token
{
$result = '';
while ((ctype_alpha($this->currentChar) || ctype_digit($this->currentChar) || $this->currentChar == '_')) {
$result .= $this->currentChar;
$this->advance();
}
$keywords = [
'print' => TokenType::T_PRINT,
'if' => TokenType::T_IF,
'else' => TokenType::T_ELSE,
'while' => TokenType::T_WHILE,
'function' => TokenType::T_FUNCTION,
'return' => TokenType::T_RETURN,
];
if (isset($keywords[$result])) {
return new Token($keywords[$result]);
}
return new Token(TokenType::T_IDENTIFIER, $result);
}
public function getNextToken(): Token
{
while ($this->currentChar !== null) {
if (ctype_space($this->currentChar)) {
$this->skipWhitespace();
continue;
}
if (ctype_alpha($this->currentChar) || $this->currentChar == '_') {
return $this->identifier();
}
if (ctype_digit($this->currentChar)) {
return $this->number();
}
if ($this->currentChar == '+') {
$this->advance();
return new Token(TokenType::T_PLUS);
}
if ($this->currentChar == '-') {
$this->advance();
return new Token(TokenType::T_MINUS);
}
if ($this->currentChar == '*') {
$this->advance();
return new Token(TokenType::T_MULTIPLY);
}
if ($this->currentChar == '/') {
$this->advance();
return new Token(TokenType::T_DIVIDE);
}
if ($this->currentChar == '(') {
$this->advance();
return new Token(TokenType::T_LPAREN);
}
if ($this->currentChar == ')') {
$this->advance();
return new Token(TokenType::T_RPAREN);
}
if ($this->currentChar == '{') {
$this->advance();
return new Token(TokenType::T_LBRACE);
}
if ($this->currentChar == '}') {
$this->advance();
return new Token(TokenType::T_RBRACE);
}
if ($this->currentChar == ';') {
$this->advance();
return new Token(TokenType::T_SEMICOLON);
}
if ($this->currentChar == ',') {
$this->advance();
return new Token(TokenType::T_COMMA);
}
if ($this->currentChar == '!') {
$this->advance();
if ($this->currentChar == '=') {
$this->advance();
return new Token(TokenType::T_NEQ);
}
return new Token(TokenType::T_NOT);
}
if ($this->currentChar == '=') {
$this->advance();
if ($this->currentChar == '=') {
$this->advance();
return new Token(TokenType::T_EQ);
}
return new Token(TokenType::T_ASSIGN);
}
if ($this->currentChar == '<') {
$this->advance();
if ($this->currentChar == '=') {
$this->advance();
return new Token(TokenType::T_LE);
}
return new Token(TokenType::T_LT);
}
if ($this->currentChar == '>') {
$this->advance();
if ($this->currentChar == '=') {
$this->advance();
return new Token(TokenType::T_GE);
}
return new Token(TokenType::T_GT);
}
if ($this->currentChar == '&') {
$this->advance();
if ($this->currentChar == '&') {
$this->advance();
return new Token(TokenType::T_AND);
}
}
if ($this->currentChar == '|') {
$this->advance();
if ($this->currentChar == '|') {
$this->advance();
return new Token(TokenType::T_OR);
}
}
throw new Exception("无法识别的字符: " . $this->currentChar);
}
return new Token(TokenType::T_EOF);
}
}
abstract class ASTNode
{
}
class Program extends ASTNode
{
public array $statements;
public function __construct($statements)
{
$this->statements = $statements;
}
}
class Block extends ASTNode implements Statement
{
public array $statements;
public function __construct($statements)
{
$this->statements = $statements;
}
}
interface Statement
{
}
class PrintStatement extends ASTNode implements Statement
{
public Expression $expression;
public function __construct($expression)
{
$this->expression = $expression;
}
}
class IfStatement extends ASTNode implements Statement
{
public Expression $condition;
public Statement $thenBranch;
public Statement $elseBranch;
public function __construct($condition, $thenBranch, $elseBranch = null)
{
$this->condition = $condition;
$this->thenBranch = $thenBranch;
$this->elseBranch = $elseBranch;
}
}
class WhileStatement extends ASTNode implements Statement
{
public Expression $condition;
public Statement $body;
public function __construct($condition, $body)
{
$this->condition = $condition;
$this->body = $body;
}
}
class FunctionDeclaration extends ASTNode implements Statement
{
public string $name;
public array $params;
public Statement $body;
public function __construct($name, $params, $body)
{
$this->name = $name;
$this->params = $params;
$this->body = $body;
}
}
class ReturnStatement extends ASTNode implements Statement
{
public Expression $expression;
public function __construct($expression)
{
$this->expression = $expression;
}
}
class ExpressionStatement extends ASTNode implements Statement
{
public Expression $expression;
public function __construct($expression)
{
$this->expression = $expression;
}
}
interface Expression
{
}
class Assignment extends ASTNode implements Expression
{
public Variable $variable;
public Expression $expression;
public function __construct($variable, $expression)
{
$this->variable = $variable;
$this->expression = $expression;
}
}
class BinaryExpression extends ASTNode implements Expression
{
public Expression $left;
public string $operator;
public Expression $right;
public function __construct($left, $operator, $right)
{
$this->left = $left;
$this->operator = $operator;
$this->right = $right;
}
}
class UnaryExpression extends ASTNode implements Expression
{
public string $operator;
public Expression $expression;
public function __construct($operator, $expression)
{
$this->operator = $operator;
$this->expression = $expression;
}
}
class Literal extends ASTNode implements Expression
{
public mixed $value;
public function __construct($value)
{
$this->value = $value;
}
}
class Variable extends ASTNode implements Expression
{
public string $name;
public function __construct($name)
{
$this->name = $name;
}
}
class FunctionCall extends ASTNode implements Expression
{
public string $name;
public array $arguments;
public function __construct($name, $arguments)
{
$this->name = $name;
$this->arguments = $arguments;
}
}
class Parser
{
private Lexer $lexer;
private Token $currentToken;
public function __construct($lexer)
{
$this->lexer = $lexer;
$this->currentToken = $this->lexer->getNextToken();
}
private function eat(string $tokenType): void
{
if ($this->currentToken->type == $tokenType) {
$this->currentToken = $this->lexer->getNextToken();
} else {
throw new Exception("期望 " . $tokenType . ",但获得 " . $this->currentToken->type);
}
}
public function parse(): Program
{
$statements = [];
while ($this->currentToken->type != TokenType::T_EOF) {
$statements[] = $this->statement();
}
return new Program($statements);
}
private function statement(): Statement
{
return match ($this->currentToken->type) {
TokenType::T_PRINT => $this->printStatement(),
TokenType::T_IF => $this->ifStatement(),
TokenType::T_WHILE => $this->whileStatement(),
TokenType::T_FUNCTION => $this->functionDeclaration(),
TokenType::T_RETURN => $this->returnStatement(),
TokenType::T_LBRACE => $this->block(),
default => $this->expressionStatement(),
};
}
private function block(): Block
{
$this->eat(TokenType::T_LBRACE);
$statements = [];
while ($this->currentToken->type != TokenType::T_RBRACE) {
$statements[] = $this->statement();
}
$this->eat(TokenType::T_RBRACE);
return new Block($statements);
}
private function printStatement(): PrintStatement
{
$this->eat(TokenType::T_PRINT);
$this->eat(TokenType::T_LPAREN);
$expr = $this->expression();
$this->eat(TokenType::T_RPAREN);
$this->eat(TokenType::T_SEMICOLON);
return new PrintStatement($expr);
}
private function ifStatement(): IfStatement
{
$this->eat(TokenType::T_IF);
$this->eat(TokenType::T_LPAREN);
$condition = $this->expression();
$this->eat(TokenType::T_RPAREN);
$thenBranch = $this->statement();
$elseBranch = null;
if ($this->currentToken->type == TokenType::T_ELSE) {
$this->eat(TokenType::T_ELSE);
$elseBranch = $this->statement();
}
return new IfStatement($condition, $thenBranch, $elseBranch);
}
private function whileStatement(): WhileStatement
{
$this->eat(TokenType::T_WHILE);
$this->eat(TokenType::T_LPAREN);
$condition = $this->expression();
$this->eat(TokenType::T_RPAREN);
$body = $this->statement();
return new WhileStatement($condition, $body);
}
private function functionDeclaration(): FunctionDeclaration
{
$this->eat(TokenType::T_FUNCTION);
$name = $this->currentToken->value;
$this->eat(TokenType::T_IDENTIFIER);
$this->eat(TokenType::T_LPAREN);
$params = [];
if ($this->currentToken->type != TokenType::T_RPAREN) {
$params[] = $this->currentToken->value;
$this->eat(TokenType::T_IDENTIFIER);
while ($this->currentToken->type == TokenType::T_COMMA) {
$this->eat(TokenType::T_COMMA);
$params[] = $this->currentToken->value;
$this->eat(TokenType::T_IDENTIFIER);
}
}
$this->eat(TokenType::T_RPAREN);
$body = $this->block();
return new FunctionDeclaration($name, $params, $body);
}
private function returnStatement(): ReturnStatement
{
$this->eat(TokenType::T_RETURN);
$expr = null;
if ($this->currentToken->type != TokenType::T_SEMICOLON) {
$expr = $this->expression();
}
$this->eat(TokenType::T_SEMICOLON);
return new ReturnStatement($expr);
}
private function expressionStatement(): ExpressionStatement
{
$expr = $this->expression();
$this->eat(TokenType::T_SEMICOLON);
return new ExpressionStatement($expr);
}
private function expression(): Expression
{
return $this->assignment();
}
private function assignment(): Expression
{
$expr = $this->logicalOr();
if ($this->currentToken->type == TokenType::T_ASSIGN) {
if (!($expr instanceof Variable)) {
throw new Exception("赋值目标无效");
}
$this->eat(TokenType::T_ASSIGN);
$value = $this->assignment();
return new Assignment($expr, $value);
}
return $expr;
}
private function logicalOr(): Expression
{
$expr = $this->logicalAnd();
while ($this->currentToken->type == TokenType::T_OR) {
$operator = $this->currentToken->type;
$this->eat(TokenType::T_OR);
$right = $this->logicalAnd();
$expr = new BinaryExpression($expr, $operator, $right);
}
return $expr;
}
private function logicalAnd(): Expression
{
$expr = $this->equality();
while ($this->currentToken->type == TokenType::T_AND) {
$operator = $this->currentToken->type;
$this->eat(TokenType::T_AND);
$right = $this->equality();
$expr = new BinaryExpression($expr, $operator, $right);
}
return $expr;
}
private function equality(): Expression
{
$expr = $this->comparison();
while ($this->currentToken->type == TokenType::T_EQ || $this->currentToken->type == TokenType::T_NEQ) {
$operator = $this->currentToken->type;
if ($operator == TokenType::T_EQ) {
$this->eat(TokenType::T_EQ);
} else {
$this->eat(TokenType::T_NEQ);
}
$right = $this->comparison();
$expr = new BinaryExpression($expr, $operator, $right);
}
return $expr;
}
private function comparison(): Expression
{
$expr = $this->addition();
while (in_array($this->currentToken->type, [TokenType::T_LT, TokenType::T_GT, TokenType::T_LE, TokenType::T_GE])) {
$operator = $this->currentToken->type;
$this->eat($operator);
$right = $this->addition();
$expr = new BinaryExpression($expr, $operator, $right);
}
return $expr;
}
private function addition(): Expression
{
$expr = $this->multiplication();
while ($this->currentToken->type == TokenType::T_PLUS || $this->currentToken->type == TokenType::T_MINUS) {
$operator = $this->currentToken->type;
if ($operator == TokenType::T_PLUS) {
$this->eat(TokenType::T_PLUS);
} else {
$this->eat(TokenType::T_MINUS);
}
$right = $this->multiplication();
$expr = new BinaryExpression($expr, $operator, $right);
}
return $expr;
}
private function multiplication(): Expression
{
$expr = $this->unary();
while ($this->currentToken->type == TokenType::T_MULTIPLY || $this->currentToken->type == TokenType::T_DIVIDE) {
$operator = $this->currentToken->type;
if ($operator == TokenType::T_MULTIPLY) {
$this->eat(TokenType::T_MULTIPLY);
} else {
$this->eat(TokenType::T_DIVIDE);
}
$right = $this->unary();
$expr = new BinaryExpression($expr, $operator, $right);
}
return $expr;
}
private function unary(): Expression
{
if ($this->currentToken->type == TokenType::T_NOT || $this->currentToken->type == TokenType::T_MINUS) {
$operator = $this->currentToken->type;
$this->eat($operator);
$expr = $this->unary();
return new UnaryExpression($operator, $expr);
}
return $this->primary();
}
private function primary(): Expression
{
$token = $this->currentToken;
if ($token->type == TokenType::T_NUMBER) {
$this->eat(TokenType::T_NUMBER);
return new Literal($token->value);
}
if ($token->type == TokenType::T_IDENTIFIER) {
$this->eat(TokenType::T_IDENTIFIER);
if ($this->currentToken->type == TokenType::T_LPAREN) {
$this->eat(TokenType::T_LPAREN);
$args = [];
if ($this->currentToken->type != TokenType::T_RPAREN) {
$args[] = $this->expression();
while ($this->currentToken->type == TokenType::T_COMMA) {
$this->eat(TokenType::T_COMMA);
$args[] = $this->expression();
}
}
$this->eat(TokenType::T_RPAREN);
return new FunctionCall($token->value, $args);
}
return new Variable($token->value);
}
if ($token->type == TokenType::T_LPAREN) {
$this->eat(TokenType::T_LPAREN);
$expr = $this->expression();
$this->eat(TokenType::T_RPAREN);
return $expr;
}
throw new Exception("无法识别的 token: " . $token->type);
}
}
class OpCode
{
const ICONST = 'ICONST';
const LOAD = 'LOAD';
const STORE = 'STORE';
const PRINT = 'PRINT';
const ADD = 'ADD';
const SUB = 'SUB';
const MUL = 'MUL';
const DIV = 'DIV';
const LT = 'LT';
const GT = 'GT';
const EQ = 'EQ';
const NE = 'NE';
const LE = 'LE';
const GE = 'GE';
const AND = 'AND';
const OR = 'OR';
const NOT = 'NOT';
const JMP = 'JMP';
const JMPF = 'JMPF';
const CALL = 'CALL';
const RET = 'RET';
const POP = 'POP';
}
class CodeGenerator
{
private array $instructions = [];
private array $functions = [];
public function generate($node): array
{
if ($node instanceof Program) {
$funcDecls = [];
$mainStmts = [];
foreach ($node->statements as $stmt) {
if ($stmt instanceof FunctionDeclaration) {
$funcDecls[] = $stmt;
} else {
$mainStmts[] = $stmt;
}
}
foreach ($mainStmts as $stmt) {
$this->genStatement($stmt);
}
$jumpPos = $this->emit(OpCode::JMP, 0);
$funcStart = count($this->instructions);
foreach ($funcDecls as $func) {
$funcName = $func->name;
$entryPoint = count($this->instructions);
$this->functions[$funcName] = ['params' => $func->params, 'entry' => $entryPoint];
$this->genStatement($func->body);
$this->emit(OpCode::RET);
}
$this->patch($jumpPos, count($this->instructions));
return $this->instructions;
} else {
throw new Exception("无效的 AST 节点");
}
}
private function genStatement($node): void
{
if ($node instanceof PrintStatement) {
$this->genExpression($node->expression);
$this->emit(OpCode::PRINT);
} elseif ($node instanceof ExpressionStatement) {
$this->genExpression($node->expression);
$this->emit(OpCode::POP);
} elseif ($node instanceof Assignment) {
$this->genExpression($node->expression);
$this->emit(OpCode::STORE, $node->variable->name);
} elseif ($node instanceof IfStatement) {
$this->genExpression($node->condition);
$jmpFalsePos = $this->emit(OpCode::JMPF, 0);
$this->genStatement($node->thenBranch);
if ($node->elseBranch !== null) {
$jmpEndPos = $this->emit(OpCode::JMP, 0);
$this->patch($jmpFalsePos, count($this->instructions));
$this->genStatement($node->elseBranch);
$this->patch($jmpEndPos, count($this->instructions));
} else {
$this->patch($jmpFalsePos, count($this->instructions));
}
} elseif ($node instanceof WhileStatement) {
$startPos = count($this->instructions);
$this->genExpression($node->condition);
$jmpFalsePos = $this->emit(OpCode::JMPF, 0);
$this->genStatement($node->body);
$this->emit(OpCode::JMP, $startPos);
$this->patch($jmpFalsePos, count($this->instructions));
} elseif ($node instanceof Block) {
foreach ($node->statements as $stmt) {
$this->genStatement($stmt);
}
} elseif ($node instanceof ReturnStatement) {
if ($node->expression !== null) {
$this->genExpression($node->expression);
} else {
$this->emit(OpCode::ICONST, 0);
}
$this->emit(OpCode::RET);
} else {
throw new Exception("未知的语句类型");
}
}
private function genExpression($node): void
{
if ($node instanceof Literal) {
$this->emit(OpCode::ICONST, $node->value);
} elseif ($node instanceof Variable) {
$this->emit(OpCode::LOAD, $node->name);
} elseif ($node instanceof Assignment) {
$this->genExpression($node->expression);
$this->emit(OpCode::STORE, $node->variable->name);
} elseif ($node instanceof BinaryExpression) {
$this->genExpression($node->left);
$this->genExpression($node->right);
switch ($node->operator) {
case TokenType::T_PLUS:
$this->emit(OpCode::ADD);
break;
case TokenType::T_MINUS:
$this->emit(OpCode::SUB);
break;
case TokenType::T_MULTIPLY:
$this->emit(OpCode::MUL);
break;
case TokenType::T_DIVIDE:
$this->emit(OpCode::DIV);
break;
case TokenType::T_LT:
$this->emit(OpCode::LT);
break;
case TokenType::T_GT:
$this->emit(OpCode::GT);
break;
case TokenType::T_EQ:
$this->emit(OpCode::EQ);
break;
case TokenType::T_NEQ:
$this->emit(OpCode::NE);
break;
case TokenType::T_LE:
$this->emit(OpCode::LE);
break;
case TokenType::T_GE:
$this->emit(OpCode::GE);
break;
case TokenType::T_AND:
$this->emit(OpCode::AND);
break;
case TokenType::T_OR:
$this->emit(OpCode::OR);
break;
default:
throw new Exception("未知的二元运算符: " . $node->operator);
}
} elseif ($node instanceof UnaryExpression) {
if ($node->operator == TokenType::T_MINUS) {
$this->emit(OpCode::ICONST, 0);
$this->genExpression($node->expression);
$this->emit(OpCode::SUB);
} elseif ($node->operator == TokenType::T_NOT) {
$this->genExpression($node->expression);
$this->emit(OpCode::NOT);
} else {
throw new Exception("未知的一元运算符: " . $node->operator);
}
} elseif ($node instanceof FunctionCall) {
foreach ($node->arguments as $arg) {
$this->genExpression($arg);
}
$this->emit(OpCode::CALL, ['name' => $node->name, 'argc' => count($node->arguments)]);
} else {
throw new Exception("未知的表达式类型");
}
}
private function emit($opcode, $operand = null): int
{
$instr = ['op' => $opcode];
if ($operand !== null) {
$instr['operand'] = $operand;
}
$this->instructions[] = $instr;
return count($this->instructions) - 1;
}
private function patch($pos, $target): void
{
$this->instructions[$pos]['operand'] = $target;
}
public function getFunctions(): array
{
return $this->functions;
}
}
class VirtualMachine
{
private array $instructions;
private array $functions;
private int $ip;
private array $stack;
private array $globals;
private array $callStack;
public function __construct($instructions, $functions)
{
$this->instructions = $instructions;
$this->functions = $functions;
$this->ip = 0;
$this->stack = [];
$this->globals = [];
$this->callStack = [];
}
public function run()
{
while ($this->ip < count($this->instructions)) {
$instr = $this->instructions[$this->ip];
switch ($instr['op']) {
case OpCode::ICONST:
$this->stack[] = $instr['operand'];
$this->ip++;
break;
case OpCode::LOAD:
$var = $instr['operand'];
$this->stack[] = $this->globals[$var] ?? 0;
$this->ip++;
break;
case OpCode::STORE:
$var = $instr['operand'];
$value = array_pop($this->stack);
$this->globals[$var] = $value;
$this->ip++;
break;
case OpCode::PRINT:
$value = array_pop($this->stack);
echo $value . "\n";
$this->ip++;
break;
case OpCode::ADD:
$b = array_pop($this->stack);
$a = array_pop($this->stack);
$this->stack[] = $a + $b;
$this->ip++;
break;
case OpCode::SUB:
$b = array_pop($this->stack);
$a = array_pop($this->stack);
$this->stack[] = $a - $b;
$this->ip++;
break;
case OpCode::MUL:
$b = array_pop($this->stack);
$a = array_pop($this->stack);
$this->stack[] = $a * $b;
$this->ip++;
break;
case OpCode::DIV:
$b = array_pop($this->stack);
$a = array_pop($this->stack);
$this->stack[] = intval($a / $b);
$this->ip++;
break;
case OpCode::LT:
$b = array_pop($this->stack);
$a = array_pop($this->stack);
$this->stack[] = ($a < $b) ? 1 : 0;
$this->ip++;
break;
case OpCode::GT:
$b = array_pop($this->stack);
$a = array_pop($this->stack);
$this->stack[] = ($a > $b) ? 1 : 0;
$this->ip++;
break;
case OpCode::EQ:
$b = array_pop($this->stack);
$a = array_pop($this->stack);
$this->stack[] = ($a == $b) ? 1 : 0;
$this->ip++;
break;
case OpCode::NE:
$b = array_pop($this->stack);
$a = array_pop($this->stack);
$this->stack[] = ($a != $b) ? 1 : 0;
$this->ip++;
break;
case OpCode::LE:
$b = array_pop($this->stack);
$a = array_pop($this->stack);
$this->stack[] = ($a <= $b) ? 1 : 0;
$this->ip++;
break;
case OpCode::GE:
$b = array_pop($this->stack);
$a = array_pop($this->stack);
$this->stack[] = ($a >= $b) ? 1 : 0;
$this->ip++;
break;
case OpCode::AND:
$b = array_pop($this->stack);
$a = array_pop($this->stack);
$this->stack[] = ($a && $b) ? 1 : 0;
$this->ip++;
break;
case OpCode::OR:
$b = array_pop($this->stack);
$a = array_pop($this->stack);
$this->stack[] = ($a || $b) ? 1 : 0;
$this->ip++;
break;
case OpCode::NOT:
$a = array_pop($this->stack);
$this->stack[] = (!$a) ? 1 : 0;
$this->ip++;
break;
case OpCode::JMP:
$this->ip = $instr['operand'];
break;
case OpCode::JMPF:
$cond = array_pop($this->stack);
if (!$cond) {
$this->ip = $instr['operand'];
} else {
$this->ip++;
}
break;
case OpCode::CALL:
$funcInfo = $instr['operand'];
$funcName = $funcInfo['name'];
$argc = $funcInfo['argc'];
if (!isset($this->functions[$funcName])) {
throw new Exception("未定义函数: " . $funcName);
}
$fn = $this->functions[$funcName];
$this->callStack[] = [$this->ip + 1, $this->globals];
$args = [];
for ($i = 0; $i < $argc; $i++) {
array_unshift($args, array_pop($this->stack));
}
$this->globals = [];
$params = $fn['params'];
for ($i = 0; $i < count($params); $i++) {
$this->globals[$params[$i]] = $args[$i] ?? 0;
}
$this->ip = $fn['entry'];
break;
case OpCode::RET:
$retValue = array_pop($this->stack);
if (empty($this->callStack)) {
return $retValue;
}
list($this->ip, $prevGlobals) = array_pop($this->callStack);
$this->globals = $prevGlobals;
$this->stack[] = $retValue;
break;
case OpCode::POP:
array_pop($this->stack);
$this->ip++;
break;
default:
throw new Exception("未知的操作码: " . $instr['op']);
}
}
}
}
// 主程序部分
$source = <<<'EOT'
print(1 + 2 * 3);
print(1 + 2 * (3 + 4));
a = 10;
print(2 * (a + 10));
while(a > 0) {
print(a);
if (a == 1) {
a = a - 11;
} else {
a = a - 1;
}
}
print(a);
function factorial(n) {
if(n == 0) {
return 1;
} else {
return n * factorial(n - 1);
}
}
print(factorial(5));
function sum(a, b) {
print(666666);
return a + b;
}
b = 10;
print(sum(10, b));
EOT;
try {
$lexer = new Lexer($source);
$parser = new Parser($lexer);
$ast = $parser->parse();
$codegen = new CodeGenerator();
$instructions = $codegen->generate($ast);
$functions = $codegen->getFunctions();
echo json_encode($instructions), "\n\n";
echo json_encode($functions), "\n\n";
$vm = new VirtualMachine($instructions, $functions);
$vm->run();
} catch (Exception $e) {
echo "Error: " . $e->getMessage() . "\n";
}
虽然代码很多,但我们只需要将目光集中到// 主程序以下部分,这么多代码的目的就是运行$source中的代码。程序主要分成四个部分:Lexer、Parser、CodeGenerator和VirtualMachine。如果以Java为例,Lexer、Parser、CodeGenerator部分就是javac做的,VirtualMachine就是java对应的部分。Java程序可以预先将代码编译成字节码,再单独运行字节码。而PHP在明面上就没分得这么清晰,大部分PHPer可能只知道PHP的热更新很方便,不知道背后的解释器做了多少工作,可能以为解释器只是傻傻的逐行解释执行。其实PHP的编译过程跟Java大差不差,也可以生成字节码同一层次的opcode,opcode跟字节码当然是有点差异的,但为了易于理解,可以当成是同一类型的东西。既然如此,PHP的opcode当然也可以像字节码一样单独执行,Opcache就因此而生。可惜,则于历史原因,PHP的opcode并没有规范,所以官方实现无法单独生成opcode经由ZendVM直接执行,内部社区其实也有相关的讨论如 https://externals.io/message/111965,还可以在 https://externals.io 查阅更多相关信息。
通过 Chrome DevTools Protocol 协议控制浏览器
之前写过Selenium是怎么指挥浏览器运行的,其中提到过通过CDP(Chrome DevTools Protocol)协议可以直接绕过浏览器驱动来控制浏览器。CDP本质上就是通过WebSocket协议传输JSON格式的命令。
使用CDP时,无需浏览器驱动,但依然依赖浏览器。因此,控制浏览器的第一步就是启动浏览器。这里我们使用ps ajx命令结果是否包含Chrome、headless两个关键词来判断是否已启动CDP服务,也就是代码中的chromeHeadlessRunning函数:
func chromeHeadlessRunning() (bool, error) {
cmd := exec.Command("ps", "ajx")
output, err := cmd.Output()
if err != nil {
return false, err
}
scanner := bufio.NewScanner(strings.NewReader(string(output)))
for scanner.Scan() {
line := scanner.Text()
if strings.Contains(line, "Chrome") &&
strings.Contains(line, "headless") &&
!strings.Contains(line, "grep") {
return true, nil
}
}
return false, nil
}
怎么判断启动CDP服务的命令确实拉起了CDP?CDP协议使用常用的TCP/IP协议栈,只需要发起连接多次几次,成功建立连接视为服务成功启动。
func waitForCDP(port string, timeout time.Duration) bool {
deadline := time.Now().Add(timeout)
for time.Now().Before(deadline) {
conn, err := net.DialTimeout("tcp", port, time.Second)
if err == nil {
conn.Close()
return true
}
time.Sleep(200 * time.Millisecond)
}
return false
}
到这一步,基本的要求都已满足。那么通过HTTP的PUT方法新建一个页面,并获取对应的webSocketDebuggerUrl用于后续交互。
func getDebuggerInfo() interface{} {
httpClient := http.Client{}
req, err := http.NewRequest(http.MethodPut, debuggerBaseUrl+"/json/new", nil)
isFatal(err)
res, err := httpClient.Do(req)
isFatal(err)
defer res.Body.Close()
bodyBytes, err := io.ReadAll(res.Body)
isFatal(err)
var i interface{}
err = json.Unmarshal(bodyBytes, &i)
isFatal(err)
return i
}
现在就可以通过webSocketDebuggerUrl建立WebSocket连接控制浏览器了。以获取https://baidu.com网页标题为例:
Selenium 是怎么指挥浏览器运行的
写过爬虫或者做自动化测试的相信对Selenium不会陌生,但Selenium
官方只提供少数几种语言的库,使用其它“小众”语言的只能眼馋。既然如此,那就自己琢磨一下能不能搞个类似的吧,毕竟大家都是图灵完备的语言,除了少数一些领域实在没办法或者几乎不可能做到之外,其它的都大差不差。
“小小”的语言能唤起浏览器,有经验的大家都知道还有个前提就是下载浏览器驱动。以Chrome为例,Selenium启动chromedriver的HTTP服务,自身通过HTTP客户端与其通信;至于chromedriver和Chrome之间则通过CDP(Chrome DevTools Protocol)通信,通俗来说,CDP协议就是基于WebSocket的JSON指令协议,例如:
{
"method": "Page.navigate",
"params": {
"url": "https://example.com"
}
}
在chromedriver启动浏览器时,会自动为浏览器启动这个服务接收CDP协议,进而通过这些命令来控制它。相信喜欢思考的人已经发现了,我们可以直接跳过chromedriver这一步,自己启动Chrome与其通信,这样性能更好。像puppeteer等工具就是直接使用CDP,不使用浏览器驱动的。当然本文是浅浅探索一下Selenium的原理,这些就不做展开。
了解原理就会豁然开朗,动起手吧。
<?php
class SimulateSelenium
{
public static string $webdriverURL = 'http://localhost:9515';
public static string $findDriver = "ps ajx | grep chromedriver | grep -v grep";
public static function get($url = '')
{
$pid = pcntl_fork();
if ($pid < 0) {
exit("fork error");
} else if ($pid == 0) {
echo "starting chromedriver...\n";
if (!shell_exec(self::$findDriver)) {
pcntl_exec("/usr/bin/env", ["chromedriver", "--port=9515", "&"], ["PATH" => "/Users/wu/Bin"]);
}
} else {
$timeout = 10;
while ($timeout > 0) {
if (shell_exec(self::$findDriver)) {
break;
}
echo "waiting for chromedriver...\n";
sleep(1);
$timeout--;
}
$session = self::request('POST', self::$webdriverURL . "/session", [
'capabilities' => [
'alwaysMatch' => [
'browserName' => 'chrome',
],
]
]);
if (!isset($session['value']['sessionId'])) {
echo "无法创建浏览器 session\n";
exit(1);
}
$sessionId = $session['value']['sessionId'];
self::request('POST', self::$webdriverURL . "/session/$sessionId/url", [
'url' => $url,
]);
$title = self::request('GET', self::$webdriverURL . "/session/$sessionId/title");
echo "页面标题: " . $title['value'] . "\n";
self::request('DELETE', self::$webdriverURL . "/session/$sessionId");
}
}
private static function request($method, $url, $data = null)
{
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, $method);
if ($data !== null) {
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($data));
curl_setopt($ch, CURLOPT_HTTPHEADER, ['Content-Type: application/json']);
}
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$res = curl_exec($ch);
curl_close($ch);
return json_decode($res, true);
}
}
SimulateSelenium::get('https://baidu.com');
效果如下图:
使用 frp 将本地 web 服务暴露到公网
使用 frp 的前提条件是有公网IP的服务器,毕竟标题所讲的就是内网穿透。内网穿透,要么买服务,要么就自己搭,frp就是一款高性能的反向代理应用,专注于内网穿透,主打一个免安装,Go语言写的嘛,交叉静态编译就是香。
像微信以及一些服务,需要提供公网HTTP地址甚至必须是HTTPS服务才能申请或测试,频繁同步代码到服务器也不方便,而且如果是新的服务器还得搭环境,那还是做个内网穿透服务到本地比较舒服,非常适合个人做测试。
本文使用的是frp 0.61.2,下载即可使用,解压后只有以下文件:
frpc
frpc.toml
frps
frps.toml
LICENSE
用户只需要关注frps.toml和frpc.toml,分别是服务端和客户端的配置。
服务端frps.toml的bindPort为穿透服务的端口,即frps和frpc通信的端口,而vhostHTTPPort和vhostHTTPSPort为服务器对外提供HTTP和HTTPS服务的端口。
而客户端frpc.toml的serverAddr和serverPort显然就是客户端和服务端通信的地址和端口,例如我们通过example.com的8080端口为客户端提供穿透服务,则serverAddr为example.com,serverPort为8080;至于localIP="127.0.0.1"、localPort=80、customDomains=["example.com"]就是需要暴露到公网的本地服务地址和端口以及自定义域名。
HTTP 服务
服务端frps.toml配置:
bindPort=8080
vhostHTTPPort=8080
客户端frpc.toml配置:
serverAddr="example.com"
serverPort=8080
[[proxies]]
name="web"
type="http"
localIP="127.0.0.1"
localPort=80
customDomains=["example.com"]
HTTPS 服务
vhostHTTPSPort为服务器对外提供HTTPS服务的端口。
服务端frps.toml配置:
bindPort=8080
vhostHTTPSPort=443
客户端frpc.toml配置:
serverAddr="example.com"
serverPort=8080
[[proxies]]
name="web"
type="https"
customDomains=["example.com"]
[proxies.plugin]
type="https2http"
localAddr="127.0.0.1:80"
crtPath="./example.com_public.crt"
keyPath="./example.com.key"
hostHeaderRewrite="127.0.0.1"
关键说明:
[[proxies]]的type="https"表示该转发是https类型;[proxies.plugin]的type="https2http"是frp将HTTP服务转换为HTTPS服务的扩展;[proxies.plugin]的localAddr为本地HTTPS服务地址;[proxies.plugin]的keyPath为TLS密钥文件路径;[proxies.plugin]的crtPath为TLS证书文件路径;[proxies.plugin]的hostHeaderRewrite改写请求报文的Host;
使用 debian 12 定制自己的操作系统镜像
从一个小型编译器一窥编译原理的本质
编译器可以粗略地分为几个简单的部分:词法分析器、语法分析器、代码生成器。其中语义分析器、代码优化器这些不影响本文示例功能。另外,本文的编译器生成的是字节码,因此还需要一个虚拟机来执行。
Lexer 词法分析器
Lexer的功能是将代码串不同的符号进行标记分组,例如(3 + 5) * 2可以拆分为不同的token,分别是(、3、+、5、)、*、2,包含五个分类,有左括号、右括号、加号、乘号以及整数,其中的空白符号需要忽略。
class Lexer
{
private $input;
private $pos = 0;
private $currentChar;
public function __construct($input)
{
$this->input = $input;
$this->currentChar = $input[0] ?? null;
}
private function advance()
{
$this->pos++;
$this->currentChar = $this->input[$this->pos] ?? null;
}
private function skipWhitespace()
{
while ($this->currentChar !== null && ctype_space($this->currentChar)) {
$this->advance();
}
}
private function integer()
{
$result = '';
while ($this->currentChar !== null && ctype_digit($this->currentChar)) {
$result .= $this->currentChar;
$this->advance();
}
return (int)$result;
}
private function identifier()
{
$result = '';
while ($this->currentChar !== null && (ctype_alnum($this->currentChar) || $this->currentChar === '_')) {
$result .= $this->currentChar;
$this->advance();
}
return $result;
}
public function getNextToken()
{
while ($this->currentChar !== null) {
// 忽略空白符
if (ctype_space($this->currentChar)) {
$this->skipWhitespace();
continue;
}
// 当前字符为整型时,扫描后续部分的整型字符
if (ctype_digit($this->currentChar)) {
return ['type' => 'INTEGER', 'value' => $this->integer()];
}
// 当前字符为字母时,扫描后续部分的字母或数字字符
if (ctype_alpha($this->currentChar)) {
$id = $this->identifier();
// 如果扫描到的 token 为 print,则将其标记为关键词 print
if (strtoupper($id) === 'PRINT') {
return ['type' => 'PRINT', 'value' => $id];
}
return ['type' => 'ID', 'value' => $id];
}
// 普通的符号
switch ($this->currentChar) {
case '=':
$this->advance();
return ['type' => 'ASSIGN', 'value' => '='];
case '+':
$this->advance();
return ['type' => 'PLUS', 'value' => '+'];
case '-':
$this->advance();
return ['type' => 'MINUS', 'value' => '-'];
case '*':
$this->advance();
return ['type' => 'MUL', 'value' => '*'];
case '/':
$this->advance();
return ['type' => 'DIV', 'value' => '/'];
case ';':
$this->advance();
return ['type' => 'SEMI', 'value' => ';'];
case '(':
$this->advance();
return ['type' => 'LPAREN', 'value' => '('];
case ')':
$this->advance();
return ['type' => 'RPAREN', 'value' => ')'];
default:
throw new Exception("Invalid character: " . $this->currentChar);
}
}
return ['type' => 'EOF', 'value' => null];
}
}
Parser 语法分析器
Parser遍历token,生成AST。
利用 GitHub Actions 编译 PHP
使用GitHub Actions编译方便不使用Docker等工具还要定制PHP版本的用户,降低了部署成本,只需要下载编译后的压缩包即可使用(前提是部署的环境跟编译的环境保持一致,也就是运行与yaml文件的dependence相同的命令解决依赖问题)。
用于公共存储库的GitHub托管的标准运行器。对于公共存储库,使用下表所示工作流标签的作业可在具有关联规范的虚拟机上运行。可以在公共存储库上免费且无限制地使用这些运行器。
| 虚拟机 | 处理器 (CPU) | 内存 (RAM) | 存储 (SSD) | 体系结构 | 工作流标签 |
|---|---|---|---|---|---|
| Linux | 4 | 16 GB | 14 GB | x64 | ubuntu-latest、ubuntu-24.04、ubuntu-22.04、ubuntu-20.04 |
| Windows | 4 | 16 GB | 14 GB | x64 | windows-latest、windows-2025[公共预览版]、windows-2022, windows-2019 |
| Linux [公共预览版] | 4 | 16 GB | 14 GB | arm64 | ubuntu-24.04-arm,ubuntu-22.04-arm |
| macOS | 4 | 14 GB | 14 GB | Intel | macos-13 |
| macOS | 3 (M1) | 7 GB | 14 GB | arm64 | macos-latest、macos-14、macos-15 [公共预览版] |
以ubuntu-22.04-arm编译PHP-8.2.6源码为例,.github/workflows/myPHP-8.2.6-arm.yaml的配置根据压根自行添加运行步骤。
{% raw %}
name: myPHP-8.2.6-arm
on:
push:
branches: ["myPHP-8.2.6"] # 仅在 myPHP-8.2.6 分支 push 时触发
pull_request:
branches: ["myPHP-8.2.6"] # 仅在 myPHP-8.2.6 分支 pull_request 时触发
jobs:
build:
runs-on: ubuntu-22.04-arm # 使用 ubuntu-22.04 系统
steps: # 步骤
- name: env # 预设环境变量
run: echo "WORKING_DIR=$PWD" >> $GITHUB_ENV && echo "PREFIX_DIR=$PWD/output" >> $GITHUB_ENV && echo "INI_DIR=$PWD/output/ini" >> $GITHUB_ENV && echo "EXT_DIR=$PWD/'output/bin/php-config --extension-dir'" >> $GITHUB_ENV && TMP_ZIP_DIR=`realpath $PWD/..` && echo "ZIP_DIR=$TMP_ZIP_DIR" >> $GITHUB_ENV && ZIP_FILE="php-8.2.6-ubuntu-22.04-arm64-`date '+%Y-%m-%d.%H-%M-%S'`.zip" && echo "ZIP_FILE=$ZIP_FILE" >> $GITHUB_ENV
- name: apt update # 更新 apt
run: sudo apt update -y
- name: dependence # 安装依赖,主要是扩展的依赖
run: sudo apt install -y pkg-config build-essential autoconf bison re2c libxml2-dev libsqlite3-dev openssl libcurl4 libbz2-dev libavif-dev libfreetype6-dev libfreetype6 libgmp3-dev libwebp-dev libzip-dev libjpeg-dev libsystemd-dev libcurl-ocaml-dev libonig-dev libedit-dev libsnmp-dev libxslt1-dev libzip-dev libpq-dev libpq5
- name: checkout # 检出代码,"actions/checkout@v4" 是 GitHub 提供的一个 action,用于检出代码
uses: actions/checkout@v4
with:
ref: myPHP-8.2.6 # 检出 myPHP-8.2.6 分支
- name: buildconf # 构建 configure
run: ./buildconf -f
- name: configure # 编译配置,添加了较为常见的扩展
run: ./configure --prefix=${{ env.PREFIX_DIR }} --with-config-file-path=${{ env.INI_DIR }} --enable-embed --enable-fpm --enable-phpdbg --enable-debug --enable-bcmath --enable-calendar --enable-exif --enable-gd --enable-intl --enable-mbstring --enable-pcntl --enable-shmop --enable-soap --enable-sockets --enable-sysvmsg --enable-sysvshm --enable-mysqlnd --enable-phar --enable-filter --enable-iconv --with-fpm-user=www-data --with-fpm-group=www-data --with-fpm-systemd --with-openssl --with-zlib --with-bz2 --with-curl --with-ffi --with-avif --with-webp --with-jpeg --with-freetype --with-gettext --with-gmp --with-mysqli --with-pdo-mysql --with-pdo-pgsql --with-pgsql --with-libedit --with-readline --with-snmp --with-xsl --with-zip --with-pear --with-openssl-dir=/usr/include/openssl
- name: make # 编译
run: make
- name: make install # 安装
run: make install
- name: mkdir # 创建 php.ini 目录
run: mkdir -p ${{ env.INI_DIR }}
- name: cp # 复制 php.ini-production 到 php.ini
run: cp ${{ env.WORKING_DIR }}/php.ini-production ${{ env.INI_DIR }}/php.ini
- name: add ini # 添加 extension_dir 到 php.ini
run: echo "extension_dir=${{ env.EXT_DIR }}" >> ${{ env.INI_DIR }}/php.ini
- name: zip # 已经编译完了,可以修改工作目录生成压缩包
run: cd .. && zip -r ${{ env.ZIP_FILE }} ./php-src
- name: upload # 上传 zip
uses: actions/upload-artifact@v4
with:
name: ${{ env.ZIP_FILE }}
path: ${{ env.ZIP_DIR }}/${{ env.ZIP_FILE }}
retention-days: 7
{% endraw %}
链式调用 PHP 标准函数
PHP内置函数太多,记不住怎么办?尤其PHP
一直被人垢病函数名不统一,这就导致更不容易记忆了。这时候是不是在想,要是我随便定义一个变量,就能列出可以对其进行操作的函数就好了,虽然列出来也不一定知道用哪个,但起码一般情况下可以根据函数名猜到哪个才是要用的函数。例如$a = "Hello world";,我在IDE上输入$a->,IDE就能将可用函数显示出来。简单,这不就是面向对象吗?那就动手吧。
首先定义一个函数,用于将基础类型封装成类,以字符串为例,Str类有一个静态函数wrap接收一个字符串参数,返回Str的实例,并且将$value参数赋给$value属性,那么wrap的返回值就是对象,可以以->符号来调用属于Str的方法了。
<?php
class Str
{
private mixed $value;
public static function wrap(string $value): Str
{
return new self($value);
}
public function __construct(string $value)
{
$this->value = $value;
}
}
这时候就碰到一个问题,字符串操作函数那么多,难道我们要一个个封装进类里面?这种方法也太落后且难维护了吧。幸好PHP有个魔术方法__call,思路打开,那么我们是不是可以通过__call来调用所有函数?实践起来吧。
public function __call($callable, $args)
{
$this->value = $callable(...$args);
return $this;
}
但是现在还有个问题,就是例如封装了一个字符串"foo",我想对它调用strlen函数,显然Str::wrap("foo")->strlen()是行不通的,因为没有参数,默认将封闭的值传进去?在调用strlen时没问题,但是并非所有函数都将操作参数放在第一位,所以需要让__call方法知道我们的参数位置才行。方法是定义一个唯一值来标记封装值所在位置,这里我们使用uniqid函数,虽然没有一些uuid库那么标准,但在这里也够用了。然后对__call方法进行一定调整,调整后的代码如下:
<?php
if (!defined('wrapped_placeholder')) {
define('wrapped_placeholder', 'wrapped-placeholder-' . uniqid());
}
class Str
{
private mixed $value;
public static function wrap(string $value): Str
{
return new self($value);
}
public function __construct(string $value)
{
$this->value = $value;
}
public function __call($callable, $args)
{
foreach ($args as &$arg) {
if ($arg === wrapped_placeholder) {
$arg = $this->value;
}
}
$this->value = $callable(...$args);
return $this;
}
}
现在基本雏形已经出来了。使用方法如下:
动手写个简易的静态博客生成器
github带火了类似jekyll的静态博客生成器,可以将markdown文件转换为html文件,然后发布到网站上,对喜欢markdown简洁的人来说,简直太棒了,尤其现在大量的网站可以免费托管这种小型的博客,当然,我也是因github pages的服务而接触到它,懒人必备。
但用久了jekyll就觉得不爽,毕竟我对ruby不太熟悉,有时候想定制一些功能稍显不太方便,既然这样,那就自己写一个吧。先思考下静态博客生成器的核心功能是啥?首先是将markdown文件转换为html文件,然后生成首页,最后是生成文章页,这三个功能是最基本的,当然还有一些其他功能,比如watch功能,当markdown文件发生变化时,自动重新生成html文件,这样就不用每次都手动去执行生成器了。markdown转html就不在这写了,毕竟也是一个解释器,有一定代码量,这里就直接使用第三方的markdown组件了,要真想写,其实也可以使用字符串替代来将就一下,但这里先不考虑这个。
生成首页和文章页我们这里只有三个关键的header、实际内容、footer三类模板,这三个模板是固定的,只是内容不同,所以我们可以将这三个模板放在一个目录下,然后在生成器中读取这三个模板,将标签内容替换掉,最后生成html文件。关于标签部分,我定义了几个$$post$$、$$content$$、$$nav$$、$$header$$和$$footer$$,分别代表文章列表、文章内容、导航、页头和页脚,这样我们就可以在模板中使用这些标签,然后在生成器中将这些标签替换为实际内容。要更强大的标签,则需要定制一门模板语言。
$$post$$可以通过扫描content目录来获取,$$content$$的内容需要经过markdown解释器转换,$$nav$$是自定义的,$$header$$特指templates/header.html文件,$$footer$$则指templates/footer.html。
至于watch功能,单独启动一个进程定时扫描特定目录,发现目录文件更新后,就重新生成html文件,这里使用了swoole的Process类,当然也可以使用inotify来监听文件变化,这里就不展开了。
项目目录结构如下,content/目录用于放置markdown文章;public/目录的文件由生成器生成;templates/目录是模板目录,像页头、页脚、首页、文章页等模板文件都放在这里;composer.json是PHP的版本管理工具,为了简化代码,使用了第三方markdown组件,毕竟本文的重点是静态页面生成,而不是markdown渲染;generator.php是生成器的主要代码。
content/
2025-02-12-测试.md
public/
templates/
footer.html
header.html
index.html
post.html
composer.json
generator.php
文章页 content/2025-02-12-测试.md
这就是一个常规的markdown文件,内容如下。
### PHP
`PHP`是世界上最好的语言,以下是一个简单的`PHP`代码示例,想了解更多请访问[官网](https://www.php.net)。
```php
<?php
echo "Hello world\n";
```
页面尾模板 templates/footer.html
<div style="color: gray; position: fixed; bottom: 10px; left: 50%; transform: translateX(-50%);">copyright xxx</div>
页面头模板 templates/header.html
<div style="text-align: center; margin-bottom: 20px;">$$nav$$</div>
首页模板 templates/index.html
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>静态博客生成器</title>
</head>
<body>
$$header$$
$$post$$
$$footer$$
</body>
</html>
文章页模板 templates/post.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>静态博客生成器</title>
</head>
<body>
$$header$$
$$content$$
$$footer$$
</body>
</html>
composer.json
只需要以下markdown解释器。
在 PHP 中模拟 Go 语言的 defer 语句
看到一个很有意思的项目 https://github.com/php-defer/php-defer,这个项目只用了10行左右的代码就实现了Go语言中的defer,看来灵活运用数据结构还是很重要的。项目源码如下:
<?php
function defer(?SplStack &$context, callable $callback): void {
$context ??= new class extends SplStack {
public function __destruct() {
while ($this->count() > 0) {
call_user_func($this->pop());
}
}
};
$context->push($callback);
}
略显抽象,怎么来理解它呢?$context实际上就是一个栈变量,通过&达到作用域内共用一个栈的效果,作用域内所有defer的回调函数都放到$context栈中。
关键点在于new class extends SplStack一个匿名类继承并改写了SplStack类的__destruct(),使得$context销毁时可以逆序调用入栈的回调函数,用法如下。
<?php
function foo(): void {
defer($_, function () {
echo "first defer\n";
});
defer($_, function () {
echo "second defer\n";
});
echo "before exception\n";
throw new Exception('My exception');
}
try {
foo();
} catch (Exception $e) {
echo $e->getMessage(), "\n";
}
相当于下面的Go代码。
package main
import "fmt"
func foo() {
defer fmt.Println("first defer")
defer fmt.Println("second defer")
fmt.Println("before exception")
panic("My exception")
}
func main() {
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
foo()
}
调用结果如下。
探索 PHP 源码(三)——从一个简单的时间函数入门
想必phper对date()函数不会陌生,date('Y-m-d H:i:s')是常见的用法。date扩展代码行数不少,而且一大块宏让人摸不着头脑。先根据自己的思路写一个吧,给PHP添加一个打印当前时间格式化形式的函数。函数原型位于ext/standard/basic_functions.stub.php,function pmydate(string $value): void {}函数接收一个格式化字符串,仅支持Y、m、d、H、i、s几种格式,没有返回值,直接输出结果。
// ext/standard/basic_functions.stub.php
function pmydate(string $value): void {}
扩展代码:
// ext/standard/basic_functions.c
PHP_FUNCTION(pmydate)
{
zval *zv_ptr;
php_printf("passed %d parameters to the function: pmydate\n", ZEND_NUM_ARGS());
if (zend_parse_parameters(ZEND_NUM_ARGS(), "z", &zv_ptr) == FAILURE) {
return;
}
if (Z_TYPE_P(zv_ptr) != IS_STRING) {
php_printf("Expect one string argument\n");
return;
}
time_t now = time(0);
struct tm *lt = localtime(&now);
char c;
int val;
char type;
char prev = '\0';
for (int i = 0; i < (*zv_ptr).value.str->len; i++) {
c = (*zv_ptr).value.str->val[i];
type = 's';
switch (c) {
case 'Y':
val = lt->tm_year + 1900;
type = 'i';
break;
case 'm':
val = lt->tm_mon + 1;
break;
case 'd':
val = lt->tm_mday;
break;
case 'H':
val = lt->tm_hour;
break;
case 'i':
val = lt->tm_min;
break;
case 's':
val = lt->tm_sec;
break;
case '\\':
val = c;
type = '\0';
break;
default:
val = c;
type = 'c';
}
if (prev != '\\') {
switch (type) {
case 's':
php_printf("%02d", val);
break;
case 'i':
php_printf("%d", val);
break;
case 'c':
php_printf("%c", val);
break;
default:;
}
} else {
php_printf("%c", c);
}
prev = c;
}
php_printf("\n");
}
用法如下:
通过网关为 PHP-FPM 插上 WebSocket 的翅膀
众所周知,运行在PHP-FPM模式下的PHP代码并非常驻内存,而WebSocket实时通信又需要常驻内存,可以说PHP-FPM模式跟
WebSocket就走不到一块去。
虽然可以直接使用AMPHP、REACTPHP、Swoole等众多PHP-CLI的库和扩展来让PHP处理WebSocket业务,但这就相当于做一个新项目了,跟原有的PHP-FPM项目不能很好地兼容。通过WebSocket网关跟WebSocket客户端交互,具体的业务仍然由PHP-FPM框架处理,不仅能以零改动的方式让PHP-FPM拥有了处理WebSocket协议的能力,还不会存在PHP-FPM和PHP-CLI之间生态不兼容的问题。当然最重要的就是不需要更换框架。
架构图如下所示。
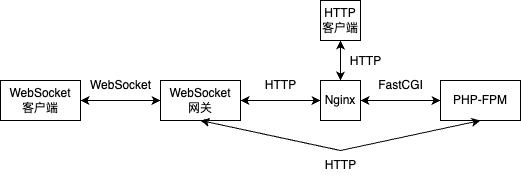
WebSocket 客户端跟WebSocket 网关建立连接,WebSocket 网关接收到WebSocket 客户端发送的数据,通过HTTP协议将数据发送到Nginx,Nginx再用FastCGI协议发送给PHP-FPM,PHP脚本处理完将数据沿原路反方向回传到WebSocket 客户端,这是接收逻辑;如果希望PHP主动推送数据到WebSocket 客户端,则需要额外的HTTP 客户端,因为PHP-FPM不适合持续运行推送,不过这个并不算关键的功能,理论上完全可以通过WebSocket 网关来定时触发,此处不作详细说明。主动推送时,HTTP 客户端向Nginx发起HTTP请求,由PHP-FPM处理,如果PHP脚本判断该请求需要推送到WebSocket 客户端,则将数据发送至WebSocket 网关对内暴露的HTTP接口,WebSocket 网关根据请求选择对应的WebSocket 客户端通信。
PHP 业务代码
websocket.php为PHP和WebSocket 客户端交互的业务逻辑,访问链接为http://localhost/websocket.php 。除了要区分接收和发送行为之外,其它逻辑与一般PHP-FPM项目无异。其中$url变量为WebSocket 网关开放的接口,该接口供PHP主动推送消息给WebSocket 客户端。
<?php
// websocket.php
if (
!empty($_POST['type'])
&& !empty($_POST['client_id'])
&& isset($_POST['message'])
) {
if ($_POST['type'] == 'client') {
// 接收客户端消息,推送到 client_id 对应的 WebSocket 客户端
$url = 'http://host.docker.internal:8080/send';
$cmd = sprintf('curl -d "message=%s&type=client&client_id=%s" %s', $_POST['message'], $_POST['client_id'], $url);
system($cmd);
echo PHP_EOL, $cmd, PHP_EOL;
} else {
// 接收处理 WebSocket 客户端消息
switch ($_POST['message']) {
case 'name':
echo 'lwlinux';
break;
default:
echo 'default';
}
echo ' to '. $_POST['client_id'];
}
} else {
echo 'something wrong';
}
WebSocket 网关
WebSocket 网关的核心功能有两个,一个面向WebSocket 客户端,也就是ws://localhost:8080/ws,对连接进行保活;另一个面向PHP,提供PHP主动推送的接口,将数据转发到WebSocket 客户端,即http://host.docker.internal:8080/send ,该接口接收POST请求,表单参数包括message、client_id(WebSocket 客户端的唯一标识)。启动前,需要提前知道PHP服务地址http://localhost/websocket.php 。
Python 的 bytecode
喜欢上了通过字节码来分析代码差异的感觉,前几天机缘巧合之下玩了下PHP的opcode,今天来看看Python的bytecode。今天也是巧合,恰好群里有人问Python中3 > 2 == 2为什么结果是True?很多语言其实并没有这种表达式。如果用过JavaScript,就会发现它的结果跟Python不一样,正因为如此,我就对3 > 3 == 2在Python中的底层逻辑有点好奇,那就直接动手吧。
有人猜测3 > 2 == 2可能跟3 > 2 and 2 == 2是一样的,这就对比一下两段代码。跟编译型语言有疑问时就看看编译产生的汇编类似,要知道Python代码的逻辑,就得研究它的字节码。dis模块通过反汇编支持CPython的bytecode分析。
# bc.py
import dis
def foo():
return 3 > 2 == 2
def bar():
return 3 > 2 and 2 == 2
dis.dis(foo)
print('-' * 100)
dis.dis(bar)
print('-' * 100)
print(foo(), bar())
$ python3 bc.py
6 0 LOAD_CONST 1 (3)
2 LOAD_CONST 2 (2)
4 DUP_TOP
6 ROT_THREE
8 COMPARE_OP 4 (>)
10 JUMP_IF_FALSE_OR_POP 18
12 LOAD_CONST 2 (2)
14 COMPARE_OP 2 (==)
16 RETURN_VALUE
>> 18 ROT_TWO
20 POP_TOP
22 RETURN_VALUE
----------------------------------------------------------------------------------------------------
10 0 LOAD_CONST 1 (3)
2 LOAD_CONST 2 (2)
4 COMPARE_OP 4 (>)
6 JUMP_IF_FALSE_OR_POP 14
8 LOAD_CONST 2 (2)
10 LOAD_CONST 2 (2)
12 COMPARE_OP 2 (==)
>> 14 RETURN_VALUE
----------------------------------------------------------------------------------------------------
True True
光看结果,foo和bar函数的结果都是True,有戏了,可能真的就逻辑一样。分隔线顶部就是3 > 2 == 2的字节码,现在就来分析一下。
PHP 的 opcode
opcode跟PHP,类似于bytecode跟Java的关系,相当于机器码和编译型语言的关系。
PHP是一门解释型语言,它的执行单元就是opcode,Zend Engine就是执行opcode的地方,Zend Engine也就是常说的VM。JVM比较出名,它就是针对Java设计的VM,这样说应该理解了PHP的Zend Engine和opcode是什么东西了吧。
看看如下代码:
<?php
// opcode1.php
echo "Hello world";
以上代码的opcode是这样的:
0000 ECHO string("Hello world")
0001 RETURN int(1)
如果多个输出呢?
<?php
// opcode2.php
echo "Hello world";
echo "Hello world";
echo "Hello world";
这个问题先暂且不管。
有多种方法可以查看opcode,如Zend Opcache(opcache)扩展、phpdbg接口以及Vulcan Login Dumper(VLD)扩展。
使用 Zend Opcache
前提要求:Zend Opcache扩展必须安装并启用。
opcache.opt_debug_level接收一个十六进制值用于配置opcode的输出,设置为0时会禁用输出。
opcache.opt_debug_level=0x10000:输出未优化的opcode;opcache.opt_debug_level=0x20000:输出优化后的opcode;opcache.opt_debug_level=0x40000:以上下文无关方法形式输出opcode;opcache.opt_debug_level=0x200000:以Static Single Assignments形式输出opcode;
再次以上述的opcode2.php为例。
$ php -d opcache.enable=On -d opcache.enable_cli=On -d opcache.opt_debug_level=0x10000 opcode2.php
$_main:
; (lines=4, args=0, vars=0, tmps=0)
; (before optimizer)
; /root/opcode.php:1-6
; return [] RANGE[0..0]
0000 ECHO string("Hello world")
0001 ECHO string("Hello world")
0002 ECHO string("Hello world")
0003 RETURN int(1)
$ php -d opcache.enable=On -d opcache.enable_cli=On -d opcache.opt_debug_level=0x20000 opcode2.php
$_main:
; (lines=2, args=0, vars=0, tmps=0)
; (after optimizer)
; /root/opcode.php:1-6
0000 ECHO string("Hello worldHello worldHello world")
0001 RETURN int(1)
这就是对“如果多个输出呢?”这个问题的回答,未经优化时,三个echo语句解析为三条ECHO string("Hello world)指令,优化后合并为一条指令。
一个简单的 RPC 示例
远程过程调用——RPC(Remote Procedure Call),在《UNIX 网络编程》一书中是这样描述的:被调用过程和调用过程处于不同的进程中,一个进程调用同一台主机上另一个进程的某个过程(函数)。RPC通常允许一台主机上的某个客户调用另一台主机上的某个服务器过程,只要这两台主机以某种形式的网络连接着。
RPC的实现方式有很多,如XML-RPC、JSON-RPC、SOAP等,这里我们使用JSON作为数据传输格式,UDP作为网络传输协议,PHP作为编程语言。具体传输格式如下:
{
"class": "Test",
"method": "say",
"params": ["william", "你好,世界"]
}
为了简化示例,代码仅能调用类方法,通过class指定类,method指定方法名,params指定参数。
RPC 服务端
Test是服务端中可被客户端调用的类;RPCServer用于接收RPCClient请求并解释、代替客户端调用类方法。
<?php
// RPCServer.php
class Test
{
public function say(string $name, string $message, mixed ...$extra): string
{
return json_encode([
'name' => $name,
'message' => $message,
'extra' => [...$extra],
], JSON_UNESCAPED_UNICODE|JSON_UNESCAPED_SLASHES);
}
}
class RPCServer
{
private $socket;
private function _wrapQuote(string $str): string
{
return '"' . $str . '"';
}
/**
* @throws Exception
*/
public function __construct(string $host, int $port)
{
$this->socket = stream_socket_server("udp://$host:$port", $errno, $error, STREAM_SERVER_BIND);
if (!$this->socket) {
throw new Exception("$errno: $error");
}
while (true) {
$buf = stream_socket_recvfrom($this->socket, 1024, 0, $client);
if ($buf) {
$json = json_decode($buf, true);
if (
isset($json['class'], $json['method'], $json['params'])
&& is_string($json['class']) && is_string($json['method']) && is_array($json['params'])
) {
if (
class_exists($json['class'])
&& method_exists($obj = new $json['class'](), $json['method'])
) {
try {
$res = call_user_func([$obj, $json['method']], ...$json['params']);
stream_socket_sendto($this->socket, json_encode($res), 0, $client);
} catch (Throwable $e) {
stream_socket_sendto($this->socket, $this->_wrapQuote($e->getFile(). '(line: '. $e->getLine(). '): '. $e->getMessage()), 0, $client);
}
} else {
stream_socket_sendto($this->socket, $this->_wrapQuote('class or method not exist'), 0, $client);
}
} else {
stream_socket_sendto($this->socket, $this->_wrapQuote('invalid protocol'), 0, $client);
}
}
}
}
public function __destruct()
{
fclose($this->socket);
}
}
try {
new RPCServer('127.0.0.1', 10240);
} catch (Throwable $e) {
echo $e->getMessage(), "\n";
}
$ php RPCServer.php
RPC 客户端
Test只是一个伪类,作用就是提供IDE提示,其中的文档注释对开发友好,实际上去掉也不影响功能完整性;RPCClient作为代理,发起远程过程调用;Factory起到隐藏网络细节的作用,让用户以为这只是一个本地的调用。
尴尬的 curl 和尴尬的我
事情的起因是这样的,对接某个接口,一个POST请求的请求体比较大(注:跟系统和curl的版本有关,有的并不会发送Except请求头),curl默认给我发送了Expect请求头,事前我并不知道,但一直没调通,对方就提出要看看我的HTTP报文。
糟糕,你让我手写一个HTTP请求报文,我分分钟就能写出来,不就这么简单么:
POST /xxx HTTP/1.1
Host: localhost
Content-Type: application/x-www-form-urlencoded
Content-Length: 12
name=lwlinux
你让我获取curl的请求报文,突然就觉得有点懵,我还真找不到直接的接口来获取,不管是curl命令还是使用了curl库的php,它都没有。只能采取折中的办法,curl有个-v选项,但--trace-ascii curl.trace.log保存到文件中显然更适合处理,换成php中的curl,则对应以下代码:
<?php
$verboseFile = __DIR__. '/curl.trace.log';
$verboseFd = fopen($verboseFile, 'w+');
curl_setopt($ch, CURLOPT_VERBOSE, true);
curl_setopt($ch, CURLOPT_STDERR, $verboseFd);
一个完整的示例代码如下:
<?php
$url = 'http://nginx/programming_practice/php/snippets/php.php';
$body = http_build_query(['name' => str_repeat('lwlinux', 200)]);
$verboseFile = __DIR__. '/curl.trace.log';
$verboseFd = fopen($verboseFile, 'w+');
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $body);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_VERBOSE, true);
curl_setopt($ch, CURLOPT_STDERR, $verboseFd);
$resp = curl_exec($ch);
$respInfo = curl_getinfo($ch);
$curlError = curl_error($ch);
$curlErrno = curl_errno($ch);
curl_close($ch);
fclose($verboseFd);
var_dump(
'verbose ==============================================',
file_get_contents($verboseFile),
'request ==============================================',
$body,
'response ==============================================',
$resp,
'respInfo ==============================================',
$respInfo,
'curlError ==============================================',
$curlError,
'curlErrno ==============================================',
$curlErrno
);
以上代码输出片段如下,忽略一些多余的内容,应该大概能看懂吧。
似乎挺多人不知道 PHP 可以通过 URL 甚至请求体来传递 SESSION_ID
由于HTTP是无状态的,服务端不知道前一个访问者跟后一个访问者是否为同一人,于是会话机制出现了。session和cookie几乎总是同时出现的。cookie是由服务端创建、由客户端保存的小块数据,在用户再次访问服务时,会带上该服务端对应的cookie,服务端比对后就能辨别出用户身份。而在服务端跟cookie对应的数据就称为session。
从以上描述可以发现,会话中的cookie是由服务端生成的且要唯一识别用户,称为session_id,PHP默认通过cookie传递session_id。HTTP协议中的响应头Set-Cookie就是用来干这活的,HTTP响应报文无非就响应头和响应体,不用Set-Cookie行不行?当然,自己实现一套session机制也是可以的;既然服务端可以通过其它响应头或响应体来传递session_id,那客户端是不是也能不通过Cookie请求头来传递session_id?确实也可以。
通过 URL 传递
PHP的session机制除了通过cookie来传递session_id外,还可以通过URL参数来传递,详情查看 https://www.php.net/manual/en/session.idpassing.php一节。测试代码如下:
<?php
ini_set('session.use_only_cookies', 0);
ini_set('session.name', 'phpsid');
session_start();
if (isset($_GET['init'])) {
$_SESSION['name'] = 'lwlinux';
echo session_id(), PHP_EOL;
}
print_r($_SESSION);
PHP出于安全的考虑,默认只允许通过cookie传递session_id,为了通过URL传递,需要将session.use_only_cookies禁用,同时为了便于测试,可以设置一个易记的session.name。以下命令完整地测试了创建session、无参数无法获取session、URL传参获取session三个功能。至于session_id在客户端怎么保存就不用提了。
$ curl http://php84.id/programming_practice/php/snippets/php.php?init
73c6fa808fc7e2074a3c68e40b412f3d
Array
(
[name] => lwlinux
)
$ curl http://php84.id/programming_practice/php/snippets/php.php
Array
(
)
$ curl http://php84.id/programming_practice/php/snippets/php.php?phpsid=73c6fa808fc7e2074a3c68e40b412f3d
Array
(
[name] => lwlinux
)
通过请求体传递
通过URL传递session_id会存在安全风险,不过在客户端禁用cookie时那也是没办法的,可以使用https等方式来加强安全,只不过URL会保留在访问记录中,依然不安全。事实上,PHP还可以通过请求参数来传递,对比上述PHP代码,多了获取phpsid请求体参数并使用session_id()函数设置当前会话ID的逻辑。
<?php
ini_set('session.use_only_cookies', 0);
ini_set('session.name', 'phpsid');
session_start();
if (isset($_GET['init'])) {
$_SESSION['name'] = 'lwlinux';
echo session_id(), PHP_EOL;
}
if (!empty($_POST['phpsid'])) {
session_id($_POST['phpsid']);
}
print_r($_SESSION);
沿用上面生成的session_id,对比测试一下是否带参数即可。
“纯手工”创建一张简单的 PNG 图片
每个人的计算机里都保存着各种各样的文件,有没有想过为什么纯文本文件可以方便地编辑,只需要输入、删除文字即可,而图片则需要使用一些“重量级”的软件才能处理?图片跟纯文本文件有什么区别?
《深入理解计算机系统》第1.7.4节首句话——文件就是字节序列,仅此而已。从这点上看,图片跟纯文本文件可以说没区别。它们之所以表现出这么大的差异性,完全是“位”+“上下文”不同所造成的。先看看一个纯文本文件的十六进制是怎样的,test.txt文件内容如下:
abc
查看文件十六进制数据:
$ xxd test.txt
00000000: 6162 63 abc
至于图片,拿简单的PNG图片为例吧,由于图片的内容有大部分都是不可打印字符,因此,我们换一种方式来制作图片。当然啦,为了呼应标题,并没有调用任何标准库和第三方跟图片处理相关的库,只是简单地使用了原始的字符处理、压缩、CRC函数,让整个过程更“原汁原味”,可以清晰看到PNG的内部构造。以下代码创建了一张宽度和高度均为3像素的PNG图片,每一行的颜色分别是“红绿蓝”、“蓝红绿”、“绿蓝红”。
<?php
function chunk($type, $data): string
{
$chunk = $type. $data;
$crc = crc32(empty($data) ? $type : $chunk);
$ret = pack('N', strlen($data)). $chunk. pack('N', $crc);
return $ret;
}
function createPng(): void
{
// 1. PNG 文件头:
// 89:用于检测传输系统是否支持8位的字符编码,以减少将文本文件被错误识别成 PNG 文件的机会
// 50 4E 47:PNG 每个字母对应的 ASCII 编码
// 0D 0A:DOS 风格的换行
// 1A:DOS 命令行下,用于阻止文件显示的文件结束符
// 0A:Unix 风格的换行符
$header = "\x89PNG\r\n\x1A\n";
// 2. IHDR 块:描述图片宽高和颜色信息的块。依次:4 字节为宽度;4 字节为高度;1 字节为位深度;1 字节为颜色类型;1 字节为压缩方法;1 字节为滤波方法;1 字节为交错方法;4 字节为 CRC 校验(16 进制计算得到)
$chunkType = 'IHDR';
$width = 3;
$height = 3;
$ihdrData = pack('N*', $width, $height) . "\x08\x02\x00\x00\x00"; // 3x3, 8 bits per channel, RGB
$ihdr = chunk($chunkType, $ihdrData);
// 3. IDAT 块:图片的实际像素数据,使用过滤器和 zlib 压缩来编码
$chunkType = 'IDAT';
// 像素数据(白色背景,中心红点)
$filterType = "\x00"; // 过滤器
$pixelData = $filterType. "\xFF\x00\x00". "\x00\xFF\x00". "\x00\x00\xFF".
$filterType. "\x00\x00\xFF". "\xFF\x00\x00". "\x00\xFF\x00".
$filterType. "\x00\xFF\x00". "\x00\x00\xFF". "\xFF\x00\x00";
$compressedData = gzcompress($pixelData);
$idat = chunk($chunkType, $compressedData);
// 4. IEND 块
$chunkType = 'IEND';
$iend = chunk($chunkType, '');
$pngData = $header . $ihdr . $idat . $iend;
file_put_contents('output.png', $pngData);
}
createPng();
边看代码边看解释。一张极为简单的PNG图片由四个部分组成:
探索 PHP 源码(二)——调整 phpinfo 在 cli 下的格式
php-cli下的phpinfo()并没有html格式,对于像reactphp、amphp等库就显示不是那么友好了,所以添加一个选项来开关html格式的phpinfo()显示比较有用。
sapi/cli/php_cli.c的代码:
int phpinfo_as_text = 1;
while ((c = php_getopt(argc, argv, OPTIONS, &php_optarg, &php_optind, 1, 2))!=-1) {
switch (c) {
...
case 'e': /* enable extended info output */
phpinfo_as_text = 0;
use_extended_info = 1;
break;
}
}
...
sapi_module->phpinfo_as_text = phpinfo_as_text;
定位一下sapi_module->phpinfo_as_text这部分代码,即可找到以上代码修改位置,利用一下现有的选项-e。接下来就可以php -e xxx.php来开启命令行下的html格式信息。
如果不想复用其它选项,则麻烦一点,在const opt_struct OPTIONS[] = {}中自己加个选项,如{'k', 0, "phpinfo-as-text"},再将以上case 'e'中的phpinfo_as_text = 0放到新增的case 'k'中。
使用reactphp测试一下:
<?php
// react.php
require __DIR__ . '/vendor/autoload.php';
$http = new React\Http\HttpServer(function (Psr\Http\Message\ServerRequestInterface $request) {
ob_start();
phpinfo();
$info = ob_get_contents();
ob_end_clean();
return React\Http\Message\Response::html(
$info
);
});
$socket = new React\Socket\SocketServer('127.0.0.1:8080');
$http->listen($socket);
分别用以下命令测试(php需要更换为自己编译的版本):
探索 PHP 源码(〇)——定制可调试的 PHP 解释器
探索PHP源码时,定制编译是挺重要的,毕竟预先编译发行版是没有调试功能的。
首先安装编译工具(debian系统):
$ sudo apt install -y pkg-config build-essential autoconf bison re2c libxml2-dev libsqlite3-dev
这些工具也不需要记,https://github.com/php/php-src上都有。
编译
以下是自用的编译脚本:
$ make clean \
&& PREFIX_DIR=$PWD/output \
&& rm -rf $PREFIX_DIR \
&& ./buildconf -f \
&& INI_DIR=$PREFIX_DIR/ini \
&& ./configure \
--enable-debug \
--prefix=$PREFIX_DIR \
--with-config-file-path=$INI_DIR \
&& echo $PREFIX_DIR \
&& echo $INI_DIR \
&& sleep 5 \
&& make \
&& make install \
&& mkdir -p $INI_DIR \
&& cp $PWD/php.ini-production $INI_DIR/php.ini \
&& EXT_DIR=`$PWD/output/bin/php-config --extension-dir` \
&& echo $EXT_DIR \
&& echo "extension_dir=${EXT_DIR}" >> $INI_DIR/php.ini
./configure脚本可配的参数比较多,根据需要添加减少,./configure --help查看所有选项。
如果使用macos的m系列芯片,还需要添加--with-iconv=/opt/homebrew/opt/libiconv。通过brew安装iconv的话,可以根据brew info libiconv来获取路径。
探索 PHP 源码(一)——创建扩展
有时候还是得逼自己一把,自从写了下玩具编译器后,就对语言底层原理产生了浓厚的兴趣。但是,C语言本身呢,看起来似乎语言本身的内容不多,但真的太灵活了,一个宏就能让人晕头转向;还有各种贴近硬件的类型,未定义行为,指针,想写好真的不简单。PHP解释器是用C实现的,因此也容易让我产生畏难情绪。
其实学C语言的时间也不短了,却一直没用它写过像样的程序。最近又翻了下一本C语言书,有了些许收获,也许会让我能沉下心来钻进PHP解释器中。同时,PHP基金会的成立也让我对这门语言越来越有了接近之意,关注了很多社区中的大牛,也许受了感染吧,感觉就挺有意思。
最重要的就是想深入一门语言,探究其本质,对其它语言的使用也有帮助。语言不计其数,究其源头是相通的,不给自己限定为XX语言的开发者,对语言少些敬畏,减少其带来的束缚。
下面直接点吧,先给PHP加上自己想要的函数,就 https://github.com/phpinternalsbook/PHP-Internals-Book 书中简单的dump函数以及自己加的helloworld函数。
PHP的库函数基本都位于ext目录中,其中standard又是最小化安装时仅剩的几个扩展之一,因此我决定将这两个函数放在这里,该目录中又以basic_functions.c最得我心,就放这了,在ext/standard/basic_functions.c末尾加上以下代码:
// ext/standard/basic_functions.c
PHP_FUNCTION(dump)
{
zval *zv_ptr;
if (zend_parse_parameters(ZEND_NUM_ARGS(), "z", &zv_ptr) == FAILURE) {
return;
}
try_again:
switch (Z_TYPE_P(zv_ptr)) {
case IS_NULL:
php_printf("NULL: null\n");
break;
case IS_TRUE:
php_printf("BOOL: true\n");
break;
case IS_FALSE:
php_printf("BOOL: false\n");
break;
case IS_LONG:
php_printf("LONG: %ld\n", Z_LVAL_P(zv_ptr));
break;
case IS_DOUBLE:
php_printf("DOUBLE: %g\n", Z_DVAL_P(zv_ptr));
break;
case IS_STRING:
php_printf("STRING: value=\"");
PHPWRITE(Z_STRVAL_P(zv_ptr), Z_STRLEN_P(zv_ptr));
php_printf("\", length=%zd\n", Z_STRLEN_P(zv_ptr));
break;
case IS_RESOURCE:
php_printf("RESOURCE: id=%d\n", Z_RES_HANDLE_P(zv_ptr));
break;
case IS_ARRAY:
php_printf("ARRAY: hashtable=%p\n", Z_ARRVAL_P(zv_ptr));
break;
case IS_OBJECT:
php_printf("OBJECT: object=%p\n", Z_OBJ_P(zv_ptr));
break;
case IS_REFERENCE:
// For references, remove the reference wrapper and try again.
// Yes, you are allowed to use goto for this purpose!
php_printf("REFERENCE: ");
zv_ptr = Z_REFVAL_P(zv_ptr);
goto try_again;
EMPTY_SWITCH_DEFAULT_CASE() // Assert that all types are handled.
}
}
PHP_FUNCTION(helloworld)
{
printf("Hello world\n");
}
可以发现,想要给PHP添加新函数,只需要用PHP_FUNCTION宏包装一下即可。helloworld最为简单,深得我心。目前PHP 8.2.6除了定义函数外,还需要在ext/standard/basic_functions.stub.php中加上函数原型,姑且叫它函数原型吧,就看它像C语言的函数原型。至于PHP 8.2.6之前的版本先不管,再次在文件末尾加上以下代码:
部署私有 LLM
目前对LLM(Large Language Models,大语言模型)一无所知,万事开头难,虽然部署了,但并不知道原理,不过起码兴趣点上了,好歹以兴趣入手,搞一个私有的知识库倒是不错。
还是得Linux环境方便,Ollama和Anything LLM一起构成了我所要的知识库。Ollama应该是目前本地构建运行LLM最好的工具了,但我不仅是想本地构建,而且要是私人知识库,因此,嵌入自己的知识数据就是另一个重要的部分。以我目前粗浅的见识来看,Ollama给LLM嵌入数据还是需要其它工具协助的,Anything LLM正好符合我的要求。
Anything LLM有很好的易用性,而且还有开箱即用的RAG(检索增强生成,Retrieval-augmented Generation)、AI Agents(人工智能体)等工具。RAG生成模型结合了语言模型和信息检索技术,当模型需要生成信息时,它会从一个庞大的文档集合中检索相关数据,然后利用其生成对应的信息,从而提高预测的质量和准确性;AI Agents与传统的人工智能相比,可以通过调用工具逐步完成既定目标。
Ollama加Anything LLM的优点这么多,部署起来却一点也不难,前提是会使用Docker。以下是部署命令:
$ docker network create llm
$ docker run -d -ti --name ollama --network llm ollama/ollama
$ export STORAGE_LOCATION=$HOME/anythingllm && \
mkdir -p $STORAGE_LOCATION && \
chmod 777 $STORAGE_LOCATION && \
touch "$STORAGE_LOCATION/.env" && \
chmod 777 "$STORAGE_LOCATION/.env" && \
docker run -d -p 3001:3001 \
-e OPENAI_API_KEY=foo \
--network llm \
--name anythingllm \
--cap-add SYS_ADMIN \
-v ${STORAGE_LOCATION}:/app/server/storage \
-v ${STORAGE_LOCATION}/.env:/app/server/.env \
-e STORAGE_DIR="/app/server/storage" \
mintplexlabs/anythingllm:master
首先创建一个网络llm,让Ollama和Anything LLM们于同一网络,毕竟它们之间需要通信。Ollama的安装倒没什么可说的,Anything LLM的安装命令根据实际情况对官网的进行了一定修改。其中包含两个chmod命令,如果不加权限,可能由于Docker跟宿主系统用户不一致导致权限不足;另外-e OPENAI_API_KEY=foo这个是因为Anything LLM也支持选择openai,需要为它添加一个环境变量OPENAI_API_KEY,至于变量值如果不使用的话填一个非空值即可,这两个问题可能是导致Anything LLM运行异常的重要原因。
还有一个值得注意的是在Anything LLM界面选择模型运行工具时,选择Ollama填入的链接上填入http://ollama:11434,这个“域名”ollama就是Docker容器的名称。
至此,已经将本地的LLM部署完成,通过http://localhost:3001即可访问,通过上述的步骤即可看到以下界面。
上图红色方框的按钮用于上传个人文件,“训练”大模型,让其成为知识库,支持多种格式文件。除了界面外,Anything LLM还开放了API,便于企业对接嵌入内部数据,形成企业领域专用模型。
服务器性能不要太差喔。
用原始方法打包一个 macOS 下的 GTK 桌面程序
一直都写服务端,对计算机的运行原理有了一定了解,就想看看自己对其它领域程序的理解是不是可以举一反三。
最简单的GTK程序就是官网入门示例了,安装GTK的过程就不在这描述。代码如下:
// hello.c
#include <gtk/gtk.h>
static void
print_hello (GtkWidget *widget,
gpointer data)
{
g_print ("Hello World\n");
}
static void
activate (GtkApplication *app,
gpointer user_data)
{
GtkWidget *window;
GtkWidget *button;
window = gtk_application_window_new (app);
gtk_window_set_title (GTK_WINDOW (window), "Hello");
gtk_window_set_default_size (GTK_WINDOW (window), 200, 200);
button = gtk_button_new_with_label ("Hello World");
g_signal_connect (button, "clicked", G_CALLBACK (print_hello), NULL);
gtk_window_set_child (GTK_WINDOW (window), button);
gtk_window_present (GTK_WINDOW (window));
}
int
main (int argc,
char **argv)
{
GtkApplication *app;
int status;
app = gtk_application_new ("org.gtk.example", G_APPLICATION_DEFAULT_FLAGS);
g_signal_connect (app, "activate", G_CALLBACK (activate), NULL);
status = g_application_run (G_APPLICATION (app), argc, argv);
g_object_unref (app);
return status;
}
编译:
语法分析
语法分析是编译前端部分的重要部分。
# todo
class PlusMinus:
def __init__(self, left, op, right):
self.left = left
self.op = op
self.right = right
def __str__(self):
return '({} {} {})'.format(self.left, self.op, self.right)
class MulDiv:
def __init__(self, left, op, right):
self.left = left
self.op = op
self.right = right
def __str__(self):
return '({} {} {})'.format(self.left, self.op, self.right)
class Unary:
def __init__(self, op, right):
self.op = op
self.right = right
def __str__(self):
return '({}{})'.format(self.op, self.right)
class Group:
def __init__(self, expr):
self.expr = expr
def __str__(self):
return '{}'.format(self.expr)
class Literal:
def __init__(self, expr):
self.expr = expr
def __str__(self):
return '{}'.format(self.expr)
class Parser:
index = 0
tokens = []
length = 0
def __init__(self, tokens):
self.tokens = tokens
self.length = len(tokens)
def expression(self):
return self.plus_minus()
def plus_minus(self):
expr = self.mul_div()
if self.index < self.length and (self.tokens[self.index] == '+' or self.tokens[self.index] == '-'):
op = self.tokens[self.index]
self.index += 1
right = self.mul_div()
expr = PlusMinus(expr, op, right)
return expr
def mul_div(self):
expr = self.unary()
if self.index < self.length and (self.tokens[self.index] == '*' or self.tokens[self.index] == '/'):
op = self.tokens[self.index]
self.index += 1
right = self.unary()
expr = MulDiv(expr, op, right)
return expr
def unary(self):
if self.index < self.length and self.tokens[self.index] == '-':
op = self.tokens[self.index]
self.index += 1
right = self.primitive()
expr = Unary(op, right)
return expr
return self.primitive()
def primitive(self):
if self.index < self.length and self.tokens[self.index] == '(':
self.index += 1 # 消耗 (
expr = self.plus_minus()
self.index += 1 # 消耗 )
expr = Group(expr)
return expr
else:
ret = self.tokens[self.index]
print(ret)
self.index += 1
return Literal(ret)
# (1 + 2) * 3 + 4 * (-5 + 6)
p = Parser(['(', '1', '+', '2', ')', '*', '3', '+', '4', '*', '(', '-', '5', '+', '6', ')', '+', 'add()', '-', 'a'])
expr = p.expression()
print(expr)
一个简单的 HTTP 路由
HTTP路由是一个负责将HTTP请求路由到对应控制器的组件,它可以将应用的逻辑解耦到不同的控制器中,让代码易于维护。
路由有很多实现的方式,例如通过注解如#[Route('/foo/bar', methods: ['GET', 'POST'])]、路由配置文件、编程语言本身等等。下面以PHP的路由作为示例,路由需要两个基本的功能:1、注册;2、分发。
注册功能并不复杂,只需要将请求方法、请求路径以及回调方法一一映射即可,将要实现的路由简单支持的全路径、命名正则以及命名路径匹配,全路径如/foo/bar,命名正则如{id:\d+}将匹配\d+正则的路径命名为id,{name}将普通路径命名为name。代码:
class Router
{
private array $routes = [];
public function addRoute(string $method, string $uri, callable $controller): void
{
$uri_arr = explode('/', $uri);
if (count($uri_arr) < 2) {
return;
}
foreach ($uri_arr as $key => $item) {
// {id:\d+}
if (preg_match('~^\{([\s\S]+?):([\s\S]+?)}$~', $item)) {
$uri_arr[$key] = preg_replace('~^\{([\s\S]+?):([\s\S]+?)}$~', '(?<\1>\2)', $item);
// {name}
} else if (preg_match('~^\{([\s\S]+?)}$~', $item)) {
$uri_arr[$key] = preg_replace('~^\{([\s\S]+?)}$~', '(?<\1>[\s\S]+?)', $item);
}
}
$uri = implode('/', $uri_arr);
$this->routes[$method][$uri] = $controller;
}
}
注册方法用法如下:
$router = new Router();
$router->addRoute('GET', '/', [FooController::class, 'index']); // 路径 /
$router->addRoute('GET', '/{bar}/a', [FooController::class, 'bar']); // 路径 /foo/a 或 /bar/a 等等
$router->addRoute('GET', '/regex/{name}/{id}', [FooController::class, 'regex']); // 路径 /regex/foo/1 等等
$router->addRoute('GET', '/regex/{value:\d+}', [FooController::class, 'regex']); // 路径 /regex/1 等等
我们在这模拟了框架的控制器作为路由的回调方法:
Python 的元组疑惑
发现一个有点意思的问题,代码如下:
t = (['a'], 1, 2)
try:
t[0] += ['b', 'c']
except Exception as e:
print(e)
print(t)
# output:
# 'tuple' object does not support item assignment
# (['a', 'b', 'c'], 1, 2)
这代码对于我这个不正经的python学习者来说,确实会产生点疑惑。抛出异常,但是t的值确实改变了。虽然我知道不可以直接增加、修改、删除元组的元素,但如果元素是可变元素,还是可以修改可变元素本身的。可是这段代码着实是有点奇怪,可变元素确实是变了,但还是抛出异常。问题先记着,再看看另一段代码:
t = (['a'], 1, 2)
try:
t[0].extend(['b', 'c'])
except Exception as e:
print(e)
print(t)
# output:
# (['a', 'b', 'c'], 1, 2)
这段代码就不会抛出异常了,可见,元组内的可变元素本身是可以被修改的,那么在修改元组的可变元素之后,想必是多了什么操作,再回看之前t[0] += ['b', 'c']以及'tuple' object does not support item assignment,咦,这是提醒我们,它做了赋值操作t[0] += ['b', 'c']比t[0].extend(['b', 'c'])的效果多了一个赋值,也就相当于:
t = (['a'], 1, 2)
try:
t[0].extend(['b', 'c'])
t[0] = t[0]
except Exception as e:
print(e)
print(t)
# output:
# 'tuple' object does not support item assignment
# (['a', 'b', 'c'], 1, 2)
嗯,结果对上了,赋值成功,但抛出同样的异常。虽然我们不一定能看懂python的源码,但可以通过异常推断python在背后的大概操作。
由 PHP Fiber 引发的思考
由于水平有限,可能有些术语并不是那么准确。
PHP 8.1的新特性Fiber,可能让很多PHPer误解了,以为Fiber的出现可以解决PHP生态的很多问题,如官方多线程方案的缺失、PHP-FPM多进程阻塞模型的优化。但实际上Fiber目前解决的问题并不多,只是在底层引入了用户栈空间切换的原语,并不能像进程和线程那样,在同步阻塞时,仍然可以在操作系统层面进行上下文切换,不至于让整个程序无法往后执行。
现在PHP生态中,目前在这个方向可能走得最远的还是Swoole,在PHP内核层面将同步阻塞的函数进行hook,让标准库的同步阻塞函数和类不再阻塞整个程序。而同类的如Workerman、ReactPHP、AMPHP都无法做到,它们在使用所以造很多异步非阻塞的轮子。正如AMPHP的官网上写的一句话“It’s important to avoid using blocking functions in concurrent code, such as sleep, usleep, fwrite, fread and other built-in functions doing I/O. We offer a great variety of non-blocking I/O implementations you can use instead.”。像Swoole、Workerman之类的库,一个很明显的特征就是使用了Event Loop(事件循环)。什么是事件循环?事件,就是读、写、异常、时间等事件,循环就很好理解了,以下就是一个简单的事件循环事例:
<?php
// 创建套接字
$socket = socket_create(AF_INET, SOCK_STREAM, SOL_TCP);
socket_bind($socket, '127.0.0.1', 10101);
socket_listen($socket);
// 创建套接字数组
$sockets = [$socket];
while (true) {
$readSockets = $sockets;
$writeSockets = $exceptSockets = null;
// 选择可读、可写和异常套接字
socket_select($readSockets, $writeSockets, $exceptSockets, null);
// 处理可读套接字
foreach ($readSockets as $readSocket) {
if ($readSocket === $socket) {
// 接受新连接
$clientSocket = socket_accept($socket);
$sockets[] = $clientSocket;
echo "New client connected\n";
} else {
// 处理客户端请求
$data = socket_read($readSocket, 1024);
if ($data === false) {
// 客户端断开连接
$index = array_search($readSocket, $sockets);
unset($sockets[$index]);
socket_close($readSocket);
echo "Client disconnected\n";
} else if (!empty($data)) {
// 处理客户端数据
echo "Received data: $data\n";
// 这里可以添加你的业务逻辑代码
}
}
}
}
// 关闭套接字
socket_close($socket);
事件循环,也就是循环获取事件(通过select、poll、epoll等机制),进行相对的业务操作,这就是Swoole等库的原理。通过以上代码,我们可以发现,事件循环中,一旦业务代码出现同步阻塞操作,会让异步非阻塞退化成同步阻塞,导致代码无法将控制权交还给事件循环,后续的逻辑也就会延时执行,这也是很多异步库的通病。而Swoole将标准库hook之后,同步阻塞的操作变成异步非阻塞的,从而避免这种情况,这也是它很受欢迎的原因。而Go语言的协程模型则更加优秀了,因为协程是包含在语言的设计中的,不像PHP、Python等语言,出现的时间太早,在语言层面并没有做相应的设计,导致“协程”功能都是缝缝补补,用起来也就需要多加注意。
Stack Machines
Stack Machines,感觉不翻译看起来会顺眼一点,翻译成栈机感觉怪怪的。该文章总结自Igor Wiedler的Stack Machines系列文章,可惜他很久没贡献过代码以及没更新过博客了。先贴代码,到时候再写文章,可能需要一段时间来消化这个系列。
<?php
// php 8.2
/**
* 操作符优先级以及结合性
*/
const operators = [
'+' => ['precedence' => 0, 'associativity' => 'left'],
'-' => ['precedence' => 0, 'associativity' => 'left'],
'*' => ['precedence' => 1, 'associativity' => 'left'],
'/' => ['precedence' => 1, 'associativity' => 'left'],
'%' => ['precedence' => 1, 'associativity' => 'left'],
];
/**
* 栈机执行器
* @param array $ops
* @return mixed|void
*/
function execute(array $ops)
{
$labels = [];
$vars = [];
$calls = new SplStack();
$stack = new SplStack();
// 这里需要先获取所有 label,以防之后的 jmp/call 之类的指令找不到 label
foreach ($ops as $ip => $op) {
if (preg_match('/^label\((.+)\)$/', $op, $match)) {
$label = $match[1];
$labels[$label] = $ip;
}
}
for ($ip = 0; $ip < count($ops); $ip++) {
$op = $ops[$ip];
if (is_numeric($op)) {
$stack->push((int)$op);
continue;
}
// 格式:label(main),名为 main 的标签
// 移到上面,防止 jmp 找不到 对应的 $labels[$label];
if (preg_match('/^label\((.+)\)$/', $op, $match)) {
// $label = $match[1];
// $labels[$label] = $ip;
continue;
}
// 格式:jmp(main),跳转到 main 标签
if (preg_match('/^jmp\((.+)\)$/', $op, $match)) {
$label = $match[1];
$ip = $labels[$label];
continue;
}
// 格式:jz(main),如果栈顶元素为 0,则跳转到 main 标签
if (preg_match('/^jz\((.+)\)$/', $op, $match)) {
$label = $match[1];
if ($stack->pop() === 0) {
$ip = $labels[$label];
}
continue;
}
// 格式:jnz(main),如果栈顶元素不为 0,则跳转到 main 标签
if (preg_match('/^jnz\((.+)\)$/', $op, $match)) {
$label = $match[1];
if ($stack->pop() !== 0) {
$ip = $labels[$label];
}
continue;
}
// 格式:call(printstr),函数调用
if (preg_match('/^call\((.+)\)$/', $op, $match)) {
$label = $match[1];
$calls->push([$ip, $vars]);
$ip = $labels[$label];
continue;
}
// 格式:value !var(varname),声明变量并赋值为 $stack 顶的元素
if (preg_match('/^!var\((.+)\)$/', $op, $match)) {
$var = $match[1];
$vars[$var] = $stack->pop();
continue;
}
// 格式:var(varname)
if (preg_match('/^var\((.+)\)$/', $op, $match)) {
$var = $match[1];
$stack->push($vars[$var]);
continue;
}
switch ($op) {
case '+':
$stack->push($stack->pop() + $stack->pop());
break;
case '-':
$n = $stack->pop();
$stack->push($stack->pop() - $n);
break;
case '*':
$stack->push($stack->pop() * $stack->pop());
break;
case '/':
$n = $stack->pop();
$stack->push($stack->pop() / $n);
break;
case '%':
$n = $stack->pop();
$stack->push($stack->pop() % $n);
break;
case '.':
// 输出文本
echo chr($stack->pop());
break;
case 'dup':
// 复制
$stack->push($stack->top());
break;
case 'ret':
// 函数 return
list($ip, $vars) = $calls->pop();
break;
case '.num':
// 输出数字本身
echo $stack->pop();
break;
default:
throw new InvalidArgumentException(sprintf('Invalid operation: %s', $op));
}
}
if (count($stack) > 0) {
return $stack->top();
}
}
/**
* shunting yard 算法,将中缀表达式转换为后缀表达式
* @param array $tokens
* @param array $operators
* @return array
*/
function shunting_yard(array $tokens, array $operators): array
{
$stack = new SplStack(); // 优先级低的先入栈
$output = new SplQueue();
foreach ($tokens as $token) {
if (is_numeric($token)) {
$output->enqueue($token);
} elseif (isset($operators[$token])) {
$operator1 = $token;
// 如果栈上已经存在操作符,且当前操作符比栈顶操作符优先级低,则入队栈顶操作符
while (
has_operator($stack, $operators)
&& ($operator2 = $stack->top())
&& has_lower_precedence($operator1, $operator2, $operators)
) {
$output->enqueue($stack->pop());
}
$stack->push($operator1);
} elseif ('(' === $token) {
$stack->push($token);
} elseif (')' === $token) {
while (count($stack) > 0 && '(' !== $stack->top()) {
$output->enqueue($stack->pop());
}
if (count($stack) === 0) {
throw new InvalidArgumentException(sprintf('Mismatched parenthesis in input: %s', json_encode($tokens)));
}
// pop off '('
$stack->pop();
} else {
throw new InvalidArgumentException(sprintf('Invalid token: %s', $token));
}
}
while (has_operator($stack, $operators)) {
$output->enqueue($stack->pop());
}
if (count($stack) > 0) {
throw new InvalidArgumentException(sprintf('Mismatched parenthesis or misplaced number in input: %s', json_encode($tokens)));
}
return iterator_to_array($output);
}
/**
* 栈上是否存在操作符
* @param SplStack $stack
* @param array $operators
* @return bool
*/
function has_operator(SplStack $stack, array $operators): bool
{
return count($stack) > 0 && ($top = $stack->top()) && isset($operators[$top]);
}
/**
* 判断操作符 $operator1 是否比 $operator2 优先级低
* @param $operator1
* @param $operator2
* @param array $operators
* @return bool
*/
function has_lower_precedence($operator1, $operator2, array $operators): bool
{
$operator1_info = $operators[$operator1];
$operator2_info = $operators[$operator2];
return ('left' === $operator1_info['associativity']
&& $operator1_info['precedence'] === $operator2_info['precedence'])
|| $operator1_info['precedence'] < $operator2_info['precedence'];
}
/**
* execute 测试函数
* @param string $code
* @param string $name
* @return void
*/
function execute_test(string $code = '', string $name = ''): void
{
$ops = preg_split('/\s/', preg_replace('/^\s*#.*$/m', '', $code), -1, PREG_SPLIT_NO_EMPTY);
$res = execute($ops);
echo "\nexecute ret: \t";
print_r($res);
echo "\n************************************************************\t{$name}\n";
}
/**
* shunting_yard 测试函数
* @param string $code
* @param string $name
* @return void
*/
function shunting_yard_test(string $code = '', string $name = ''): void
{
$ops = preg_split('/\s/', preg_replace('/^\s*#.*$/m', '', $code), -1, PREG_SPLIT_NO_EMPTY);
$res = shunting_yard($ops, operators);
print_r($res);
echo "\n************************************************************\t{$name}\n";
}
if ($_SERVER['PHP_SELF'] === __FILE__) {
// execute() test
$rpn = '2 3 * 1 +';
execute_test($rpn, 'execute()');
// shunting_yard() test
$rpn = '1 + 2 * 3';
shunting_yard_test($rpn, 'shunting_yard()');
// execute() && shunting_yard() test
$rpn = '2 3 * 1 +';
execute_test($rpn, 'execute()');
shunting_yard_test($rpn, 'shunting_yard()');
// io test
$code = '104 . 101 . 108 . 108 . 111 . 44 . 32 . 119 . 111 . 114 . 108 . 100 . 10 . 10';
execute_test($code, 'io');
// dup test
$code = '2 dup 5 + *';
execute_test($code, 'dup');
// label && jmp && jz test
$code = '
0 10 100 108 114 111 119 32 44 111 108 108 101 104
label(loop)
dup
jz(end)
.
jmp(loop)
label(end)';
execute_test($code, 'label && jmp && jz');
// use regular expression to strip whitespace
$code = '1 2
+';
execute_test($code, 'strip whitespace');
// strip comments
$code = '1
# 这是一个注释 1
2
# 这是一个注释 2
+';
execute_test($code, 'comments');
// calls
$code = '
jmp(start)
label(printstr)
label(loop)
dup jz(end)
.
jmp(loop)
label(end)
call(test)
ret
label(test)
104 . 101 . 108 . 108 . 111 . 44 . 32 . 119 . 111 . 114 . 108 . 100 . 10 . 0
ret
label(start)
0 10 100 108 114 111 119 32 44 111 108 108 101 104
call(printstr)
';
execute_test($code, 'calls');
// variables:从栈上 pop 一个值并保存到变量 varname,!var(varname),例如“42 !var(answer)”;将 varname 的值 push 到栈上,var(varname),例如“var(answer)”
$code = '
# i = 97
# ascii(97) is a
97 !var(i)
label(loop)
# print i
# i++
# jump if i == 123
# ascii(122) is z
var(i) .
var(i) 1 + !var(i)
var(i) 123 -
dup
jnz(loop)
# print \n
10 .
';
execute_test($code, 'variables');
// variables 2
$code = '
# define vars
10 !var(i)
0 !var(p)
1 !var(n)
0 !var(tmp)
# output i prev
var(i) .num 32 .
var(p) .num 10 .
# output i n
var(i) .num 32 .
var(n) .num 10 .
label(next)
var(i)
jz(end)
# tmp = n + p
# p = n
# n = tmp
var(p) var(n) + !var(tmp)
var(n) !var(p)
var(tmp) !var(n)
## output i n
var(i) .num 32 .
var(n) .num 10 .
# i--
var(i) 1 - !var(i)
# print ...
105 . 61 . var(i) .num 46 . 46 . 46 . 10 .
var(i)
jmp(next)
label(end)
';
execute_test($code, 'variables 2');
// stack frame
$code = '
jmp(start)
88 !var(i)
label(foo)
5 !var(i)
var(i) .num
ret
label(start)
11 !var(i)
call(foo)
var(i) .num
var(i) .num
';
execute_test($code, 'stack frame');
}
PHP 通过 FFI 与 C 交互
一门语言写的代码跟另一门语言交互一直是我很感兴趣的事情,既想用着让自己舒服的语言,又想使用其它语言在特定领域中强大的生态。当然通过网络接口来交互是最简单的方式,但需要写很多额外的代码。FFI(Foreign Function Interface)是用于与其它语言交互的接口,可以将其它语言的接口内嵌到本语言中,用起来就方便得多。
FFI是PHP核心代码的一部分,所以不需要担心后期没有人维护,放心大胆地使用吧。官方文档中提到访问FFI数据结构比访问原生PHP数组和对象慢很多(大约 2 倍)。因此使用FFI扩展来提高速度没有意义;减少内存消耗可能有意义。不过我使用FFI就是为了使用其它语言的生态,这个倒无所谓了。
FFI允许我们在PHP中加载共享库(.DLL或.so)、调用C函数、访问C数据结构,而无需深入了解Zend扩展API,也无需学习第三方“中间”语言。
简单的 FFI 示例
初次接触,先体验一下FFI的神奇之处吧。先自己写个简单的C代码,为了验证自己的想法,特意分成两个函数:
// add10.c
int actual_add10(int num) {
return num + 10;
}
int add10(int num) {
return actual_add10(num);
}
将其编译为共享库:
$ gcc --shared -o libadd10.so add10.c
下面就可以使用PHP调用add10函数了:
<?php
// add10.php
$ffi = FFI::cdef(
'int add10(int a);',
'libadd10.so'
);
$result = $ffi->add10(5);
echo $result, "\n";
执行结果如下:
$ php add10.php
15
FFI通过ABI(Application Binary Interface)将两门语言集成到一起。ABI定义了编译的C代码的二进制调用约定和数据结构,C-ABI约定也得到了其它非C语言的支持,如Rust,所以理论上如果一门语言支持C-ABI,那么PHP都可以通过FFI调用它写的库。
通过FFI可以做很多有意思的事,它令PHP几乎可以编写任何想要的代码,例如用PHP写桌面程序,绝大部分时间都不再需要跟复杂的Zend虚拟机打交道。
FFI + raylib 写图形程序
以下是一个通过FFI用PHP在Mac OS上做的图形程序,使用的是4.5.0版本的libraylib.dylib,是不是感觉像打开了新世界?纯粹的PHP也能写图形程序了。
<?php
// raylib.php
// 定义C语言库的结构体和函数
$ffi = FFI::cdef("
typedef struct Color {
unsigned char r, g, b, a;
} Color;
void InitWindow(int width, int height, const char* title);
int WindowShouldClose(void);
void ClearBackground(Color color);
void BeginDrawing(void);
void DrawText(const char* text, int x, int y, int fontSize, Color color);
void EndDrawing(void);
void CloseWindow(void);
", "/opt/homebrew/Cellar/raylib/4.5.0/lib/libraylib.dylib"); // 替换为你要使用的raylib库文件的路径
// 创建窗口并绘制文本
$ffi->InitWindow(800, 600, "Hello raylib from PHP");
$white = $ffi->new('Color');
$white->r = 255;
$white->g = 255;
$white->b = 255;
$white->a = 255;
$red = $ffi->new('Color');
$red->r = 255;
$red->g = 0;
$red->b = 0;
$red->a = 255;
while (!$ffi->WindowShouldClose()) {
$ffi->ClearBackground($white);
$ffi->BeginDrawing();
$ffi->DrawText("Hello raylib!", 400, 300, 20, $red);
$ffi->EndDrawing();
}
$ffi->CloseWindow();
运行:
用 if 和 goto 模拟 switch
很多编程语言都会有switch语句。switch作为选择语句的一种,也是可以用if-else语句来表示。在实现了switch的大部分编程语言中,通常跟break跳转语句配合来进行控制,其一般语法如下:
switch (expression) {
case constant1:
statements1;
break;
case constant2:
statements2;
break;
.
.
.
default:
defaultStatements;
}
switch语句的执行过程:首先计算expression的值,接着跟constant1进行比较,如果相等,则执行statements1直至遇到break语句,当遇到break语句时,也就意味着switch语句结束;如果没有遇到break语句,则会一直往下执行statements2…defaultStatements直至switch结束。
如果expression的值不等于constant1,则跟constant2进行比较,后续跟以上过程一样。
最后,如果expression的值跟所有的constant都不相等,如果存在default标签,程序就会执行default标签后的defaultStatements;否则结束。
以下是php的switch示例:
<?php
$expression = 'a';
switch ($expression) {
case 'a':
echo "expression == 'a'\n";
break;
case 'b':
echo "expression == 'b'\n";
break;
case 'c':
echo "expression == 'c'\n";
break;
default:
echo "expression do not match any cases\n";
}
break语句的作用是什么?跳转到switch语句的结束位置,我们可以用goto来模拟;至于case 'a'…default这些,看起来有点熟悉啊,这不就跟goto语句的标签参数一样吗?行动起来,改写吧。
为了让goto语句可以结束掉switch语句,我们得先给switch语句搞两个标签:SWITCH_BEGIN和SWITCH_END。至于case 'a'等等,就用CASE_A_BEGIN和CASE_A_END等对应的一组标签代替,default用DEFAULT_LABEL代替。
<?php
$expression = 'a';
SWITCH_BEGIN:
CASE_A_BEGIN:
goto SWITCH_END;
CASE_A_END:
CASE_B_BEGIN:
goto SWITCH_END;
CASE_B_END:
CASE_C_BEGIN:
goto SWITCH_END;
CASE_C_END:
DEFAULT_LABEL:
SWITCH_END:
现在看起来是不是像模像样了?条件比较在哪里?别着急,马上安排。
POSIX 终端屏保
最近在读一本书《PHP Beyond the Web》,内容难度不大,不过感觉挺有意思的。可能是做惯了web应用,或者说潜意识觉得PHP就是做web应用的,没想到在其它领域上,PHP也用得挺顺手,也许这也是一种偏见吧。看了这本书,对PHP有一些许改观,也算是扩展了视野。
在这里面看到一个挺好玩的小脚本,不过直接运行起来好像是有点小问题,于是在它的基础上改动了一下。
首先定义三个常量,\033在以前修改颜色时也用过,不过一直都是死记,其实它就是ESC的ASCII码。POSIX终端的转义指令可以实现颜色、光标移动等效果。其中ESC是转义字符,用于表示转义指令的开始,后面紧跟着指令代码。以下代码中的CLEAR常量是清空屏幕的指令,HOME常量用于移动光标的位置(屏幕左上角,第一个1表示行,第二个1表示列),RESET常量用于重置所有属性,包括关闭所有颜色和格式;另外[30m到[37m表示字体颜色,[40m到[47m表示背景颜色。此外,还有其它比较不常见的属性。
<?php
const ESC = "\033";
const CLEAR = ESC . "[2J";
const HOME = ESC. "[0;0f";
const RESET = ESC. "[0m";
接着,提示用户输入Enter键,程序读取输入。
// 注意:不用 echo 而用 fwrite,是因为 fwrite(STDOUT...) 写入到 php://stdout 流,而 echo(和 print)写入到 php://output 流。
// 虽然通常情况下它们都是一样的,但也不一定。
// 另外,php://output 是受输出控制以及缓冲的功能,这个功能可能是或者不是我们所希望的
fwrite(STDOUT, "Press Enter To Begin, And Enter Again To End");
// 等待用户按 Enter。STDIN 默认是阻塞流,这意味着我们尝试读取时,脚本会停止,并等待输入。
// 当用户按下 Enter 时,键盘输入到 shell 的内容会被传到我们的脚本(通过 fread)。
fread(STDIN, 1);
我们希望程序运行到用户再次输入Enter。这意味着我们想要通过fread不断检测输入,但如果没有输入时又不暂停/阻塞程序。因此,我们将STDIN设置为非阻塞。
stream_set_blocking(STDIN, 0);
在准备输出时,清空终端并在它的周围画一个方框。在PHP中没有内置的方法能获取终端大小,所以我们要调用外部的shell命令tput来获取终端的相关信息。
$rows = intval(`tput lines`);
$cols = intval(`tput cols`);
fwrite(STDOUT, CLEAR. HOME);
for ($rowcount = 1; $rowcount < $rows; $rowcount++) {
fwrite(STDOUT, sprintf("%s[%s;%sf•", ESC, $rowcount, 1));
fwrite(STDOUT, sprintf("%s[%s;%sf•", ESC, $rowcount, $cols));
}
for ($colcount = 1; $colcount <= $cols; $colcount++) {
fwrite(STDOUT, sprintf("%s[%s;%sf•", ESC, 1, $colcount));
fwrite(STDOUT, sprintf("%s[%s;%sf•", ESC, $rows-1, $colcount));
// 这里有个疑惑,如果不 usleep,输出就会不全,应该是输出缓冲的问题,但是目前试过很多方法都行不通。
// 在 windows 上的 docker 没有问题。不确定是不是仅在 macos iterm2 上有问题,有待确认
usleep(1000);
}
接着,就可以在上面画出的方框内进行屏保绘制了。
纯手工打造一个 JSON 解释器
老早就想搞一个完整的解释器,不过呢,通用语言的解释器比较庞大,不太好写。写一个 JSON 解释器比较合适,要素不多,好掌握一点,而且在忽略一些细节之后,代码量极少,对于入门者了解解释器甚至编译器到底在干什么很有帮助。
根据 https://www.json.org 的介绍,JSON 由以下结构组成:
- object: 无序的 name/value 键值对,以
{开始,以}结束,name 后跟着:,name/value 键值对由,分隔; - array: 有序的值集合,以
[开始,以]结束,值由,分隔; - value: 可以是位于两个
"之间的 string,或者是 true 、false、null、object、array,该结构可以嵌套; - string: 由双引号包裹的 0 个或多个 Unicode 字符序列,使用反斜杠
\转义。一个字符代表一个单字节字符串。字符串跟 C 或者 Java 的字符串类似; - number: 跟 C 或 Java 的数字类似,但是不使用八进制和十六进制的格式;
- whitespace: 可以出现在任何 token 对之间;
以下是一个完整的 JSON 解释器代码:
# json_parser.py
def parse_json(json_str):
index = 0
length = len(json_str)
def parse_value():
char = json_str[index]
if char == "{":
return parse_object()
elif char == "[":
return parse_array()
elif char == "\"":
return parse_string()
elif char == "t":
return parse_true()
elif char == "f":
return parse_false()
elif char == "n":
return parse_null()
else:
return parse_number()
def parse_object():
nonlocal index
obj = {}
index += 1
while index < length and json_str[index] != "}":
key = parse_string()
if index >= length and json_str[index] != "}":
raise "Expected ':'"
index += 1
val = parse_value()
obj[key] = val
if index < length and json_str[index] == ",":
index += 1
if index >= length:
raise "Unexpected end of input"
index += 1
return obj
def parse_array():
nonlocal index
index += 1
arr = []
while index < length and json_str[index] != "]":
val = parse_value()
arr.append(val)
if index < length and json_str[index] == ",":
index += 1
if index >= length:
raise "Unexpected end of input"
index += 1
return arr
def parse_string():
nonlocal index
index += 1
start = index
while index < length and json_str[index] != '"':
if json_str[index] == "\\":
index += 1
index += 1
if index >= length:
raise "Unexpected end of input"
index += 1
return json_str[start:index - 1]
def parse_true():
nonlocal index
if json_str[index:index + 4] == "true":
index += 4
return True
raise "Unexpected token: " + json_str[index:index + 4]
def parse_false():
nonlocal index
if json_str[index:index + 5] == "false":
index += 5
return False
raise "Unexpected token: " + json_str[index:index + 5]
def parse_null():
nonlocal index
if json_str[index:index + 4] == "null":
index += 4
return None
raise "Unexpected token: " + json_str[index:index + 5]
def parse_number():
nonlocal index
start = index
while index < length and json_str[index].isdigit():
index += 1
if index < length and json_str[index] == ".":
index += 1
while index < length and json_str[index].isdigit():
index += 1
if index < length and (json_str[index] == "e" or json_str[index] == "E"):
index += 1
if index < length and (json_str[index] == "+" or json_str[index] == "-"):
index += 1
while index < length and json_str[index].isdigit():
index += 1
return float(json_str[start:index])
return parse_value()
s = '{"name":"hello","int":1,"string":"True","arr":["a","你好",1.1,true,null,{"value":"haha"}],"bool":true}'
res = parse_json(s)
print(res)
print(res['arr'][1])
print(res['arr'][5]['value'])
运行结果如下:
A1 和 R1C1 引用列标签转换
Excel 关于引用有两种表示方法,即 A1 和 R1C1 引用样式。
A1 是 Excel 默认的引用类型。这种类型的列标签由字母标记(从 A 到 XFD,共 16384 列)。R1C1 类型中,列标签由数字标记。例如,A1 的列标签 A、B、C 分别对应 R1C1 列标签的 1、2、3。
以下代码中静态函数 A1toR1C1 将 A1 列标签转为 R1C1 类型,R1C1toA1 将 R1C1 列标签转为 A1 类型。
<?php
/**
* A1 与 R1C1 引用列标签转换
*/
class A1andR1C1Transfer
{
const AlphaCount = 26;
const BaseAlpha = 'A';
public static function A1toR1C1($A1Column): float|int
{
$A1ColumnLen = strlen($A1Column);
for ($i = $A1ColumnLen - 1, $pow = 0, $R1C1Column = 0; $i > -1; $i--, $pow++) {
$tmp = ord($A1Column[$i]) - ord(self::BaseAlpha) + 1;
$R1C1Column += $tmp * pow(self::AlphaCount, $pow);
}
return $R1C1Column;
}
public static function R1C1toA1($R1C1Column): string
{
$arr = [];
while ($R1C1Column > 0) {
$remain = ($R1C1Column -1) % self::AlphaCount;
array_unshift($arr, chr(ord(self::BaseAlpha) + $remain));
$R1C1Column = intval(($R1C1Column - $remain) / self::AlphaCount);
}
return implode('', $arr);
}
}
通过 JavaScript 了解异步
本文整理自MDN。
同步程序按照书写代码的顺序执行程序,假如其中一段代码耗时特别长,后续代码就一直无法执行。我们需要一种方法解决以上问题:
- 通过调用一个函数来启动一个长期运行的操作;
- 让函数开始操作并立即返回,这样我们的程序就可以保持对其他事件做出反应的能力;
- 当操作最终完成时,通知我们操作的结果;
以上能力就是异步为我们提供的能力。
事件处理程序
JavaScript 中的事件处理程序实际上就是异步编程的一种方式:你提供的函数(事件处理程序)将在事件发生时被调用(而不是立即被调用)。如果"事件"是"异步操作已经完成",那么你就可以看到事件如何被用来通知调用者异步函数调用的结果。
一些早期的异步 API 正是以这种方式来使用事件的。例如 XMLHttpRequest API 强以让你用 JavaScript 向远程服务器发起 HTTP 请求。
const xhr = new XMLHttpRequest()
xhr.timeout = 3000
xhr.ontimeout = function (ev) {
console.log(ev)
}
xhr.open('GET', 'https://www.google.com')
xhr.send()
console.log('last line')
以上代码会先输出"last line",再输出超时事件对象。
回调
事件处理程序是一种特殊类型的回调函数。而回调函数则是一个被传递到另一个函数中的会在适当时候被调用的函数。回调函数曾经是 JavaScript 中实现异步函数的主要方式。
由于"回调地狱"的问题,以及处理错误的困难,大多数现代异步 API 都不使用回调。事实上,JavaScript 中异步编程的基础是 Promise。
Promise
Promise 是现代 JavaScript 中异步编程的基础,是一个由异步函数返回的可以向我们指示当前操作所处的状态的对象。在 Promise 返回给调用者的时候,操作往往还没有完成,但 Promise 对象可以让我们操作最终完成时对其进行处理(无论成功还是失败)。
在基于 Promise 的 API 中,异步函数会启动操作并返回 Promise 对象。然后可以将处理函数附加到 Promise 对象上,当操作完成时(成功或失败),这些处理函数将被执行。
fetch() API 就是一个现代的、基于 Promise 的、用于替代 XMLHttpRequest 的方法。我们可以从中一窥 Promise 的用法。
const fetchPromise = fetch('http://localhost')
fetchPromise.then(res => {
console.log(res)
})
console.log('已发送')
“已发送"的消息在收到响应之前就被输出。这看起来跟 XMLHttpRequest 差不多,似乎只是将事件处理程序传给 then() 方法中罢了。
命令行覆盖刷新输出
命令行覆盖刷新输出的效果如下图。

覆盖刷新的原理:删除已输出字符(用空白字符屏蔽),重新输出新字符。
删除字符需要用到一个特殊字符\b退格符。注意:在很多语言里语言\b退格符跟键盘上的 Backspace 键不太一样,退格符仅仅是回退,并不会删除字符,因此回退后还需要使用一个空白字符覆盖原有字符,才能完成覆盖刷新功能。示例如下:
// go 1.16
package main
import (
"fmt"
"math/rand"
"time"
)
func str() string {
rand.Seed(time.Now().UnixNano())
strLen := rand.Intn(50)
chars := "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRST0123456789"
var ret []byte
for i := 0; i < strLen; i++ {
ret = append(ret, chars[rand.Intn(len(chars))])
}
return string(ret)
}
func clear(s string) {
for i := 0; i < len(s); i++ {
fmt.Print("\b \b")
}
}
func main() {
for i := 0; i < 100; i++ {
s := str()
fmt.Print(s)
time.Sleep(time.Millisecond * 200)
clear(s)
}
}
在 Go 语言中,其实fmt.Print("\b \b")有些多余,只需要fmt.Print("\b")即可。如果不确定使用的语言\b的行为如何,就统一用\b \b。
虚拟机实现原理
虚拟机是由软件实现的计算机。
以下是一个由 JavaScript 实现的虚拟机。
let virtualMachine = function(program) {
let programCounter = 0;
let stack = [];
let stackPointer = 0;
while (programCounter < program.length) {
let currentInstruction = program[programCounter];
switch (currentInstruction) {
case 'PUSH':
stack[stackPointer] = program[programCounter+1];
stackPointer++;
programCounter++;
break;
case 'ADD':
right = stack[stackPointer-1]
stackPointer--;
left = stack[stackPointer-1]
stackPointer--;
stack[stackPointer] = left + right;
stackPointer++;
break;
case 'MINUS':
right = stack[stackPointer-1]
stackPointer--;
left = stack[stackPointer-1]
stackPointer--;
stack[stackPointer] = left - right;
stackPointer++;
break;
}
programCounter++;
}
console.log("stacktop: ", stack[stackPointer-1]);
}
let program = [
'PUSH', 3,
'PUSH', 4,
'ADD',
'PUSH', 5,
'MINUS'
];
virtualMachine(program);
给 PHP 写 C 扩展
前期准备
源码编译安装 PHP。本文使用的是 PHP-8.1,其它版本可能会有所差异。
$ # 获取 PHP 源码并编译
$ git clone https://github.com/php/php-src.git
$ git checkout PHP-8.1
$ cd php-src
$ ./buildconf
$ ./configure
$ make
$ make install
生成扩展基本骨架
安装 PHP 之后,进入 PHP 源码的扩展目录,通过 PHP 提供的脚本生成扩展的基本骨架,hello为扩展名。
$ cd ext
$ php ext_skel.php --ext hello
添加自定义函数
以上脚本生成的扩展骨架其实已经在两个默认函数test1和test2了,我们尝试添加自己的函数test3。
$ cd hello
$ vim hello.c
在hello.c中添加函数test3:
// hello.c
PHP_FUNCTION(test3)
{
php_printf("Hello world from my first C extension\n");
}
除此之外,还要将函数原型添加到hello.stub.php中。
$ vim hello.stub.php
在以上的hello.stub.php中添加以下代码:
表达式解析
之前想写一篇《栈实现的表达式求值》,鸽了。这段时间又在学习编译原理,也有了一些想法,恰好看见Data Structure - Expression Parsing,如获至宝,感觉有点意思。
算术表达式可以使用三种不同但效果等效的的表示法来表示。这些表示法如下:
- 中缀表示法
- 前缀表示法(波兰表示法)
- 后缀表示法(逆波兰表示法)
中缀表示法(Infix Notation)
例如a - b + c,操作符位于操作数之间,这种表示法对人类友好,但对计算机不友好。处理中缀表示法的算法可能难度比较高并且在消耗大量时间和空间。
前缀表示法(Prefix Notation)
这种表示法的操作符位于操作数之前,例如+ a b等同于中缀表示法的a + b。中缀表示法也叫波兰表示法。
后缀表示法(Postfix Notation)
这种表示法也叫逆波兰表示法,操作符在操作数之后,例如a b +等于同中缀表示法的a + b。
以下表格简明地展示了三种表示法的差异。
| Sr.No | Infix Notation | Prefix Notation | Postfix Notation |
|---|---|---|---|
| 1 | a + b | + a b | a b + |
| 2 | (a + b) * c) | * + a b c | a b + c * |
| 3 | a * (b + c) | * a + b c | a b c + * |
| 4 | a / b + c / d | + / a b / c d | a b / c d / + |
| 5 | (a + b) * (c + d) | * + a b + c d | a b + c d + * |
| 6 | ((a + b) * c) - d | - * + a b c d | a b + c * d - |
解析表达式
专门为中缀表示法设计算法或程序并不是高效的方式。事实上,这些中缀表示法会先转化为后缀或前缀表示法再进行计算。
对 Coroutine 的不成熟理解
在需要恢复控制权的位置设置一系列 label:一个位于开始位置,另一个在每个 return 语句后面。我们还设置了一个 state 变量,用于在多次函数调用时告诉我们下次应该在哪里恢复控制权。在每次返回前,都需要更新 state 变量,使其指向正确的 label。而在调用后,我们都会通过 switch 对 state 进行判断,以便找到下一次要跳转的 label。
#include <stdio.h>
int function(void) {
static int i, state = 0;
switch (state) {
case 0: goto LABEL0;
case 1: goto LABEL1;
}
LABEL0: /* start of function */
for (i = 0; i < 10; i ++) {
state = 1; /* so we will come back to LABEL1 */
return i;
LABEL1:; /* resume control straight after the return */
}
}
int main() {
printf("%d\n", function());
printf("task 1\n");
printf("%d\n", function());
printf("task 2\n");
printf("%d\n", function());
printf("task 3\n");
return 0;
}
但是,上面的代码是丑陋的。其实最糟糕的部分就是需要手动维护一组 label,并且必须放在函数体之间且需要 switch 语句。我们每添加一个 return 说一句,都必须创建一个新的 label 并将其添加到 switch 中;每移除一个 return 语句,都必须移除其对应的 label。这额外增加了我们两倍的工作量。
Base64 编码原理及实现
参考 RFC4648
以上的 RFC 描述了几种常用的编码方案:Base64,Base32 和 Base16。数据的 Base 编码用于多种存储或者传输场景中,例如图片的传输,其中以 Base64 尤为常见。
Base64 编码
Base64 编码使用了 US-ASCII 的一个子集 —— 65 个字符,将每 6 位数据都表示成一个可打印字符,额外的第 65 个字符=表示一种特殊的处理。编码的过程 —— 用 4 个作为输出的编码字符表示 1 个 24 位输入组。1 个 24 位输入组由 3 个连续的 8 位输入组组成,这 24 位的输入组又被当作 4 个 6 位的输出组(每个输出位组都被翻译成 1 个单独的 Base64 编码字符)。
每 1 个 6 位输出组都是 64 个可打印字符的索引值。例如000000(值 0)表示A。Base64 编码字符如下表所示:
| 字符 | 值 | 字符 | 值 | 字符 | 值 | 字符 | 值 |
|---|---|---|---|---|---|---|---|
| A | 0 | Q | 16 | g | 32 | w | 48 |
| B | 1 | R | 17 | h | 33 | x | 49 |
| C | 2 | S | 18 | i | 34 | y | 50 |
| D | 3 | T | 19 | j | 35 | z | 51 |
| E | 4 | U | 20 | k | 36 | 0 | 52 |
| F | 5 | V | 21 | l | 37 | 1 | 53 |
| G | 6 | W | 22 | m | 38 | 2 | 54 |
| H | 7 | X | 23 | n | 39 | 3 | 55 |
| I | 8 | Y | 24 | o | 40 | 4 | 56 |
| J | 9 | Z | 25 | p | 41 | 5 | 57 |
| K | 10 | a | 26 | q | 42 | 6 | 58 |
| L | 11 | b | 27 | r | 43 | 7 | 59 |
| M | 12 | c | 28 | s | 44 | 8 | 60 |
| N | 13 | d | 29 | t | 45 | 9 | 61 |
| O | 14 | e | 30 | u | 46 | + | 62 |
| P | 15 | f | 31 | v | 47 | / | 63 |
如果要输入数据剩下的位数少于 24,就会进行特殊的处理(位0会被添加到数据的右边以使位数是 6 位组的整数倍),并在数据的末端使用=字符填充。
算法中的哨兵
在地面上有200个箱子连续排列着,现在需要看一下前面100个箱子中有没有苹果。一般情况下,会怎么做呢?
下面用代码来模拟一下。
package main
import (
"fmt"
)
func main() {
s := make([]int, 200)
for i := 0; i < 100; i++ {
if s[i] == -1 {
fmt.Println("苹果")
break
}
}
}
如代码所示,我们需要从第1个箱子开始找,每打开一个箱子都要判断一下该箱子是不是前100个,然后再看看里面有没有苹果(-1)。一切都那么自然,但有没有更好的办法呢?
每次都打开箱子看看里面有没有苹果,这应该是不能省略的步骤;至于判断箱子是不是前100个,我们可以在前100个的位置划条边界,但似乎还是没有什么改变,还是要每次看一下是不是到了边界。再想想,每次打开箱子都要看一下有没有苹果,如果看到苹果就会停止,这就有文章可作了。我们就在第101个箱子里面放一下苹果,这样在第101个箱子就必然会停止找箱子,只要在找到苹果之后看了下苹果所在的箱子是不是第101个箱子就行了。
package main
import (
"fmt"
)
func main() {
s := make([]int, 200)
s[100] = -1
for i := 0; ; i++ {
if s[i] == -1 {
if i != 100 {
fmt.Println("苹果")
}
break
}
}
}
以上代码每次循环都少了判断i < 100,取而代之的是在找到苹果(-1)后再判断i != 100。以上的s[100] = -1就是哨兵,哨兵守卫着代码的边界,避免了越界的可能。哨兵的存在,意味着程序可以大大减少执行时间。
package main
import (
"fmt"
"time"
)
func main() {
s := make([]int, 100000000)
t1 := time.Now().UnixNano()
for i := 0; i < len(s); i++ {
if s[i] == -1 {
fmt.Println("苹果")
break
}
}
t2 := time.Now().UnixNano()
fmt.Println(t2 - t1)
s2 := append(s, -1)
t3 := time.Now().UnixNano()
for i := 0; ; i++ {
if s2[i] == -1 {
if i != len(s) {
fmt.Println("苹果")
}
break
}
}
t4 := time.Now().UnixNano()
fmt.Println(t4 - t3)
}
$ go run main.go
706820000
260953000
哨兵,哨兵,你真了不得。
JSON Web Token 实现
结构
JSON Web Token 由.分隔为三个部分,分别是:
HeaderPayloadSignature
如Header.Payload.Signature。
Header
Header 由两部分组成,签名算法和令牌类型,签名算法有 HMAX SHA256 或 RSA 等,令牌类型则是 JWT。如下所示:
{
"alg": "HS256",
"typ": "JWT"
}
Payload
Payload 里存放的是实际传送的数据。其中有几个字段是官方推荐的,括号中是字段的全称:
- iss(Issuer)
- sub(Subject)
- aud(Audience)
- exp(Expiration Time)
- nbf(Not Before)
- iat(Issued At)
- jti(JWT ID)
当然,以上字段并非强制使用,完全可以自定义字段。例如:
{
"sub": "1234567890",
"name": "John Doe",
"iat": 1516239022
}
Signature
签名需要指定算法。以下是默认的 HMACSHA 算法签名方式,将以上的 Header 和 Payload 经过 base64Url 编码,再用.进行拼接,secret 指定的密钥。签名用于验证消息没有被更改。
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret)
合并
将以上的 Header、Payload、Signature 分别进行 base64Url 编码,用.进行拼接,最后形成 JSON Web Token。
实现
以下代码是官网示例的简版实现,使用了默认算法 HS256 进行签名。
WebSocket 原理探究
WebSocket 究竟是什么东西呢?貌似有人看到 WebSocket 里面有 Socket 就以为它跟 Socket 有什么关系。呃,要真说它们有什么关系,也确实有,WebSocket 跟 Socket 之间还隔着一层 HTTP,姑且算是有关系吧。
WebSocket 协议是基于 HTTP 实现的,具体来说,WebSocket 通过 HTTP 实现握手,握手之后就没 HTTP 什么事了。
为了深刻理解 WebSocket 原理,我特意写了个 WebSocket 服务,目前仅能握手、接发简短的文本信息,但用于简单说明 WebSocket 工作机制已经足够了。
package main
import (
"crypto/sha1"
"encoding/base64"
"fmt"
"io"
"log"
"net"
"strings"
)
const Series = "258EAFA5-E914-47DA-95CA-C5AB0DC85B11"
func main() {
S()
}
func S() {
l, err := net.Listen("tcp", "localhost:9999")
if err != nil {
log.Fatal(err)
}
log.Printf("listening %s...", l.Addr())
for {
conn, err := l.Accept()
if err != nil {
log.Println(err)
continue
}
log.Printf("%s accepted...", conn.RemoteAddr())
go handleS(&conn)
}
}
func handleS(conn *net.Conn) {
log.Printf("handling %s...", (*conn).RemoteAddr())
buf := make([]byte, 1024)
// demo 默认一次读完
n, err := (*conn).Read(buf)
if err != nil {
log.Println(err)
}
lines := strings.Split(string(buf[:n]), "\r\n")
headers := map[string]string{}
for _, line := range lines {
// headers
row := strings.Split(line, ":")
if len(row) == 2 {
key := strings.TrimSpace(row[0])
val := strings.TrimSpace(row[1])
headers[key] = val
}
}
_, hasConnection := headers["Connection"]
_, hasUpgrade := headers["Upgrade"]
if hasConnection && hasUpgrade {
// handshake
key := headers["Sec-WebSocket-Key"]
str := key + Series
src := sha1.Sum([]byte(str))
dst := base64.StdEncoding.EncodeToString(src[:])
_, err := (*conn).Write([]byte(fmt.Sprintf("%s\r\n%s\r\n%s\r\n%s\r\n%s\r\n%s%s\r\n\r\n",
"HTTP/1.1 101 Switching Protocols",
"Connection: Upgrade",
"Upgrade: websocket",
"Server: Go",
"Sec-WebSocket-Version: 13",
"Sec-WebSocket-Accept: ",
dst)))
if err != nil {
log.Println(err)
}
go handleWebsocket(conn)
} else {
_, err := (*conn).Write([]byte(fmt.Sprintf("%s\r\n%s\r\n%s\r\n\r\n%s",
"HTTP/1.1 400 Bad Request",
"Server: Go",
"Content-Length: 15",
"400 Bad Request")))
if err != nil {
log.Println(err)
}
// TODO
log.Printf("close bad request %s...", (*conn).RemoteAddr())
defer (*conn).Close()
}
}
func handleWebsocket(conn *net.Conn) {
defer (*conn).Close()
buf := make([]byte, 1024)
for {
n, err := (*conn).Read(buf)
if err != nil {
if err == io.EOF {
log.Printf("close websocket %s...", (*conn).RemoteAddr())
break
}
log.Println(err)
continue
}
fmt.Printf("recvData: %#x\n", buf[:n])
var maskKey []byte
for k, v := range buf[:n] {
// k 为第 k+1 个字节
switch k {
case 0:
// FIN,1位,0x80 表示结束
fmt.Printf("fin: %#x\n", v&0b10000000)
// RSV1/RSV2/RSV3,共3位
fmt.Printf("RSV: %#x\n", v&0b01110000)
// OPCODE,4位,1 表示文本数据;2 表示二进制数据帧
fmt.Printf("opcode: %#x\n", v&0b00001111)
case 1:
// MASK,1位,表示是否使用掩码
fmt.Printf("mask: %#x\n", v&0b10000000)
// payload len,7位,最大值为 2^7 = 127,如果值为 0-125,则是 payload 的真实长度;如果值为 126,则后面的两字节表示的无符号整才是真正的 payload len;
// 如果值为 127,则后面的八字节表示的无符号整数才是真正的 payload len
fmt.Printf("payload len: %#x\n", v&0b01111111)
case 2:
// nothing to do
case 3:
// nothing to do
case 4:
// nothing to do
case 5:
// mask-key,4字节
maskKey = buf[2:6]
fmt.Printf("mask-key: %#x\n", buf[2:6])
case len(buf[:n]) - 1:
// payload
fmt.Printf("payload: ")
//fmt.Printf("%#x\n", buf[6:n])
for k, v := range buf[6:n] {
fmt.Printf("%c", maskKey[k%4]^byte(v))
}
fmt.Println()
}
}
fmt.Printf("\n")
sendPayload := []byte{'w', 'o', 'r', 'l', 'd'}
sendData := []byte{
0b10000001, 0b00000101,
}
sendData = append(sendData, sendPayload...)
fmt.Printf("sendData: %#x(%s)\n", sendData, sendData)
(*conn).Write(sendData)
}
}
简单解释一下以上代码。Socket 代码自不必多说,Accept 连接之后,需要对接收到的消息进行判断,如果有Connection: Upgrade和Upgrade: websocket请求头的话,则进入 WebSocket 握手处理。WebSocket 握手时,HTTP 报文还会带上Sec-WebSocket-Key请求头,这个 Key 值是由客户端随机生成的(也是经过 base64 编码的),我们将这个 Key 拼接上258EAFA5-E914-47DA-95CA-C5AB0DC85B11,这个字符串是固定的,用这个串的原因得查一下 RFC 才知道了;接着将拼接之后的字符串进行 sha1 散列,最后再 base64 编码。我们回复握手报文至此已经准备好了,将上面生成的 base64 编码字符中添加到Sec-WebSocket-Accept响应头上,其它内容可以固定,当然也可以加上其它响应头,但现在这样的代码足够让实验成功了。
连接池的实现原理
连接池是什么东西?所谓连接,指的是TCP连接,而池,则是容器,普通的池子可以容纳水等物体,而连接池,则是容纳TCP连接的容器。
现实中的容器可以是多种材质的,连接池也不例外,连接池可以用各种数据结构来实现,只要能保存并允许使用连接即可。为了方便,本文仅用一个变量来模拟连接池。以下是完整的示例。
package main
import (
"flag"
"fmt"
"io"
"log"
"net"
"strconv"
"sync"
"time"
)
type Pool struct {
conn net.Conn
mutex sync.Mutex
}
var pool Pool
func initPool(addr string) {
conn, err := net.DialTimeout("tcp", addr, time.Minute*5)
if err != nil {
log.Fatal(err)
}
pool.conn = conn
}
func main() {
t := flag.String("type", "client", "APP type")
flag.Parse()
switch *t {
case "server":
l, err := net.Listen("tcp", ":45920")
if err != nil {
log.Fatal(err)
}
defer l.Close()
conn, err := l.Accept()
if err != nil {
log.Fatal(err)
}
defer conn.Close()
for {
received := make([]byte, 1024)
n, err := conn.Read(received)
printLog(err)
fmt.Printf("received: %s\n", received[:n])
separator()
_, err = conn.Write([]byte("From server: " + time.Now().String()))
printLog(err)
}
case "tunnel":
initPool("localhost:45920")
l, err := net.Listen("tcp", ":45930")
if err != nil {
log.Fatal(err)
}
defer l.Close()
for {
conn, err := l.Accept()
if err != nil {
log.Println(err)
continue
}
go handleConn(conn)
}
case "client":
for i := 0; i < 10; i++ {
client, err := net.Dial("tcp", "localhost:45930")
if err != nil {
log.Fatal(err)
}
_, err = client.Write([]byte("Hello world from client " + strconv.Itoa(i)))
if err != nil {
log.Println(err)
continue
}
received := make([]byte, 1024)
n, err := client.Read(received)
printLog(err)
fmt.Printf("%s\n", received[:n])
separator()
}
}
}
func printLog(err error) {
if err != nil && err != io.EOF {
log.Println(err)
}
}
func separator() {
fmt.Println("======================================================================")
}
func handleConn(conn net.Conn) {
defer conn.Close()
received := make([]byte, 1024)
n, err := conn.Read(received)
if err != nil && err != io.EOF {
log.Println(err)
return
}
fmt.Printf("received from client: %s\n", received[:n])
separator()
pool.mutex.Lock()
defer pool.mutex.Unlock()
n, err = pool.conn.Write(received[:n])
if err != nil {
log.Println(err)
return
}
n, err = pool.conn.Read(received)
if err != nil && err != io.EOF {
log.Println(err)
return
}
fmt.Printf("received from server: %s\n", received[:n])
separator()
n, err = conn.Write(received[:n])
if err != nil {
log.Println(err)
return
}
fmt.Println("end")
}
测试方法如下:
Web 终端实现原理
平时看到各种云平台提供的 Web 终端操作页面,觉得还挺有意思,恰好最近要实现一个类似的玩意。
由于前端不是我擅长的方向,所以我的前端并没有使用什么高大上的东西,也没有什么美观可言,仅仅使用了 WebSocket 进行命令的传输(可以用 xterm.js 来做前端,有空再玩玩吧)。终端的关键在于命令的处理,压力都来到 WebSocket 服务端这边。
最初的方案是打算在所有的远程服务器都部署专门处理命令的服务,而 WebSocket 服务端则将命令发送给该服务,这有点像 noVNC 了吧,不过这个方案实在是太繁琐了,而且远程服务器有增减时徒增工作。当然,远程服务器能被控制,必须需要向外提供服务,既然自己做的服务麻烦,何不使用服务器普遍都有的服务 SSH 呢?于是方案最终确定为"WebSocket+SSH"。以下就是整个服务的工作流程图。
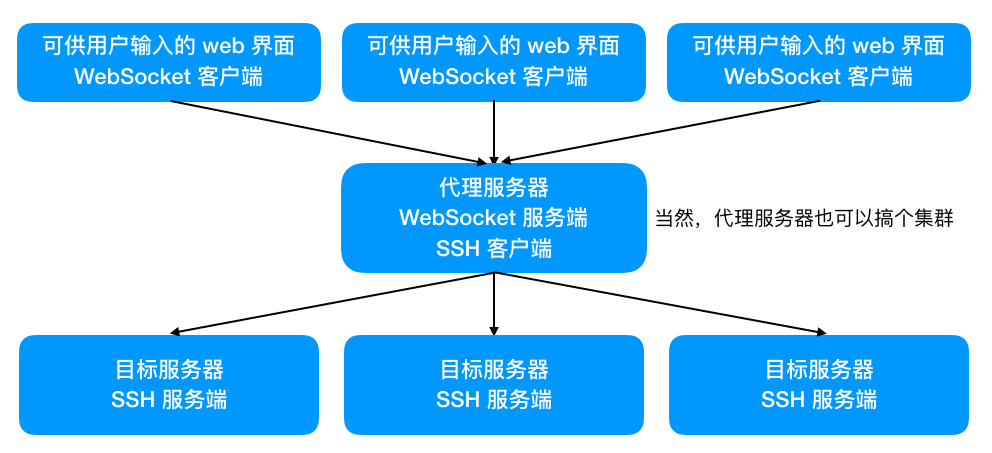
其实最初的方案跟最终的方案相差并不大,主要是代理服务器和目标服务器之间的传输协议不同罢了,工作流程是一致的。
具体的工作流程:用户使用 SSH 密钥登录,成功之后代理服务端已经为用户提前准备好了 SSH 连接;接着使用 token 来建立 WebSocket 连接,这时代理服务端就可以通过 token 对 WebSocket 连接和 SSH 连接进行关联;假设用户输入的命令没有经过任何处理,WebSocket 服务端将协议消息解析得到命令之后就可以直接通过 SSH 连接转发给远程服务器;命令的执行结果沿着反方向传输到用户的页面上。
在汇编中重新认识函数
一个简单的 8086 汇编子程序(函数)。
assume cs:code
code segment
main: mov ax, 1000h
call add1
mov ax, 4c00h
int 21h
add1: add ax, 1
ret
code ends
end main
- 标号
main可以简单地理解为 C 语言中的 main 函数等入口函数; - 标号
add1是函数 add1 的地址; - 指令
call add1调用add1函数。在汇编中,call add1具体操作:将当前地址CS:IP压入栈SS:SP(这就是传说中的栈帧的由来吧?)中,接着转到add1开始执行; - 标号
add1执行完add ax, 1之后,指令ret会将上一步中保存到SS:SP栈顶的地址传到CS:IP,再将该地址出栈; - 函数
add1执行完毕。 - 指令
mov ax, 4c00h、int 21h退出程序。
对以上汇编代码进行处理。
汇编
链接
调试
在这段代码中,我们重点关注 ax 寄存器。
-
上图中的
-r、-t等是输入的命令,-相当于输入的提示符,r、t才是实际输入的字符;在每个输出中的最后显示的是下一个将要执行的汇编指令,如MOV AX,1000。 -
r查看当前寄存器状态。ax 初始值为 FFFF,下面将要执行的代码是MOV AX, 1000。 -
t执行指令,并显示最新的寄存器状态。
汇编级调试程序 debug
其实本文并不是主要介绍 debug 用法的。。。
最近看了两本汇编的书,里面都提到 debug.exe。写代码嘛,肯定要实践一下,可惜电脑上并没有 debug.exe 了,所以为了方便学习,特意记录一下怎么在 win10 和 macOS(10.14.3) 上搞出 debug.exe。
debug.exe 属于久远的 dos 时代,所以得先搞个 dos 环境呗,dosbox 就是 dos 的模拟器,直接在官网 https://www.dosbox.com/ 下载安装即可。
Win10
这里我用的是 [DOSBox0.74-3-win32]({{ site.url }}/assets/files/DOSBox.exe.zip)。
debug.exe 需要另外下载,现在网上乱七八糟的,我就直接上传到这了,[下载debug]({{ site.url }}/assets/files/debug.exe.zip)。下载之后将 debug.exe 放在自己喜欢的目录中,例如D:\Debug。
进入 dosbox 的安装目录,例如D:\Software\dosbox;运行目录中的DOSBox 0.74-3 Options.bat,之后会弹出一个配置文件,如dosbox-0.74-3.conf,这时在文件末尾加上如下配置:
MOUNT C D:\Debug
C:
debug
其中MOUNT是挂载,C是参数,D:\Debug是 debug.exe 所在目录,其它照抄就得,不用深究了,毕竟只是为了使用 debug.exe。
现在一切就绪,打开 Dosbox.exe,在光标处输入dss:0后按回车,出现下图界面即搭建成功。
最后,写条汇编练练手。
输入a进入汇编模式,接着输入汇编mov ax,ds将代码段地址传到 ax 寄存器中,r查看寄存器,t进行追踪,可以发现汇编生效了,ax 寄存器的值跟 ds 一致。
debug.exe 更多的用法可输入?进行查看。
macOS 10.14.3
在官网下载,也可以直接在这里下载[DOSBox-0.74-3-3]({{ site.url }}/assets/files/DOSBox.dmg.zip)。
将debug.exe放在喜欢的目录,如/Users/wu/Bin。
运行比较简单,直接点击打开,使用mount C /Users/wu/Bin挂载即可,然后就可以使用 debug,其它操作跟 Win10 一致。
生产者-消费者模型与订阅-发布模型
生产者/消费者模型
简单来说,生产者生产一些数据,然后放到队列中,同时消费者从队列中取数据。这样就让生产和消费变成了异步的两个过程。当队列中没有数据时,消费者就进入饥饿的等待中;而队列中数据已满时,生产者则面临因产品积压导致 CPU 被剥夺的问题。
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
"time"
)
// 生产者
func Producer(factor int, out chan <- int) {
for i := 0; ; i++ {
out <- i*factor
time.Sleep(time.Second)
}
}
// 消费者
func Consumer(in <- chan int) {
for v := range in {
fmt.Println(v)
}
}
func main() {
ch := make(chan int, 64)
go Producer(3, ch)
go Producer(5, ch)
go Consumer(ch)
// Ctrl+C 退出
sig := make(chan os.Signal, 1)
signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM)
fmt.Printf("quit (%v)\n", <- sig)
}
订阅/发布模型
订阅/发布(publish-subscribe)模型跟生产者/消费者模型有很多相似之处,发布者好比生产者,订阅者好比消费者。生产者和消费者是 M:N 的关系。而在传统生产者/消费者模型中,是将消息发送到一个队列中,而发布/订阅模型则是将消息发布给一个主题。
// pubsub/pubsub.go
package pubsub
import (
"sync"
"time"
)
type (
subscriber chan interface{} // 订阅者为一个通道
topicFunc func(v interface{}) bool // 主题为一个过滤器
)
type Publisher struct {
m sync.RWMutex // 读写锁
buffer int // 订阅队列的缓存大小,如果订阅者通道中的消息超过 buffer,则会丢失该消息
timeout time.Duration // 发布超时时间
subscribers map[subscriber]topicFunc // 订阅者列表
}
// 构建一个发布者对象,可以设置发布超时时间和发布队列的长度
func NewPublisher(publishTimeout time.Duration, buffer int) *Publisher {
return &Publisher{
buffer: buffer,
timeout: publishTimeout,
subscribers: make(map[subscriber]topicFunc),
}
}
// 添加一个新的订阅者,订阅全部主题
func (p *Publisher) Subscribe() chan interface{} {
return p.SubscribeTopic(nil)
}
// 添加一个新的订阅者,订阅过滤器筛选后的主题
func (p *Publisher) SubscribeTopic(topic topicFunc) chan interface{} {
ch := make(chan interface{}, p.buffer)
p.m.Lock()
p.subscribers[ch] = topic
p.m.Unlock()
return ch
}
// 退出订阅
func (p *Publisher) Evict(sub chan interface{}) {
p.m.Lock()
defer p.m.Unlock()
delete(p.subscribers, sub)
close(sub)
}
// 发布一个主题。遍历所有订阅者,将消息发送到订阅者通道
func (p *Publisher) Publish(v interface{}) {
p.m.RLock()
defer p.m.RUnlock()
var wg sync.WaitGroup
for sub, topic := range p.subscribers {
wg.Add(1)
go p.sendTopic(sub, topic, v, &wg)
}
wg.Wait()
}
// 发布主题,可以容忍一定的超时。其实就是将发布的消息发送到订阅者通道中
func (p *Publisher) sendTopic(sub subscriber, topic topicFunc, v interface{}, wg *sync.WaitGroup) {
defer wg.Done()
// 存在订阅回调,但是回调失败,直接返回
if topic != nil && !topic(v) {
return
}
// 将消息发送到订阅通道中,超时退出
select {
case sub <- v:
case <-time.After(p.timeout):
}
}
// 关闭发布者对象,同时关闭所有的订阅者通道
func (p *Publisher) Close() {
p.m.Lock()
defer p.m.Unlock()
for sub := range p.subscribers {
delete(p.subscribers, sub)
close(sub)
}
}
// main.go
package main
import (
"fmt"
"github.com/lwlwilliam/test/go/pubsub"
"os"
"os/signal"
"strings"
"syscall"
"time"
)
func main() {
p := pubsub.NewPublisher(100*time.Millisecond, 5)
defer p.Close()
all := p.Subscribe()
world := p.SubscribeTopic(func(v interface{}) bool {
if s, ok := v.(string); ok {
return strings.Contains(s, "world")
}
return false
})
p.Publish("Hello world 1")
p.Publish("Hello william 2")
p.Publish("Hello world 3")
p.Publish("Hello world 4")
p.Publish("Hello world 5")
p.Publish("Hello world 6") // 由于 all 通道满了,所以 all 会丢失该消息
p.Publish("Hello world 7") // 由于 world 通道也满了,所以 all 和 world 均会丢失该消息
go func() {
for msg := range all {
fmt.Println("all:", msg)
}
}()
go func() {
for msg := range world {
fmt.Println("world:", msg)
}
}()
time.Sleep(3 * time.Second)
p.Publish("Hello world 8") // 正常情况下,睡眠 3 秒后,all 和 world 通道都清空缓存了,所以 all 和 world 均会订阅成功
// Ctrl+C 退出
sig := make(chan os.Signal, 1)
signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM)
fmt.Printf("quit (%v)\n", <-sig)
}
生产者/消费者模型和订阅/发布模型的关系,类似于网络协议中的"pull"协议和"push"协议;生产者/消费者模型的数据传输不需要生产者发送给消费者,而是消费者主动"pull"数据;订阅/发布模型需要发布者将数据"push"给订阅者。
静态库和动态库
顾名思义,静态库可以理解为该库相对于可执行目标文件是静态的,而动态库相对于可执行文件是动态的。静态库跟可执行文件捆绑在一起,不需要依赖操作系统中其它库;动态库则一般固定在操作系统的特定位置,如/usr/lib目录中,如果可执行文件依赖于动态库,一旦该库被移动或损坏,则无法运行。有兴趣可以进行以下测试,我使用的是 docker 中的容器,可千万别用自己的系统试。
root@b64869b93f5d:~# mv /usr/lib/ /usr/lib.bak
root@b64869b93f5d:~# mv /usr/lib.bak/ /usr/lib
mv: error while loading shared libraries: libacl.so.1: cannot open shared object file: No such file or directory
第一次mv时一切正常,第二次mv时却提示mv: error while loading shared libraries: libacl.so.1: cannot open shared object file: No such file or directory。就是在加载共享库时发生错误,找不到libacl.so.1这个库。之所以出现这种错误,就是mv命令使用了动态库libacl.so.1,而这个动态库就在/usr/lib中,由于修改了该目录名,就不能通过目录链接到该库。
通过以上测试,可以对动态库的原理进行简单的推断了:使用了动态库的可执行程序,并不需要将该库编译到可执行文件中,只需要知道这些库在磁盘的具体路径即可,在运行时,再通过路径来加载动态库。
静态库跟动态库相反,会直接将库链接到可执行文件中,省略了运行时寻找库这一步骤。
接下来通过两段 cgo 代码看看两者具体的区别。
number 库
创建number/number.h。
// number/number.h
int number_add_mod(int a, int b, int mod);
创建number/number.c。
// number/number.c
#include "number.h"
int number_add_mod(int a, int b, int mod) {
return (a+b)%mod;
}
静态库
生成libnumber.a静态库,.a指archived。
文件中的魔数
跟 Windows 不同,在 Linux 中的文件扩展名仅仅是方便用户肉眼判断类型而已,将扩展名换掉并不会影响使用。
本质上,所有文件的内容都是以二进制保存的。程序之所以能将文件识别成不同的类型,无非就是不同类型的文件内容有区别于其他类型的特征。举个简单的例子,现在有一个系统,文件类型只有两种,那我们就可以将文件的第一个字节用于区分类型,将第一个字节为0000都视为同一类型的文件,第一个字节为0001的视为另一种文件。这个字节我们就称之为魔数,这种情况下,魔数用于区分文件类型。
现在通过 Linux 系统的file命令来看看这个魔数是怎么影响类型的。如下,创建一个名为helloworld.jpeg的文件,通过file命令知道这是一个 ASCII 编码的文本文件。
$ echo 'Hello world' > helloworld.jpeg
$ file helloworld.jpeg
helloworld.jpeg: ASCII text
接着,用vim -b命令以二进制模式打开文件,将在vim的命令模式下输入:%!xxd并回车。
$ vim -b helloworld.jpeg
Hello world
:%!xxd
以上操作之后,我们会看到现在的文件内容如下,这时需要谨慎操作。
00000000: 4865 6c6c 6f20 776f 726c 640a Hello world.
如下,将文件中的4865 6c6c...640a这些内容替换为以下的ffd8 ffe0...0001。注意,不要有多余的输入(包括空格)。
00000000: ffd8 ffe0 0010 4a46 4946 0001 0100 0001 Hello world.
然后,进入命令模式,输入命令:%!xxd -r并回车。
00000000: ffd8 ffe0 0010 4a46 4946 0001 0100 0001 Hello world.
:%!xxd -r
以上命令结束后,应该会看到内容又变了,如下。这时可以接着输入:wq命令保存退出了。
<ff><d8><ff><e0>^@^PJFIF^@^A^A^@^@^A
:wq
最后,再次用file看看文件类型,如无意外,应该跟下面的结果一样是 JPEG 图片格式。
栈实现的表达式求值
后进者先出,先进者后出,这就是数据结构中的"栈"。栈是一种相当简单的数据结构,但应用十分广泛,例如编程语言中的函数调用栈、浏览器的前进后退功能。本文讲的是栈的另一个常见应用场景,编译器利用栈实现表达式求值。初次见到这种实现思路的时候,我不禁叫绝,一个简单的栈还能玩出花。
例如,一个简单的四则运算:10+20*2-30/3。人脑算出这个表达式的结果很简单。但是计算机只认识简单的机器指令。那么我们怎么将这个"复杂"的表达式编译成更接近机器的语言呢?
实际上,编译器就是通过两个栈来实现的。其中一个保存操作数的栈,另一个是保存运算符的栈。我们从左向右遍历表达式,当遇到数字,我们就直接压入操作数栈;当遇到运算符,就与运算符栈的栈顶元素进行比较。
如果比运算符栈顶元素的优先级高,就将当前运算符压入栈;如果比运算符栈顶元素的优先级低或者相同,从运算符栈中取栈顶运算符,从操作数栈的栈顶取 2 个操作数,然后进行计算,再把计算完的结果压入操作数栈,继续比较。
具体代码如下:
package main
// TODO: practice/golang/main/stackCalculator.go
cbc 编译器
cbc 编译器是《自制编译器》中实现的。由于 cbc 编译器是在 32 位机器上工作的,而现在大部分都是 64 位,即使按照官方文档进行处理,编译时也会出现各种错误,因此想到了用 docker 搭建 32 位的系统。
$ docker run -d -ti --name cbc -v /path/cbc-1.0:/var/www/html -w /var/www/html i386/ubuntu
$ docker exec -ti cbc bash
root@261c13a74c73:/var/www/html# sed -i 's/archive.ubuntu.com/mirrors.163.com/' /etc/apt/source.list
root@261c13a74c73:/var/www/html# sed -i 's/security.ubuntu.com/mirrors.163.com/' /etc/apt/source.list
root@261c13a74c73:/var/www/html# apt-get udpate
root@261c13a74c73:/var/www/html# apt-get install -y vim gcc g++ default-jdk default-jre
root@261c13a74c73:/var/www/html# cp /usr/lib/i386-linux-gnu/crt*.o /usr/lib
root@261c13a74c73:/var/www/html# cd /path/cbc-1.0
root@261c13a74c73:/var/www/html# ./install.sh
root@261c13a74c73:/var/www/html# echo 'PATH=$PATH:/usr/local/cbc/bin' >> /etc/bash.bashrc
root@261c13a74c73:/var/www/html# . /etc/bash.bashrc
root@261c13a74c73:/var/www/html# vim hello.cb
# 以下代码是在 vim 中写入
import stdio;
int main(int argc, char **argv) {
printf("Hello, world\n");
return 0;
}
root@261c13a74c73:/var/www/html# cbc hello.cb
root@261c13a74c73:/var/www/html# ./hello
Hello, world
为了防止资源失效,特地将 [cbc]({{ site.url }}/assets/files/cbc-1.0.tar.gz) 的源码进行了备份,另外将以上操作都打包到 docker 镜像中,之后直接拉镜像即可使用。
远程 coding 实现
出于现实的考虑,不得不使用多台性能不怎么样的电脑一起玩耍,主要还是为了分摊机器的内存。最先考虑到的是 docker,毕竟现在运行环境都是用 docker 部署的,我想通过docker run -v 远程目录:容器目录 image一条命令来实现,果真是图样图森破,sometime naive,docker 目前还不支持挂载远程目录吧。
后来在小动物们的帮忙下,找到了 sshfs,具体安装过程我就不一一列举了,顶多就是在挂载时会遇到小坑。
sshfs 具体干的工作就是通过 ssh 来访问远程的目录,达到共享的目的。跟同系列的命令差不多,sshfs 基本的用法很简单:
$ sshfs root@192.168.10.66:/Users/Hello/world ~/Desktop/www
以上命令的意思就是将主机 192.168.10.66 上的目录/Users/Hello/world挂载到本机的~/Desktop/www目录上,root 就是远程主机的用户名啦。使用完的时候用umount即可弹出。
$ umount ~/Desktop/www
以上就是远程 coding 最重要的一步。接下来当然就是通过 docker 搭建运行环境。以nginx+php-fpm为例:
$ docker network create lnmp
$ docker run -d --name nginx --network lnmp -p 80:80 -v ~/Desktop/www:/usr/share/nginx/html lwlwufeng/nginx:1.19
$ docker run -d --name php --network lnmp -v ~/Desktop/www:/usr/share/php -w /usr/share/php lwlwufeng/php:7.1-fpm
$ # mysql 就不多说了,这个不影响测试
注意了,由于使用 sshfs 的目的是远程 coding,所以得将共享目录挂载到 docker 容器上,以上使用的是我配置好的测试镜像。由于 nginx 转发 php 的配置需要使用容器名,因此镜像去掉 nginx 配置中的一些注释,具体就不细说了,熟悉的话相信很容易就找到具体注释。
词法分析
一个简单的词法分析程序如下:
- 开始;
- 调用识别器;
- 判断是否为关键字或标识符,如果是,跳转到步骤 4;如果否,跳转到步骤 5;
- 查关键字表(KT表,keyword table),如果是关键字则记录该标记该值为
K.TOKEN;否则查填标识符表(IT表,identifier table),识别该值为I.TOKEN; - 判断是否为算术常数,如果是,按常数处理,查填常数表(CT表,const table),识别该值为
C.TOKEN;否则,跳转到步骤 6; - 判断是否为结束符,如果是,则结束词法分析程序;否则,查界符表(PT 表),识别该值为
P.TOKEN。
以上提到了几种 token:K.TOKEN、I.TOKEN、C.TOKEN、P.TOKEN,以下面一段 C 程序为例说明:
int foo() {
return 1;
}
以上程序的词法分析结果如下表:
| value | int | foo | ( | ) | { | return | 1 | ; | } | | type | K.TOKEN | I.TOKEN | P.TOKEN | P.TOKEN | P.TOKEN | K.TOKEN | C.TOKEN | P.TOKEN | P.TOKEN |
其中关键字表如下:
| KT | int | return |
PhpStorm 中使用 Docker 镜像的 PHP CLI Interpreter
自学 PHP 以来,除了初学时期,一直都不太喜欢用集成环境如 MAMP、WAMP 之类的,这些工具虽然用起来很方便,但不符合我折腾的个性,而且灵活性有所欠缺,还可能会降低自己的好奇心;当然重要的是服务器一般也不会使用集成环境。这不,PHP 又出新版本了,想尝尝鲜,集成工具没有更新,不就得自己折腾么。
Docker 自定义 PHP 镜像的步骤就不细说了,我已经准备好了,这里用的是lwlwufeng/php:7.1-fpm。下面说说 PhpStorm,这 IDE,真是越用越喜欢,越用越觉得强大,还有很多功能有待我折腾。
这次之所以集成 Docker 的 PHP CLI Interpreter 进来,主要是为了保持环境的一致性,另外就是 PHP 有些扩展在 Mac 或者 Windows 下实现是不太方便甚至不能安装。以下就是完整的步骤,全是图,照做就完事了。
-
点击
...按钮。
-
从 Docker 添加。

-
选择 Docker 及 PHP 镜像。
-
选择对应的 PHP 版本。
现在就可以通过 Run 按钮来运行 PHP 脚本了。效果如下:
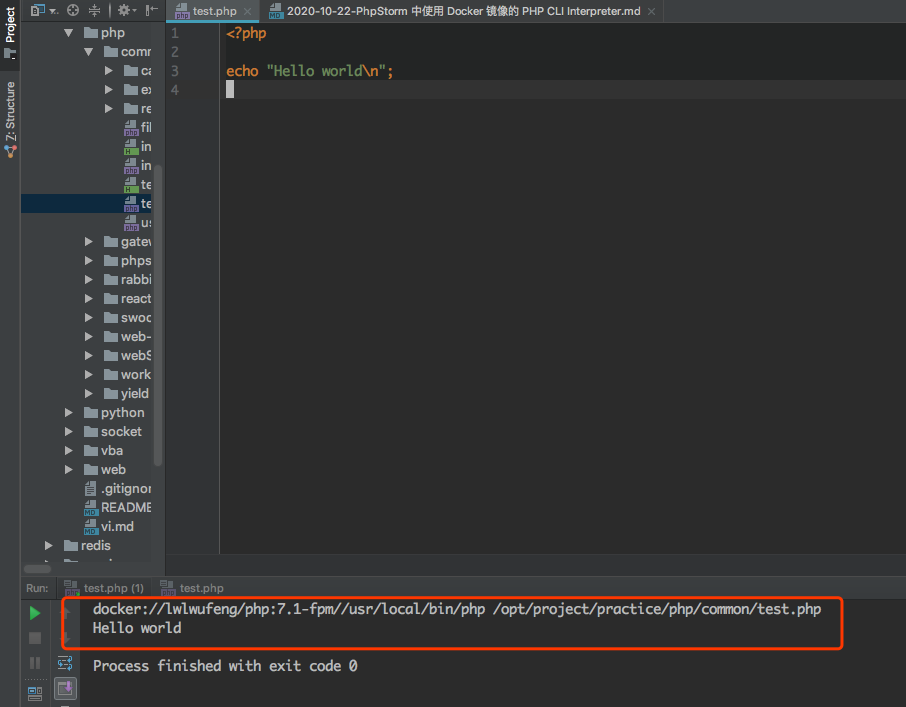
完美。
执行一个耗时操作,可以看到 docker 会临时创建一个容器,接下来当然就是根据路径映射设置相应的参数啦,程序执行即删除临时容器。
PHP 文件引入细节
今天在 workerman 的官方群看到有人问 webman 中的一个问题。大意就是 webman 在 windows 中修改 controller 代码需要重启才生效,而修改 view 代码则不需要重启也能生效(注:webman 使用了作者自己写的 FileMonitor 组件。在 Linux 系统中,可以通过监控指定目录,定时更新文件,然后通过 kill 给子进程发送信号达到重新加载的目的;而 windows 系统并没有相应的扩展支持)。这是为什么呢?
感觉这个问题有点意思,但自己又从来没有玩过 webman,于是运行之后稍微看了下 controller 调用 view 的逻辑,很快顺藤摸瓜找到了其中的调用路径app/controller/Index:view,suppport/helpers:view,support/view/Raw|ThinkPHP...:render,最后将问题关键锁定在include $view_path上,如下:
<?php
namespace support\view;
use Webman\View;
/**
* Class Raw
* @package support\view
*/
class Raw implements View
{
public static function render($template, $vars, $app = null)
{
static $view_suffix;
$view_suffix = $view_suffix ? : config('view.view_suffix', 'html');
$app_name = $app == null ? request()->app : $app;
if ($app_name === '') {
$view_path = app_path() . "/view/$template.$view_suffix";
} else {
$view_path = app_path() . "/$app_name/view/$template.$view_suffix";
}
\extract($vars);
\ob_start();
// Try to include php file.
try {
include $view_path;
} catch (\Throwable $e) {
echo $e;
}
return \ob_get_clean();
}
}
其实 include、require、include_once、require_once 这几个是面试中的常客了,而且日常使用非常频繁,但我猜很多人对其认识应该也仅仅限于引入发生错误的等级不一样、有 _once 的在多次引入时只引入一次之类的。
事件处理机制
懂 Jquery 的一定见过以下形式的代码:
$('#btn').on('click', function() {
alert('Hello world!');
});
以上就是Jquery的事件处理。并不只有Jquery才有事件处理,很多语言框架都有类似的机制。那么事件是怎么实现的呢?
最近在通过PHP学习网络编程,看到on事件处理函数在Workerman或者Swoole框架中简直太多了。下面就用原生的PHP来实现事件处理吧。
原生 PHP 实现事件处理
<?php
class Server {
private $host = '0.0.0.0';
private $port = 10086;
private $listen = null;
private $client = [];
private $callback = [];
public function __construct($host = '', $port = '') {
if ($host) {
$this->host = $host;
}
if ($port) {
$this->port = $port;
}
$this->listen = socket_create(AF_INET, SOCK_STREAM, SOL_TCP);
socket_set_option($this->listen, SOL_SOCKET, SO_REUSEPORT, 1);
socket_bind($this->listen, $this->host, $this->port);
socket_listen($this->listen);
$this->client[] = $this->listen;
}
public function on($event = '', callable $callback) {
$this->callback[$event] = $callback;
}
public function runAll() {
while (true) {
$read = $write = $exception = $this->client;
$has = socket_select($read, $write, $exception, null);
if ($has <= 0) {
continue;
}
// 有新连接
if (in_array($this->listen, $read)) {
$conn = socket_accept($this->listen);
if (!$conn) {
continue;
}
$this->client[] = $conn;
// listen 已经完成使命了,unset 它
$key = array_search($this->listen, $read);
unset($read[$key]);
// onConnect 事件
$callback = isset($this->callback['connect']) ? $this->callback['connect'] : false;
if (false !== $callback) {
call_user_func_array($callback, []);
}
}
foreach ($read as $rk => $rv) {
socket_recv($rv, $buff, 1024, 0);
if (!$buff) {
unset($this->client[$rk]);
socket_close($rv);
continue;
}
// onMessage 事件
$callback = isset($this->callback['message']) ? $this->callback['message'] : false;
if (false !== $callback) {
call_user_func_array($callback, [$buff]);
}
unset($this->client[$rk]);
socket_shutdown($rv);
socket_close($rv);
}
}
}
}
$server = new Server();
$server->on('connect', function () {
echo "connected." . PHP_EOL;
});
$server->on('message', function ($message) {
echo "received message: " . $message;
});
$server->runAll();
其实看起来也没多大难度嘛,无非就是注册事件函数,然后在特定位置调用call_user_func_array,跟钩子差不多。在Workerman中的on事件实现原理跟以上代码也差不多,当然那是经过了很多人的试错使代码变得更健壮的,这个示例跟它无法相提并论。Swoole的实现我估计也差不了太远,只不过用了其它语言实现。
消息推送平台原理探究
刚入行的时候就用过第三方消息推送平台进行手机通知的推送,当时着实让我感觉很头疼,很多术语都不懂,后面也没有进一步地思考。昨天看到一个比当年的我要好些的菜鸟问了一个关于推送的问题,让我有了整理推送原理的想法。当然,我也只是凭着当前的积累进行推算,毕竟我没写过手机APP。
下面就以友盟推送为例,推送的过程简单来说分为三步:
- 手机
APP集成友盟推送的SDK,SDK配置好与友盟账号相关的信息。 - 开发者调用友盟的推送
API,指定发送的类型(广播、组播和单播)和消息; - 友盟的推送平台向指定的手机分发消息,手机接收到消息;
这里贴张友盟推送平台的原理图吧。
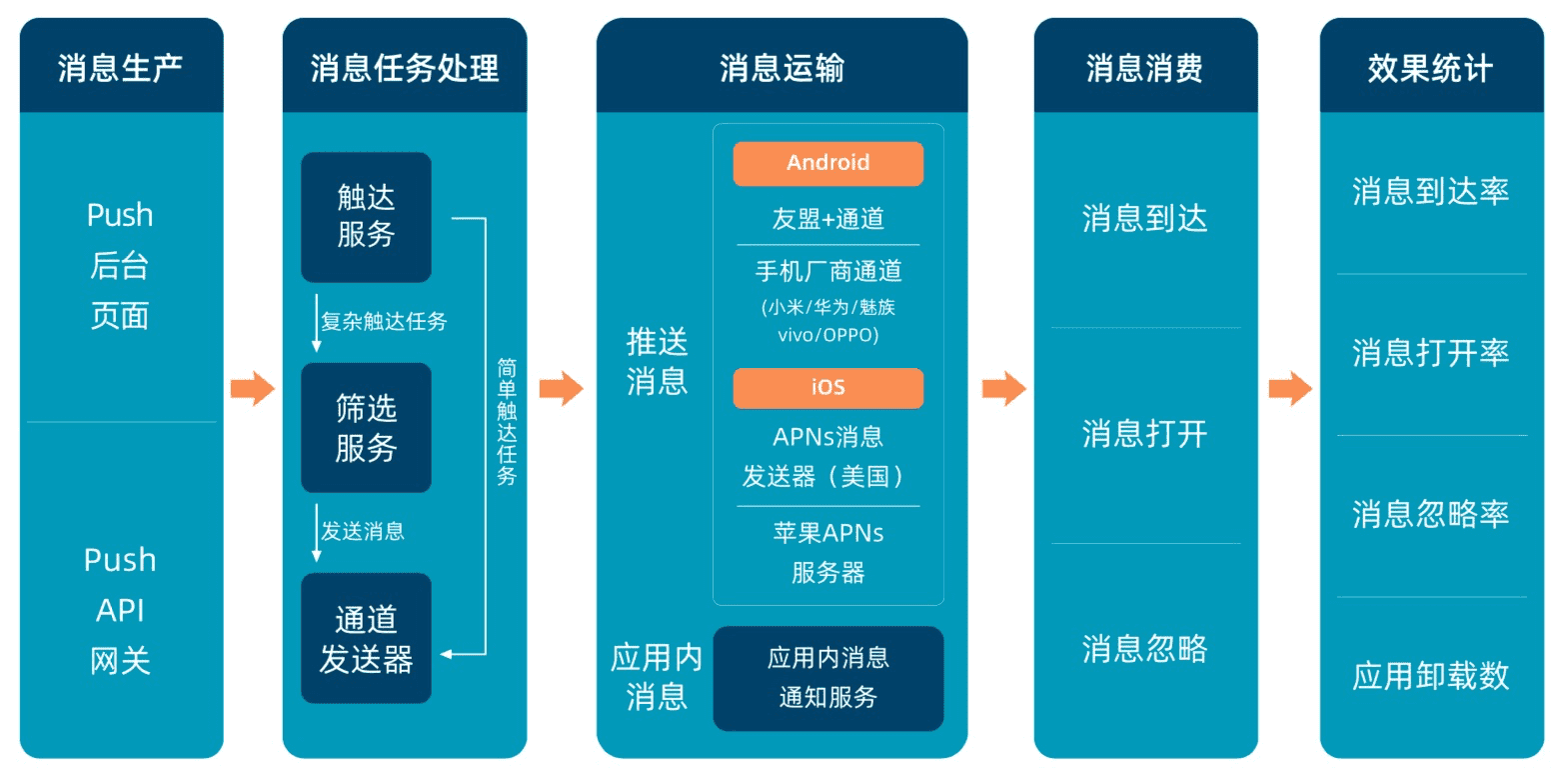
先从第 1 步说起,这里很容易理解,友盟推送平台作为推送的服务端,开发者可以通过它开放的API设置需要推送的消息,就是常见的接口调用。那么推送平台是怎么将消息推送到指定手机的呢?
关键就在于SDK。APP集成的SDK在安装后是作为服务形式存在的,简单来说就是只要手机不关机,它就会永久运行,并可以定时跟推送平台交换信息。在集成SDK时,需要绑定友盟账号的相关配置,这可以区分不同APP的推送。SDK在运行时会自动获取或生成能唯一识别该手机的deviceToken,然后跟推送平台建立连接,将deviceToken发给推送平台,推送平台就会将该连接跟deviceToken以及APP进行绑定。至此,推送平台即获取到该APP的所有设备信息,通过已建立的连接,指定deviceToken之后即可进行广播、组播以及单播。
当然,deviceToken并不是唯一的推送类型标识,例如,SDK还可以将定位发送给推送平台,达到推送消息给指定区域用户的目的。
另外,当用户量超大时,不会立即发送消息,而是定时分批地发送,这就给了发送者吃后悔药的机会。友盟任务取消的功能,也是根据这种机制来实现的。
其实手机消息推送跟WebSocket之类的推送技术并无太大区别。
有了扎实的基础,才能看透技术的本质。不必将过多时间耗在花里胡哨的东西上。话不多说,继续啃计算机基础去~
Linux 命名空间
暂时没那个水平。以下内容摘自《Docker技术入门与实战》。
今天在回顾 Docker 时看到了容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的命名空间,这里有一个以前自己不理解的知识点,其实也听说过的很多次了,但是之前基础不够,最后不了了之。最近在补基础,于是就想深挖一下。查了下维基百科,到 Linux 5.6 为止,命名空间有以下八种:
-
Mount (mnt)
Mount 命名空间用来控制挂载点。MNT 命名空间将进程的根文件系统限制在一个特定的目录下,它允许不同命名空间的进程看到的本地文件位于宿主机中不同的路径下,每个命名空间中进程所看到的文件目录是彼此隔离的。例如,不同命名空间中的进程,都认为自己独占了一个完整的根文件系统(rootfs),但实际上,不同命名空间中的文件彼此隔离,不会造成影响。
-
Process ID (pid)
Linux 通过进程命名空间管理进程号,对于同一个进程,在不同的命名空间中,看到的进程号不同。进程命名空间是一个父子关系的结构。新 fork 出的进程,在父命名空间和子命名空间分别对应不同的进程号。
-
Network (net)
网络命名空间是网络栈的虚拟化。在创建网络命名空间时只包含 lookback 接口。每一个网络接口(物理或者虚拟)都在一个命名空间中,并可以在命名空间中移动。每一个命名空间都有自己的一系列 IP 地址、路由表、socket 列表、连接跟踪表、防火墙和其它相关的网络资源。当破坏一个网络空间时,就会破坏它其中的所有虚拟接口并且它的所有物理接口都会回到初始化的网络空间中。
-
Interprocess Communication (ipc)
IPC 命名空间将进程从 SysV 网络的进程间通信中隔离开。这禁止了进程在不同的 IPC 命名空间中使用。在同一个 IPC 命名空间内的进程可以彼此可见,允许交互;不同 IPC 命名空间的进程无法交互。
-
UTS (UNIX Time-Sharing)
UTS 命名空间允许每个容器拥有独立的主机名和域名,从而可以虚拟出一个有独立主机名和网络空间的环境,就跟网络上一台独立主机一样。
-
User ID (user)
从内核 3.8 开始,用户命名空间给多个进程提供了权限隔离和用户标识隔离。每个容器可以有不同的用户和组 ID,可以在容器内使用特定的内部用户执行程序,而非本地系统上存在的用户。每个容器都可以有最高权限的 root 账号,但跟宿主主机不在一个命名空间。通过使用隔离的用户命名空间,可以提高安全性,避免容器内的进程获取到额外的权限。
-
Control group (cgroup) Namespace
cgroup 是 Linux 内核的一个特性,主要用来对共享资源进行隔离、限制、审计等。只有将分配到容器的资源进行控制,才能避免多个容器同时运行时对宿主机系统的资源竞争。控制组提供如下功能:
- 资源限制(resource limiting):可将组设置一定的内存限制。
- 优先级(prioritization):通过优先级让一些组优先得到更多的 CPU 等资源。
- 资源审计(accounting):用来统计系统实际上把多少资源用到适合的目的上,可以使用 cpuacct 子系统记录某个进程组使用的 CPU 时间。
- 隔离(isolation):为组隔离命名空间,这样使得一个组不会看到另一个组的进程、网络连接和文件系统。
- 控制(control):执行挂起、恢复和重启动等操作。
-
Time Namespace
二进制安全
在 PHP 中很多字符串操作函数都会说明是二进制安全,那么什么是二进制安全呢?
维基百科给出的定义如下:
A binary-safe function is one that treats its input as a raw stream of bytes and ignores every textual aspect it may have. The term is mainly used in the PHP programming language to describe expected behaviour when passing binary data into functions whose main responsibility is text and string manipulating, and is used widely in the official PHP documentation.
二进制安全的函数会将所有输入都视为原始的字节流,忽略其可能会有的任何字面意思。
再看看 stackoverflow 上的一个回答:
It means the function will work correctly when you pass it arbitrary binary data (i.e. strings containing non-ASCII bytes and/or null bytes).
For example, a non-binary-safe function might be based on a C function which expects null-terminated strings, so if the string contains a null character, the function would ignore anything after it.
This is relevant because PHP does not cleanly separate string and binary data.
以上提到了 C 语言的字符串是以null字节结尾的,在遇到null字符时,字符串操作系统会忽略null字符后的所有内容,因此,函数是非二进制安全的。
SSH 端口转发
本文整理自https://www.ibm.com/developerworks/cn/linux/l-cn-sshforward/index.html,主要是将示例改成自己熟悉的 redis。
端口转发
SSH 会自动加密和解密所有SSHClient和SSHServer之间的网络数据,同时还提供了一个很有用的功能,这就是端口转发。它能够将其他 TCP 端口的网络数据通过 SSH 链接来转发,并且自动提供加密和解密服务。这一过程有时也被叫做隧道(tunneling)。
假设SSHServer安装了其它服务,但是只开放了 SSH 的默认端口,那么就可以通过端口转发来绕过防火墙限制,达到与服务通讯的目的。
SSH 端口转发提供了两个功能:
- 加密
SSHClient与SSHServer之间的通讯数据。 - 绕过防火墙限制建立之前无法建立的 TCP 连接。
如上图所示,TCP PortA 通过 SSH 端口转发实现了跟 TCP PortB 的通讯。
本地转发与远程转发
本地转发实例
本地端口转发的命令格式:
$ ssh -L <local port>:<remote host>:<remote port> <SSH hostname>
现在SSHServer的 redis 服务(以下用redisServer代替),但是没有开放 redis 端口。使用端口转发的命令如下:
$ ssh -L 9999:localhost:6379 -l root 192.168.10.68
注意,如果当前用户不是跟远程登录的用户名不一致,则需要指定用户名,也就是以上的-l参数。如无意外,执行完以上命令后,已经登录了SSHServer,这时千万不要退出,因为一退出就相当于关闭了 SSH 连接,端口转发当然也失效了。以上命令的意思就是SSHClient和SSHServer分别跟各自机器上的 9999、6379 端口建立连接。以上的localhost是相对于SSHServer的地址,跟SSHClient无关。
现在打开另一个本地终端窗口,执行以下命令即可使用redisServe服务:
$ redis-cli -p 9999
127.0.0.1:9999>
redisClient跟redisServer的通讯过程如下:
redisClient将数据通过 9999 端口发送到SSHClient;SSHClient加密数据并转发到SSHServer;SSHServer解密数据并将其转发到redisServer监听的 6379 端口上;redisServer将数据发送到redisClient的过程是以上的逆过程;
这里有几个地方需要注意:
常用停止信号的区别
在 Workerman 源码中看到这么一段代码,用于终止进程。
<?php
if (static::$_gracefulStop) {
$sig = \SIGTERM;
} else {
$sig = \SIGINT;
}
foreach ($worker_pid_array as $worker_pid) {
\posix_kill($worker_pid, $sig);
if(!static::$_gracefulStop){
Timer::add(static::KILL_WORKER_TIMER_TIME, '\posix_kill', array($worker_pid, \SIGKILL), false);
}
}
以上代码使用了三种信号用于停止进程,分别是SIGTERM、SIGINT、SIGKILL。第一次看到循环中的两个posix_kill时不禁一愣,为什么要调用两次呢?难道是为了确保成功终止?那为什么不调用三次、四次呢?
在分析之前,再看一段代码。
<?php
pcntl_async_signals(true);
pcntl_signal(SIGKILL, "sig_handler", false);
function sig_handler($signo) {
switch ($signo) {
case SIGKILL:
echo "kill\n";
break;
}
}
while (true) {}
以上代码执行会报错Fatal error: Error installing signal handler for 9。SIGKILL的值就是9,错误的意思是SIGKILL安装处理器出错,也就是说SIGKILL是不受用户控制的,无论进程在干什么,都必须要终止。因此,SIGKILL很靠谱,但是不优雅,毕竟是强制终止的。同时,也可以判断SIGTERM和SIGINT都是可以受用户控制的,至于SIGTERM跟SIGINT的区别不大,SIGINT在命令行上可以通过Ctrl+C发出;SIGTERM是kill命令的默认信号。
<?php
// demo.php
pcntl_async_signals(true);
pcntl_signal(SIGINT, "sig_handler", false);
pcntl_signal(SIGTERM, "sig_handler", false);
function sig_handler($signo) {
switch ($signo) {
case SIGINT:
echo "interrupt\n";
break;
case SIGTERM:
echo "terminate\n";
break;
}
}
while (true) {}
执行以上程序,可以玩下以下命令加深一下对信号的印象,^表示Ctrl键。
文件系统实现
整体组织
首先,将磁盘划分为一个个块,块大小为 4KB,这也是很多文件系统普遍使用的块大小。将上述划分的块编号为 0 至 N-1,则该文件系统的大小为 N 个 4KB。
假设我们的磁盘的大小只能划分为 64 块。文件系统嘛,就是用来存储用户数据的,我们将存储用户数据的区域称为data region。另外,为了简便,将 64 块中靠后的 56 块用作data region,如下图所示。

文件系统需要追踪每个文件的信息,如组成文件的数据块(在data region中)、文件大小、所有者和访问权限、访问和修改时间及其它相关信息。文件系统通常用一个叫inode的结构来存储这些信息。为了容纳inode,需要在磁盘中保留一些空间,我们将这部分空间称为inode table,inode table只是简单地保存inode的数组。我们用 64 块中的 5 块来存储inode。
inode都不大,一般是 128 或 256 字节。假设每个inode都是 256 字节,一个 4KB 的块可以保存 16 个inode,则我们的磁盘有 5 * 16 = 80 个inode,inode的数量表示文件系统的最大文件数量。
现在已经有了数据块和inode了,还缺少了一个基本的组件,就是以某些方式追踪数据块或inode是空闲还是已分配,这种allocation structures是任何系统都必不可少的。下面我们使用位图bitmap来追踪,一个用于data region,另一个用于inode table,也就是下图中的d和i。

位图使用了整个 4KB 的块,一个位图可以追踪 4 * 8 * 2^10 = 32 * 2^10 个分配对象。当然,我们现在只有 56 个数据块以及 80 个inode。
Master-Worker 守护多进程模式
Master-Worker 模式的核心思想是 Master 进程和 Worker 进程各自分担各自的任务,协同完成信息处理的模式。
Master 进程用于管理维护 Worker 进程,而 Worker 进程则用于处理业务,如维持各自的客户端连接。
以下是用 PHP 实现的简单的 Master-Worker 守护多进程模式。
<?php
declare(ticks=1);
class Worker {
public static $count = 10;
public static $children = [];
public static function runAll() {
static::runMaster();
static::monitor();
}
/**
* 主进程转为守护进程,这里的要点是 fork 两次,并且设置会话 id。一般情况下 fork 一次就够了,System-V 系统需要特殊处理
*/
private static function runMaster() {
// 确保进程有最大操作权限
umask(0);
$pid = pcntl_fork();
if ($pid > 0) {
exit;
} else {
if ($pid < 0) {
throw new Exception('fork master failed');
}
}
// 守护进程关键,脱离终端
if (posix_setsid() === -1) {
throw new Exception('master setsid failed');
}
// 具体原因看"守护进程"一文
$pid = pcntl_fork();
if ($pid > 0) {
exit;
} else {
if ($pid < 0) {
throw new Exception('fork master failed');
}
}
pcntl_signal(SIGTERM, 'static::sig_handler');
cli_set_process_title('master process');
// worker 进程
for ($i = 0; $i < static::$count; $i++) {
static::runWorker();
}
}
private static function sig_handler($signo) {
foreach (static::$children as $child) {
posix_kill($child, SIGKILL);
}
echo "exit\n";
exit;
}
/*
* 创建 Worker 进程
*/
private static function runWorker() {
umask(0);
$pid = pcntl_fork();
if ($pid > 0) {
echo "\nworker $pid is running.\n";
static::$children[$pid] = $pid;
} else {
if ($pid == 0) {
static::$children[getmypid()] = getmypid();
if (posix_setsid() === -1) {
throw new Exception('worker setsid failed');
}
cli_set_process_title('worker process');
echo "Hello world: " . getmypid() . "\n";
sleep(20);
unset(static::$children[getmypid()]);
exit;
} else {
throw new Exception('fork worker process failed');
}
}
}
// 监控 worker,如果有进程退出,则重新 fork 一个 worker 进程
private static function monitor() {
while ($pid = pcntl_wait($status)) {
if ($pid == -1 || $pid == $status) {
unset(static::$children[$pid]);
break;
} else {
static::runWorker();
}
}
}
}
Worker::runAll();
守护进程
守护进程(daemon),简单来说就是可以脱离终端在后台运行的进程,脱离终端后成为内核初始进程的子进程。常见的服务如 web 服务都以守护进程的方式运行,它们的特点就是需要长时间或者永久运行,持续对外提供服务。
进程包括以下几个 ID:
- PID:进程 ID,进程的唯一标识。
- PPID:父进程 ID。
- PGID:进程组 ID,每个进程都会有进程组 ID,表示该进程所属的进程组。默认情况下新创建的进程会继承父进程的进程组 ID。
- SID:会话 ID,每个进程都有会话 ID。默认情况下,新创建的进程会继承父进程的会话 ID。
在 Linux 中可以通过ps ajx查看这几个 ID。一般 PPID 为 0 的,都是内核态进程;一般 PPID 为 1 且 PID == PGID == SID 的,都是守护进程,当然还有一些特殊情况,PID 跟 PGID、SID 不一致。
守护进程的创建流程如下:
- fork 一个子进程,退出主进程,目的是让子进程继承进程组 ID,并获取一个新的进程 ID,这保证了子进程一定不是进程组组长,因为进程组组长不能创建新会话。
- setsid 创建新会话以及设置进程组 ID,成为会话组长和进程组组长,脱离原会话、进程组、终端控制,这样该进程就不会被原终端的控制信号中断。使得进程完全独立出来,摆脱其它进程的控制。
- 再次 fork 出子进程,退出父进程(前一个子进程)。通过再次创建子进程结束当前进程,使进程不再是会话首进程来禁止进程重新打开控制终端。这个步骤并不是必须的,只是在基于 System-V 的系统上,有人建议再 fork 一次,避免打开终端设备,使程序的通用性更强。
- 设置文件创建掩码,在子进程中调用 umask(0) 重设文件权限,这是因为子进程继承了父进程的文件权限掩码,带来一定麻烦。
这个并不是必要的,需要操作文件才需要。
补充 APUE 中的守护进程编程规则
以上守护进程的创建流程可能不是太规范。以下是 APUE 中给出的在编写守护进程程序时需遵循的基本规则。
- 首先要做的是调用 umask 将文件模式创建屏蔽字设置为一个已知值(通常是 0)。由继承得来的文件模式创建屏蔽字可能会被设置为拒绝某些权限。如果守护进程要创建文件,那么它可能要设置特定的权限。
- 调用 fork,然后使父进程 exit。这样做实现了下面几点。第一,如果该守护进程是作为一条简单的 shell 命令启动的,那么父进程终止会让 shell 认为这条命令已经执行完毕。第二,虽然子进程继承了父进程的进程组 ID,但获得了一个新的进程 ID,这就保证了子进程不是一个进程组的组长进程。这是下面将要进行的 setsid 调用的先决条件。
- 调用 setsid 创建一个会话。使调用进程:(a)成为新会话的首进程,(b)成为一个新进程组的组长进程,(c)没有控制终端。在基于 System V 的系统中,有些人建议在此时再次调用 fork,终止父进程,继续使用子进程中的守护进程。这就保证了该守护进程不是会话首进程,于是按照 System V 规则,可以防止它取得控制终端。
- 将当前工作目录更改为根目录。从父进程处继承过来的当前工作目录可能在一个挂载的文件系统中。因为守护进程通常在系统再引导之前是一直存在的,所以如果守护进程的当前工作目录在一个挂载文件系统中,那么该文件系统就不能被卸载。或者,某些守护进程还可能会把当前工作目录更改到某个指定位置,并在此位置进行它们的全部工作。
- 关闭不再需要的文件描述符。这使守护进程不再持有从其父进程继承来的任何文件描述符。
- 某些守护进程打开
/dev/null使其具有文件描述符 0、1 和 2,这样,任何一个试图读标准输入、写标准输出或标准错误的库例程都不会产生任何效果。因为守护进程并不与终端设备相关联,所以其输出无处显示,也无处从交互式用户那里接收输入。即使守护进程是从交互式会话启动的,但是守护进程是在后台运行的,所以登录会话的终止并不影响守护进程。如果其他用户在同一终端设备上登录,我们不希望在该终端上见到守护进程的输出,用户也不期望他们在终端上的输入被守护进程读取。
因此,以下程序也并不太规范,缺少了第 4-6 步。
在 PHP 中使用协程进行协同多任务处理
未完待续
PHP 5.5 最大新特性之一就是支持生成器和协程。(注:官方)文档和大量的博客文章已经对生成器进行了充分的说明(像这篇以及这篇)。相反,协程受到的关注则相对较少。这是因为协程更加强大以及更难理解和解释。
我希望本文可以通过使用协程实现一个任务调度器来引导你,使你感受到它的作用。我会以一些介绍性的章节开始。如果你感觉自己已经很好地掌握了生成器和协程背后的基础,可以直接跳到"Cooperative multitasking(协同多任务)“一节。
生成器
生成器背后的基本思想是,函数不返回一个单独的值,而是返回一系列值,其中每个值都是逐个发出的。或者说,生成器使得你更容易实现迭代器。以下是一个简单的xrange()函数示例:
<?php
function xrange($start, $end, $step = 1) {
for ($i = $start; $i <= $end; $i += $step) {
yield $i;
}
}
foreach (xrange(1, 1000000) as $sum) {
echo $num, "\n";
}
以上的xrange()函数跟内置的range()函数提供了同样的功能。唯一的不同就是在上例中,range()会返回一个有 1000000 个成员的数组,而xrange()则返回一个可以发出这些数量的迭代器,但实际上从来不会计算出数组的所有值。
这种实现的优点是明显的。它允许你在处理大型数据集时不需要将数据一次性加载到内存中。你甚至可以处理无限的数据流。
通过手动实现迭代器接口,所有这些都可以在不使用生成器的情况下完成。生成器只是使它更加方便,因为你不需要再为每个迭代器实现五种不同的方法。
作为中断函数的生成器
要从生成器转到协程,理解它们的内部工作原理很重要:生成器就是可中断函数,其中 yield 语句构成中断点。
按照上例,如果调用xrange(1, 1000000),xrange()函数里的代码实际上不会运行。相反,PHP 只返回实现迭代器接口的生成器类的实例:
<?php
$range = xrange(1, 1000000);
var_dump($range); // object(Generator)#1
var_dump($range instanceof Iterator); // bool(true);
只有在你调用实例的迭代器方法时,代码才会运行。例如,如果你调用$range->rewind(),xrange()函数中的代码会一直运行到控制流中的第一个yield出现。在该例中,这意味着$i = $start,然后yield $i会运行。可以使用$range->current()获取传递给yield语句的任何内容。
如果要继续运行生成器中的代码,你需要调用$range->next()方法。这会恢复迭代器,直至遇到yield语句。因此,只要连续地使用->next()和->current()调用,你就能获取生成器的所有值,直到不再遇到yield。对于xrange()来说,一旦$i超过$end。在这种情况下,控制流会到达函数尾部,这样就没有可运行的代码了。一旦发生这种情况,->valid()方法会返回false,这说明迭代结束。
协程
协程为上述功能增加的主要功能是将值发送回生成器的能力。这将生成器和调用者之间的单向通信转换为两者之间的双向通道。
通过调用->send()方法而不是->next(),可以将值传到协程中。以下的logger()协程就是如此工作的示例:
<?php
function logger($fileName) {
$fileHandle = fopen($fileName, 'a');
while (true) {
fwrite($fileHandle, yield. "\n");
}
}
$logger = logger(__DIR__. '/log');
$logger->send('Foo');
$logger->send('Bar');
如你所见,这里的yield并没有作为语句,而是作为表达式来使用,也就是说,它有一个返回值。yield的返回值是通过->send()传递的所有数据。在该例中,yield先返回'Foo',再返回'Bar'。
文件描述符分配问题
在 OSTEP 上看到一段有意思的代码:
// p4.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <fcntl.h>
#include <sys/wait.h>
int main() {
int rc = fork();
if (rc < 0) {
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
close(STDOUT_FILENO);
close(STDERR_FILENO);
open("./p4.output", O_CREAT|O_WRONLY|O_TRUNC, S_IRWXU);
open("./p4.error", O_CREAT|O_WRONLY|O_TRUNC, S_IRWXU);
char *myargs[3];
myargs[0] = strdup("wc");
myargs[1] = strdup("p4.c"); // 如果将 p4.c 改成不存在的文件,标准错误就会写入到 p4.error 文件中
myargs[2] = NULL;
execvp(myargs[0], myargs);
} else {
int rc_wait = wait(NULL);
}
return 0;
}
以上程序执行结果如下:
$ gcc p4.c
$ ./a.out
$ cat p4.output
31 69 681 p4.c
可以发现以上程序并没有显式的将结果输出到屏幕,而是写入到 p4.output 文件了;同理,将程序中的 p4.c 改成不存在的文件,错误信息会写入到 p4.error 文件中。
CDN
CDN(Content Distributed Network)是内容分发网络的缩写。
由于 Github Pages 的速度一直不怎么样,今天就想起来要加速一下;本来 Pages 就是静态博客,加个 CDN 就得了。刚开始还想找个免费的蹭下,后来发现还要认证就算了,还是直接上阿里云比较省心,全家桶。
这一两年还算补了下网络知识,发现很多东西都是旧瓶装新酒罢了,CDN 也不例外;CDN 本质上就是分布式缓存服务器,为客户的服务器分摊流量压力。
以下这张图是从阿里云文档里扒出来的。
原理
如上图,用户要访问https://www.a.com。在https://www.a.com使用 CDN 服务之后,跟普通的请求的差别其实不大。
-
用户访问
https://www.a.com; -
本地 DNS 根据返回该域名事先设置好别名(
CNAME); -
本地 DNS 向 DNS 调度系统查询最合适的节点 IP;
-
向用户返回节点 IP;
-
用户向节点请求;
-
如果节点不存在缓存,则转发给源站(真正的内容提供商),如果存在缓存且缓存有效,则直接返回缓存;
-
节点根据缓存策略进行缓存;
-
返回内容给用户;
这里的关键就在 DNS 调度系统,DNS 调度系统会选出最好(根据 IP 所在地等信息进行判断)的 CDN 节点 IP 给用户;
这里要提下,有一种负载均衡策略就是通过 DNS 来做的,事先为域名生成多条 A 记录,用户访问时,DNS 服务器就会从这些 A 记录中随机(这里不太清楚具体的选择策略)选出一个,这样就能达到用户分流的效果。DNS 负载均衡策略主要存在以下缺点:
- DNS 是多级解析的,每级都可能进行缓存;
- 无法监控服务器状态;
- 负载均衡策略过于简单;
我们在购买 CDN 服务时,其中一个步骤就是将目标域名解析为云服务商私有域名的别名(CNAME),这应该最关键的配置了,只有将域名映射到云服务端私有域名上,才能对流量进行控制。
阿里云 CDN 服务
下面就简单说明一下为 Pages 添加 CDN 的步骤,我用的是全站加速(其实是由于普通的 CDN 总是 301 重定向,目前还没找到原因,迫不得已用的全站,不过步骤基本一样)。
有趣的 screen
这几天学习发现了一个很好玩的命令——screen。screen 是一个可以在多个进程之间复用一个物理终端的全屏窗口管理器,只要 screen 本身没有终止,其内部运行的会话都可以恢复,即使是网络中断。
有时候我们需要远程执行一些任务,如备份,开启的远程终端窗口在任务执行完毕之前不能关掉该窗口,否则任务进程会被杀掉。这时可以通过 screen 命令来同时连接多个本地或远程会话。并在其间自由切换。
会话恢复
两个远程终端窗口连接到同一服务器
窗口一
$ ssh pi@raspberrypi.id
窗口二
$ ssh pi@raspberrypi.id
窗口一执行耗时任务时中断
窗口一执行以下脚本,每隔一秒输出一个递增的数字。
$ i=0; while [ $i -lt 100 ]; do sleep 1; echo $i; i=`expr $i + 1`; done;
0
1
...
这时候,在窗口二查看进程,应该可以看到 sleep 进程。
$ ps aux | grep sleep
pi 3924 0.0 0.0 6456 376 pts/0 S+ 22:46 0:00 sleep 1
pi 3926 0.0 0.0 7348 584 pts/1 S+ 22:46 0:00 grep --color=auto sleep
接着关闭窗口一,再次在窗口二查看进程,发现 sleep 进程已经没有了。
$ ps aux | grep sleep
pi 3955 0.0 0.0 7348 580 pts/1 S+ 22:50 0:00 grep --color=auto sleep
打开新窗口(窗口三)开启 screen 会话后,再次执行耗时任务时中断
screen -S helloworld命令创建了一个 socket 名为 helloworld 的会话。
字节序
字节序,指的就是在计算机中存储的数据字节顺序,分为大端字节序和小端字节序。先看看以下代码,直观感受一下什么叫字节序。
package main
import (
"bytes"
"encoding/binary"
"fmt"
)
func main() {
buf := bytes.NewBuffer([]byte{})
var data int32 = 258
if err := binary.Write(buf, binary.BigEndian, data); err != nil {
panic(err)
}
var mem int32
if err := binary.Read(buf, binary.BigEndian, &mem); err != nil {
panic(err)
}
// [0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 1 - 0 0 0 0 0 0 1 0]
bitPrint(mem)
if err := binary.Write(buf, binary.BigEndian, data); err != nil {
panic(err)
}
var mem2 int32
if err := binary.Read(buf, binary.LittleEndian, &mem2); err != nil {
panic(err)
}
// [0 0 0 0 0 0 1 0 - 0 0 0 0 0 0 0 1 - 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0]
bitPrint(mem2)
}
func bitPrint(mem int32) {
buff := make([]string, 35)
for b := 34; b >= 0; b-- {
if b%9 == 8 {
buff[b] = "-"
} else {
if mem%2 == 1 {
buff[b] = "1"
} else {
buff[b] = "0"
}
mem /= 2
}
}
fmt.Printf("%s\n", buff)
}
以上示例,均以大端字节序写入相同数据,读取时分别使用了大端和小端字节序,其中大端的结果是:
Nginx 反向代理
最近在云服务器部署了 Jupyter,跟其它服务都堆在一台主机上了,又不想暴露太多端口,所以就用 Nginx 搞了下反向代理。
首先,先为 Jupyter 分配一个域名,该域名指向 Nginx 所在主机。个人主页暂时用的是host.xxx.cn,于是给 Jupyter 分配了个subhost.host.xxx.cn,这个域名自己喜欢就好。
接着在 Nginx 中给 Jupyter 分配一个虚拟主机,虚拟主机文件jupyter.conf配置如下:
# 负载均衡,当然,目前只有一台机,完全可以不用这个配置
upstream jupyterServer {
server 172.17.0.1:8889; # 这个就是 Jupyter 监听的 地址
# server2 host:port; # 如果有多台机器,就可以用这种形式继续配置
}
# map 根据客户端请求中的 $http_upgrade 值,构造改变 $connection_upgrade 值
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
server {
listen 80;
server_name subhost.host.xxx.cn; # 处理该域名下的请求
location / {
proxy_pass http://jupyterServer; # jupyterServer 就是以上的 upstream 配置
# 注意,以下首部一定要加,不然会出现问题。。因为反向代理之后 Host 首部不一样了,另外,还可能要用到其它协议
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
以上配置可以用来做负载均衡,当然也可以将upstream模块去除,直接将 Jupyter 监听地址写到proxy_pass中。服务器在接收到subhost.host.xxx.cn的任何请求时,都将该请求转发给172.17.0.1:8889处理。
Unicode 与 UTF-8
目前对字符集、字符编码、编码规则等概念分得还是不太清,可能术语方面会不太准确,有待加强认识
计算机内部的所有信息都是二进制形式的,二进制对计算机来说最简单的,但却并不人类友好。于是美国人制定了 ASCII 码作为二进制和英文字符的映射。但随着计算机在世界范围内的流行,ASCII 码的容量无法满足各国的需求;很多国家都开发了自己独有的字符编码方式,但是在拥有不同编码方式的计算机之间通信,会造成乱码。各国间的通信促使了统一字符编码的出现,这正是 Unicode。
Unicode
Unicode 是一个包含了世界上通用的符号集合,不管是英文还是中文,每个字符在 Unicode 都有唯一的编码。但 Unicode 仅仅是一个字符集,它只规定了符号的二进制编码,而没有规定应该如何存储这个二进制编码。比如汉字,Unicode 编码是6C49,转成二进制格式是110110001001001,15 位,至少占用 2 个字节;而字母a的 Unicode 编码是0061,转为二进制格式是1100001,7 位,至少占用 1 个字节。
UTF-8 编码规则
UTF-8 是一种变长的编码方式,它可以使用 1-4 个字节来表示一个符号,根据不同的符号而采取不同的字节长度。由于 Unicode 字符集并没有填满,因此,可以用 UTF-8 来编码,假如以后填满了,说不定就得发明一种新的编码方式来存储。
UTF-8 的编码规则很简单,只有二条:
-
对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
-
对于 n 字节的符号(n > 1),第一个字节的前 n 位都设为 1,第 n+1 位设为 0,后面字节的前两位一律设为 10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
由此得出不同字节长度 UTF-8 编码的范围(计算所有 x 位组成的最大最小值):
| 字节长度 | Unicode 范围 | UTF-8 编码二进制形式 |
|---|---|---|
| 1 | 0000 0000-0000 007F | 0xxxxxxxx |
| 2 | 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 3 | 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
目前 Unicode 字符分为 17 组编排,0x0000 至 0x10FFFF,每组称为平面(Plane)。目前只用了少数平面。
Go 语言实现 Redis 客户端
除 Telnet 以及 Go 代码部分之外,其它内容基本翻译自官网。另外,写完本文之后,发现一篇文章写得更好,代码当然也比我的更好,传送门 Reading and Writing Redis Protocol in Go。路漫漫,我还要更努力。
其实去年就看过实现 Redis 客户端的一些文章,但是由于当前对网络、协议方面不太熟悉,只是产生了一点感觉。现在终于可以自己实现了,心里有点小激动。其实自撸客户端除了对网络熟悉之外,对编译原理最好也有一定了解,如状态机啥的,不然代码会有点难看,当然我也仅仅有粗浅的了解。计算机网络,操作系统,编译原理,算法和数据结构,计算机组成原理,几座大山一定要翻越,go go go~当然,软件设计功力也要加强,后面有空还要玩数据库,压力山大。话不多说,现在进入正题吧。
Redis 通信协议介绍
Redis 客户端使用 RESP(REdis Serialization Protocol) 协议跟 Redis 服务端进行通信。RESP 协议是专门为 Redis 而设计的,当然,它也可以被其他 CS 架构软件项目使用。
RESP 在以下几方面进行了折衷。
- 易于实现
- 解析快速
- 可读的
RESP 可以序列化不同的数据类型,如 Integers, Strings, Arrays 以及一个特别的错误类型 Errors。客户端发送到服务端的请求以字符串数组的形式表示即将要执行的命令。
RESP 协议仅用于 CS 通信。Redis 集群为了在节点间交换数据,所以用的是另一个二进制协议。
请求-响应模型
Redis 接收由不同参数组成的命令。一旦接收到命令,就会进行处理并将响应发送回客户端。
这可能是最简单的模型,但还有两个例外:
Docker 搭建 LNMP 环境
下载镜像
$ docker pull nginx
$ docker pull mysql:5.7
$ docker pull php:7.1-fpm
启动容器&配置&测试
MySQL
-
启动容器,注意要添加 MYSQL_ROOT_PASSWORD 环境变量,用来设置 root 密码
$ docker run -d --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=password mysql:5.7 -
创建测试 mysql 数据
$ docker exec -ti mysql /bin/bash # mysql -h host -u username -p mysql> USE mysql; mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION; mysql> FLUSH PRIVILEGES; mysql> CREATE DATABASE test; mysql> USE test; mysql> CREATE TABLE a ( mysql> id INT(11) NOT NULL AUTO_INCREMENT COMMENT '自增 ID', mysql> name VARCHAR(32) NOT NULL DEFAULT '' COMMENT '名称', mysql> PRIMARY KEY (id) mysql> ) ENGINE=InnoDB CHARSET=utf8; mysql> INSERT INTO a mysql> (name) VALUES mysql> ('aaa'), mysql> ('bbb');
PHP
-
准备测试 php 文件
Github Pages 自定义域名
重新注册了个域名,有时候 web 开发没有域名还真是不方便。一下买了五年,美滋滋,当然顺便也要给 Github Pages 加个自己的烙印的。
为 Github Pages 添加自定义域名
如下进入设置页面,将自定义的域名填入Customer domain下的输入框中,如果要用 HTTPS 传输,则勾选Enforce HTTPS复选框。

效果就是在仓库中生成了一个 CNAME 文件,文件内容就是自定义的域名。目的就是在前台用户访问 user.github.io 时指向自定义域名(不知道说得对不对,毕竟现在还不是很专业)。
DNS 解析
前提是你已经拥有一个域名,如果没有就看看好了。我用的是阿里云,其它云服务端操作是一样的。进入添加 DNS 记录的表单。
为 user.github.io 域名添加 CNAME 记录,CNAME 就是别名的意思,添加之后访问自定义域名时,DNS 会将 IP 解析为 user.github.io 对应的 IP。
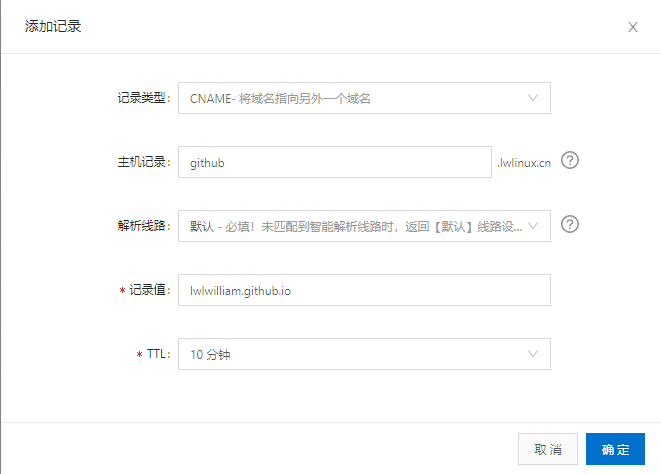
注意,在设置完成后,需要一段时间 DNS 记录才会生效。用类 Unix 系统的小伙伴可以使用 dig 命令来查看 DNS 记录。如果 DNS 解析生效,命令会返回如下结果,ANSWER SECTION 部分中的有一条记录github.lwlinux.cn 599 IN CNAME lwlwilliam.github.io,就是以上添加的 DNS CNAME 记录。
$ dig github.lwlinux.cn
; <<>> DiG 9.11.3-1ubuntu1.7-Ubuntu <<>> github.lwlinux.cn
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 14075
;; flags: qr rd ra; QUERY: 1, ANSWER: 5, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;github.lwlinux.cn. IN A
;; ANSWER SECTION:
github.lwlinux.cn. 599 IN CNAME lwlwilliam.github.io.
lwlwilliam.github.io. 3599 IN A 185.199.110.153
lwlwilliam.github.io. 3599 IN A 185.199.109.153
lwlwilliam.github.io. 3599 IN A 185.199.108.153
lwlwilliam.github.io. 3599 IN A 185.199.111.153
;; Query time: 90 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Fri Mar 27 22:22:39 CST 2020
;; MSG SIZE rcvd: 144
至此,就算是完成了 Github Pages 的自定义域名。需要注意的是 HTTPS 生效会比较久,我就等了一天一夜,orz…另外,有的 Jekyll 模板可能会需要修改一下网站的 URL。
CentOS7 允许用户或用户组 SSH 登录
平时用惯了root登录,一时间添加新用户倒不太适应。没有什么难度,纯粹记录一下方便查找。
添加新用户
# useradd -m test
# passwd test
-m用来在创建用户的同时为其创建home目录。详细参数可见useradd --help。如果需要为用户添加超级用户权限,由将其添加到sudoers中,如果不需要,则忽略下一步。
将用户添加到 sudoers 中[可选]
有两种方法,二者取其一即可。
-
修改
/etc/sudoers文件。# vim /etc/sudoers可以在 vim 中搜索
root。复制root ALL=(ALL) ALL,粘贴到另一行,并将root改为新的用户名即可,如test ALL=(ALL) ALL。 -
将新用户添加到超级用户组中,组名一般是
wheel,可以在/etc/sudoers文件中查到该组,通常设置如%wheel ALL=(ALL) ALL。注意:不需要修改/etc/sudoers文件,只是去了解一下而已,有兴趣可以看一下该文件的注释。以下命令将用户test添加到wheel组中。# usermod -a test -G wheel
将用户添加到 sshd_config 中
# vim /etc/ssh/sshd_config
将AllowUsers username1 username2或者AllowGroups groupname1 groupname2添加到该文件。如果还要允许root登录,则将PermitRootLogin yes的注释去掉(另外还要将root添加到允许登录的用户或用户组中)。
重启 sshd
# systemctl restart sshd
树莓派 4b 折腾记(一)——初识
其实很早就打算入手树莓派玩玩,因为看到了很多让我垂涎的各种花式玩法,当然最主要的是它还可以满足我当前的某些需求。小型,便宜,社区活跃,麻雀虽小,五脏俱全,这是我选择树莓派的主要原因。树莓派其实就是小型的电脑,主板接口排布紧凑,计算机的各种部件一目了解,极大地满足了我对计算机组成的好奇心。
构造
以下是树莓派 4b 的构造图。
另外,在主板背面还有一个 microSD 卡槽,SD 卡用来写入树莓派的操作系统;至于上图,在入门阶段只需要知道电源接口就行了,就是上图的USB Type-C power in,用的是 Type-C 接口,现在有些手机也已经开始用这种接口了。
安装与配置
-
用 SD Card Formatter 格式化 SD 卡;
-
官网下载树莓派操作系统,注意下载箭头所指的 Raspbian(NOOBS 的安装方式跟这个不太一样):
-
用 Etcher 将操作系统写入 SD 卡,如图选择系统镜像以及 SD 卡,点击 Flash! 即可:
-
在 SD 根目录创建 SSH 空白文件,用来启动 SSH 服务;
-
在 SD 根目录创建 wpa_supplicant.conf 文件,配置 wifi。wpa_supplicant.conf 内容如下,network 中就是即将连接的 wifi,包括 wifi 名称、密码、安全性、优先级。每个 network 为一个 wifi。
country=CN ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev update_config=1 network={ ssid="AAA" psk="AAA" key_mgmt=WPA-PSK priority=1 } network={ ssid="BBB" psk="BBB" key_mgmt=WPA-PSK priority=2 }
无线连接
将写有操作系统的 SD 卡插入卡槽,连上电源,树莓派即启动完毕。
m3u8 在线视频播放
自己有个需求,有时候希望能直接下载网站上的视频。以前另存一下就行,但后来发现很多视频网站都不能用这种方法下载了。仔细观察了一下,发现它们都有一个共同点,就是将视频分成大量切片,这种片段的格式也不是常见的, 其中在一种的 URL 都以.ts结尾,并且有个m3u8的链接跟这些.ts的 URL 有一定关系。于是就这样我就又开始愉快地玩了起来。
生成 ts 及 m3u8 文件
经过查阅一些资料,发现这些.ts文件是可以通过 mp4 等视频格式生成的。以下是ffmpeg生成.ts文件以及相关m3u8播放列表的方法,没错,m3u8本质上就是一个播放列表。ffmpeg的安装步骤就不多说了。
$ ffmpeg -i file.ext -c:v libx264 -strict -2 ./test.mp4 # 如果视频为 mp4,可省略该步骤。如果 file.ext 视频不是 mp4,则转为 mp4 格式
$ ffmpeg -y -i test.mp4 -vcodec copy -acodec copy -vbsf h264_mp4toannexb test.ts # 将 mp4 转为 ts 文件(转格式)
$ mkdir segments
$ ffmpeg -i test.ts -c copy -map 0 -f segment -segment_list segments/index.m3u8 -segment_time 10 segments/nxb-%04d.ts # 将 test.ts 文件进行切片,将这些切片文件存放到 segments 目录中,并以 nxb-%04d.ts 的格式命名,再将所有文件名存放到 segments 目录下的 index.m3u8 文件中。-segment_time 10 表示每个切片的时长为 10 秒
在用户上传完视频后,后台执行以上命令行,就生成了视频文件的多个切片nxb-%04d.ts以及这些切片的播放列表index.m3u8。在前端播放这个视频时,只需要请求index.m3u8即可。然后再根据index.m3u8的列表获取各个切片。以切片的方式获取视频,降低了网络延迟感,不需要等待完整的视频文件传输完毕后才能播放;转而根据视频的播放进度获取相应的片段,大大地提升了用户体验。
断点续传之上传
这篇文章主要讲断点续传的上传原理。
断点续传指的是在文件传输时将文件进行切分,每个部分的传输都是独立的,并且在遇到网络故障时,可以在网络通畅之后继续传输的未曾传输的部分,并不需要重新传输。
根据以上描述,Web 端的文件上传步骤如下。为了思路的清晰,以下代码十分简陋,没有进行相应的错误处理,而且是非并发安全的,千万不要在实际项目中这么写!
读取文件
var fileEle = document.querySelector('#file');
var readerFile;
var file;
fileEle.onchange = function() {
var rd = new FileReader();
file = this.files[0]; // 这里默认只有一个文件,多文件的话可以自行扩展
rd.onload = function(e) {
readerFile = e.target.result;
}
rd.readAsDataURL(file);
}
切分文件
var start = 0; // 切片头部偏移量
var count = 0; // 切片序号
var step = 10240; // 切片大小
var piece;
function getPiece() {
piece = readerFile.slice(start, start + step);
return piece;
}
上传文件
function upload() {
var fm = new FormData();
fm.append('name', file.name);
fm.append('cap', file.size);
fm.append('len', step);
fm.append('seq_' + String(count), getPiece());
var xhr = new XMLHttpRequest();
xhr.onload = function (e) {
if (e.target.status == 200 && e.target.readyState == 4) {
count ++;
start += step;
if (start < readerFile.length) {
// 这里自己决定怎么续传
setTimeout(function() {
upload();
}, 1000);
} else {
alert('上传成功');
}
}
}
xhr.open('post', 'http://localhost:8888/upload');
xhr.send(fm);
}
上传完成,合并文件
将前端传来的seq_num(num 为序列号)保存到数据库中,可以根据文件的大小来判断是否上传完毕,待确认文件上传完毕,即可进行合并。以下代码将这些复杂的步骤进行了简化,将每一段切片都直接追回到同一个临时文件中,并以一个特别的请求表示文件已经上传完毕。
FastCGI 协议初接触
准备
Nginx 配置
user root admin;
worker_processes 2;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type text/html;
gzip on;
gzip_types text/css text/x-component application/x-javascript application/javascript text/javascript text/x-js text/richtext image/svg+xml text/plain text/xsd text/xsl text/xml image/x-icon;
sendfile on;
server {
listen 80;
server_name localhost;
autoindex on;
root /var/www;
index index.html;
location / {
try_files $uri =404;
}
# 以 .go 结尾的 url 都通过 fastcgi 转发到 localhost:10000 处
location ~ \.go$ {
try_files $uri =404;
fastcgi_pass localhost:10000;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
try_files $uri $uri.html =404;
}
}
Go FastCGI 代码
// main.go
package main
import (
"fmt"
"io"
"net"
"net/http"
"net/http/fcgi"
"os"
)
type FastCGIServer struct {
}
func (s FastCGIServer) ServeHTTP(resp http.ResponseWriter, req *http.Request) {
for header, values := range req.Header {
fmt.Println(header, "=>", values)
}
defer req.Body.Close()
io.Copy(os.Stdout, req.Body)
resp.Write([]byte("<h1>Hello world</h1><p>Welcome to my Go web app.</p>"))
}
func main() {
listener, _ := net.Listen("tcp", "127.0.0.1:10000")
srv := new(FastCGIServer)
fcgi.Serve(listener, srv)
}
创建将要访问的 Go 文件
$ sudo touch /var/www/test.go
说明
Nginx 配置中,主要的配置是:
Go 内部包
在 Go 语言中,所有成员在包内均可访问,无论是否在同一源码文件中。但只有名称首字母为大写的成员可导出,在包外可视。
但是在进行代码重构时,我们会将一些内部模块陆续分离开来,以独立包的形式维护。这时,基于首字母大小写的访问权限控制则显示过于粗犷。我们希望这些包的可导出成员仅在特定范围内可访问,而不是向所有用户公开。
内部包机制提供了这种访问权限控制:所有保存在 internal 目录下的包都只能被其父目录下的包(含所有层次的子目录)访问。
以下是内部包的结构示例:
src/
internalTest/
external/
external.go
internal/
internal.go
test.go
各包文件代码如下:
// internalTest/external/external.go
package external
import "fmt"
func ExternalHello() {
fmt.Println("ExternalHello")
}
// internalTest/internal/internal.go
package internal
import "fmt"
func InternalHello() {
fmt.Println("InternalHello")
}
// internalTest/test.go
package internalTest
import (
"internalTest/external"
"internalTest/internal"
)
func Hello() {
external.ExternalHello()
internal.InternalHello()
}
测试文件:
// main.go
package main
import (
"internalTest"
"internalTest/external"
//"internalTest/internal" // error: use of internal package internalTest/internal not allowed
)
func main() {
internalTest.Hello()
external.ExternalHello()
//internal.InternalHello()
}
运行 main.go,输出如下:
Go 延迟调用
语句 defer 向当前函数注册稍后执行的函数调用。这些调用被称作延迟调用,因为它们直到当前函数执行结束前才被执行,常用于资源释放、解除锁定以及错误处理等操作。
延迟调用,注册的是调用,参数在注册时被复制并缓存起来。多个延迟注册按 FILO 的次序执行。
func main() {
x, y := 1, 2
defer func(i int) {
fmt.Println("defer x, y =", i, y)
}(x)
defer func() {
x += 1
y += 1
}()
x += 1
y += 1
fmt.Println(x, y)
}
// 输出:
// 2 3
// defer x, y = 1 4
对延迟调用的不合理使用会浪费更多资源,甚至造成逻辑错误。如下,不恰当的 defer 导致文件关闭时间延长。
func main() {
for i := 0; i < 10000; i ++ {
path := fmt.SPrintf(".log/%d.txt", i)
f, err := os.Open(path)
if err != nil {
log.Println(err)
continue
}
// 在 main 结束时才会执行,延长了逻辑结束时间和 f 的生命周期,消耗更多的内存等资源
defer f.Close()
}
}
应该直接调用,或者重构为函数,将循环和处理算法分离。
反馈与触发器
以下电路中包含两个或非门、两个开关和一个灯泡。
这个电路用了特殊的连线方式:左边或非门的输出是右边或非门的输入,而右边或非门的输出是左边或非门的输入。这种连接方式我们称之为反馈(feedback)。
在初始状态下,电路中只有左边的或非门输出电流,这是因为其两个输入均为 0。
下面先闭合上面的开关,左边或非门将立刻输出 0,右边或非门的输出也会随之变为 1,这时灯泡将被点亮。
接着,再关闭上面的开关,灯泡依然亮着。这是因为左边或非门的输入中有一个为 1,其输出依然是 0;因此右边的或非门两个输入都为 0,输出为 1。
可以发现,现在如果一直切换左边或非门的开关,灯泡都会保持亮着。
然后,现在试试闭合下面的开关。右边或非门的一个输入变为 1,则输出为 0,灯泡熄灭。同时,左边的或非门的输出此刻变为 1。
最后,再断开下面的开关。灯光依然处于熄灭状态。这是因为,右边或非门的输出为 0;则左边或非门的输入为 0,输出为 1。也就是说右边或非门有一个输入始终为 1,所以现在无论怎么切换下面的开关,灯光都不为点亮。
将以上情况总结如下:
- 接通上面的开关,灯泡被点亮,断开此开关灯泡仍然亮着。
- 接通下面的开关,灯泡被熄灭,断开此开关灯泡仍然不亮。
电路的奇怪之处是:同样是在两个开关都断开的状态下,灯泡有时亮着,有时却不亮。当两个开关都断开时,电路有两个稳定态,这类电路统称为触发器(Flip-Flop)。
**触发器电路可以保持信息,它可以"记住"某些信息。**例如,在上文中,它可以记住最近一次是哪个开关先闭合。如果遇到一种触发器,它的灯泡是亮着的,就可以推测出最后一次连通的是上面的开关;而如果灯泡不亮则可推测出最后一次连通的是下面的开关。
触发器种类繁多,以上讲述的是最简单的一种 R-S(Reset-Set,复位/置位)触发器。我们通常把两个或非门绘制成另一种形式,加上标识符就得到了下图。
我们通常用 Q 来表示用于点亮灯泡的输出的状态。另一个输出 Q(Q 反)是对 Q 的取反。Q 是 0,Q 就是 1,反之亦然。输入端 S(Set) 用来置位,R(Reset) 用来复位。可以将"置位"理解为把 Q 设为 1,而"复位"是把 Q 设为 0。当状态 S 为 1 时(对应于先前触发器中上面的开关闭合的情况),此时 Q 变为 1 而 Q 变为 0;当 R 状态为 1 时(对应于前面图中闭合下面的开关的情况),此时 Q 变为 0 而 Q 变为 1。当 S 和 R 均为 0 时,输出保持 Q 原来的状态不变。可以用下表来表示。
二进制减法
被减数大于减数
一个典型的借位减法题目如下:
最右列的 3 小于 6,因此从 5 上借 1,再用 13 减去 6 等于 7;由于 5 已经被借 1 了,因此现在的值为 4,4 小于 7,同样需要从 2 借 1,用 14 减去 7 等于 7;最左的一列,2 被借了 1,现在的值为 1,1 减去 1 为 0。因此最终的结果是 77。
下面用一个小技巧来让减法不涉及借位。
进行减法的两个数分别是被减数(minuend)和减数(subtrahend),被减数减去减数的结果是差。

为了避免借位,先用 999 减去减数。
从一串 9 (跟减数的位数一致)中减去一个数叫做对 9 求补数。无论减数是多少,计算对 9 的补数都不需要借位。
接着将补数与原来的被减数相加:
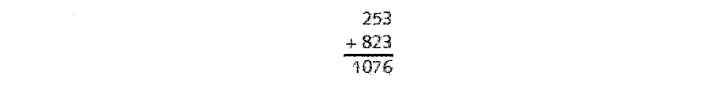
最后将结果加 1,并减去 1000。
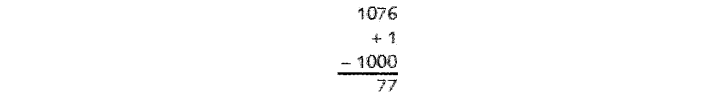
到此,就得到了结果 77。
这种方法的原理如下:
253 - 176 = 253 - 176 (+ 999 + 1 - 1000) = 999 - 176 + 253 + 1 - 1000
被减数小于减数
以上是被减数大于减数的计算方法,如果被减数小于减数会如何?
二进制加法器
计算二进制数加法与计算十进制数加法非常相似,最大的不同就在于二进制加法中用到了一个更为简单的加法表。
| + | 0 | 1 |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 10 |
以上加法表可以重新为带前导零的形式。
| + | 0 | 1 |
|---|---|---|
| 0 | 00 | 01 |
| 1 | 01 | 10 |
一对二进制数相加的结果中具有两个数位,其中一位叫做加法位(sum bit),另一位叫做进位位(carry bit),例如 1 加 1 的结果为 10,则 0 为加法位,1 为进位位。以上还可以拆分为两个表。
进位表
| + 进位 | 0 | 1 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
可以发现,进位表跟与门的输出结果是一样的,因此,可以利用与门计算两个二进制数加法的进位。
| AND | 0 | 1 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
进位位用与门表示。
加法表
| + 加法 | 0 | 1 |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 0 |
或门跟加法表的结果很相似,除了 1 加 1 的结果之外。
| OR | 0 | 1 |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 1 |
与非门和加法表的结果也很相似,除了 0 加 0 的结果之外。
Makefile 是什么?它是如何工作的?
如果想要在某些文件更新时执行或更新任务,make工具会令这个过程变得很方便。make工具需要Makefile(或makefile)文件来定义要执行的一系列任务。你可能已经使用过make将源码编译为程序。大部分开源项目都使用make来编译为二进制的可执行程序,编译后的程序可以使用make install进行安装。
本文将使用一些基本和高级的示例来对make和makefile进行探索。在这之前,先确保make已经安装好了。
基础示例
下面我们在终端上以经典的打印"Hello World"作为开始。创建一个空目录 myproject,目录里创建一个包含以下内容的makefile文件:
say_hello:
echo "Hello World"
现在在 myproject 目录里通过make命令执行这个文件:
$ make
echo "Hello World"
Hello World
在上例中,say_hello 类似于其它编程语言中的函数名。这叫做 target。prerequisites 或 dependencies 就在 target 之后。为了简单起见,在该例中我们没有定义 prerequisites。命令 echo “Hello World” 被称为 recipe ,recipe 使用 prerequisites 来创建一个 target。target,prerequisites 和 recipes 一起组成了 rule。
总而言之,下面是一个典型的 rule 语法:
target: prerequisites
<TAB> recipe
例如,一个依赖 prerequisites(源码)的二进制 target 。另一方面,一个 prerequisite 也可以是一个依赖其它 dependencies 的 target:
final_target: sub_target final_target.c
Recipe_to_create_final_target
sub_target: sub_target.c
Recipe_to_create_sub_target
target 并不非得是一个文件,它可以仅仅是 recipe 的一个名字,正如我们的示例一样。我们称这种为 phony targets(注:伪目标)。
回到我们上面的示例,当make执行后,完整的命令 echo “Hello World” 就会紧接着实际的命令后显示。我们通常不希望这样。为了抑制实际的命令,需要在 echo 之前添加 @:
CGI 初探
CGI(Common Gateway Interface),通用网关接口,用于 web 服务器和外部应用程序(CGI 程序)之间的通信。为了探索 CGI 是如何工作的,我分别用 C 和 Python 语言写了段测试程序(均生成可执行程序),以及说明了一下解释型语言的 CGI 写法。
C 程序
编译:$ gcc ctest.c -o ctest。
// ctest.c
#include <stdio.h>
#include <stdlib.h>
int main() {
printf("Content-Type:text/html;charset=utf-8\r\n\r\n");
printf("<html><body><h1>Hello C!</h1></body></html>");
return 0;
}
Python 程序
pip 安装 pyinstaller,生成可执行文件:$ pyinstaller -F pytest.py。
# pytest.py
print('Content-Type:text/html;charset=utf-8\r\n\r\n')
print('<html><body><h1>Hello Python!</h1></body></html>')
CGI 脚本
以上两个 CGI 程序都是可执行文件,其实解释型语言也可以作为 CGI 程序运行,例如 Perl 的 CGI 程序如下:
#!/usr/bin/env perl
print "Content-Type:text/html;charset=utf-8\r\n\r\n";
print "<html><body><h1>Hello Perl!</h1></body></html>";
这种写法的关键是通过 #!/usr/bin/env perl 调用相应解释器,同样的 PHP 语言等也是一样的;包括以上的 Python 在头部添加 #!/usr/bin/env python 即可,那就可以省略 pyinstaller 了。
门电路与位运算
继电器像开关一样,可以串联或并联在电路中执行简单的逻辑任务。这种继电器的组合叫做逻辑门(logic gates)。继电器优于开关之处就在于,继电器可以被其他继电器所控制,而不必由人工控制。这就意味着,这些简单的逻辑门组合起来可以实现更复杂的功能,例如一些简单的算术操作。我们用 0 表示开关断开,用 1 表示开关闭合。以下器件都由继电器构成。
缓冲器
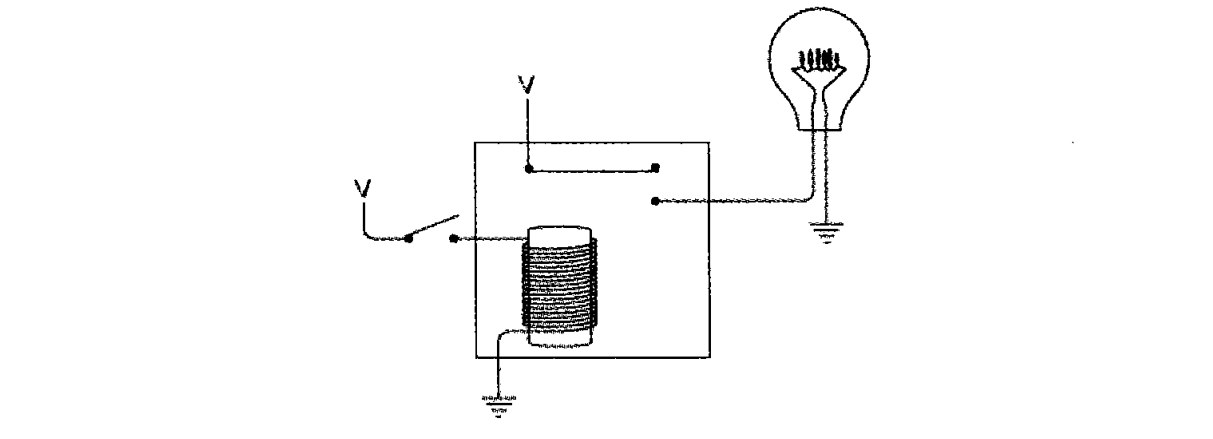
这也叫做缓冲器(buffer),可用如下符号表示。缓冲器的输入与输出是相同的。

与门
下图电路的两个继电器串联。当两个开关都断开时,灯泡不发光。
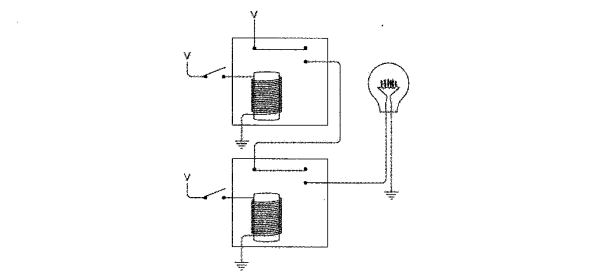
只闭合上面或下面的开关,灯泡仍然不发光。
同时闭合两个开关,灯泡亮了。
电气工程师用如下专门的符号表示一个与门。

与门开关的关系可用下表的与运算来描述。
| AND | 0 | 1 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
或门
下图电路的两个继电器并联。当两个开关都断开时,灯泡不发光。
只闭合上面或下面的开关,灯光均会发光。
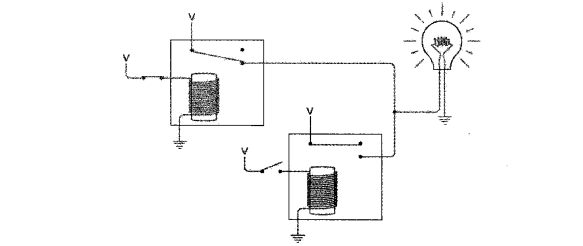
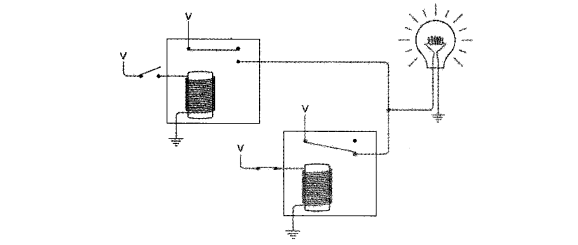
同时闭合两个开关,灯泡亮了。
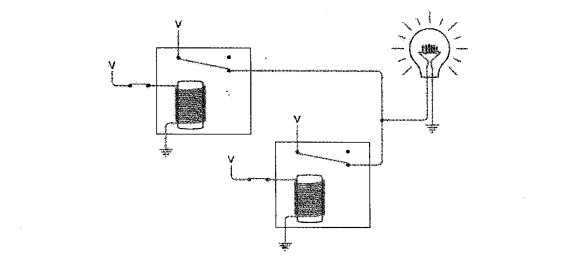
电气工程师用如下专门的符号表示一个或门。

或门开关的关系可用下表的或运算来描述。
| OR | 0 | 1 |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 1 |
反向器
下图的电路使用了另一种连接方式,在开关断开时灯泡被点亮,与之前的电路相反。以这种方式连接的继电器叫做反向器(inverter)。反向器不是逻辑门。
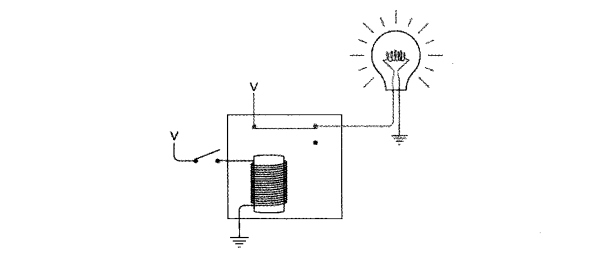
反向器可用如下专门符号来表示。

或非门
两个继电器全部断开时,灯泡发光。
只闭合上面或下面的开关,灯泡均会熄灭。
同时闭合两个开关,灯泡熄灭。
或非门用以下符号表示,除去输出部分的小圆圈,这个符号与或门非常相像。

小圆圈表示“反向”,所以或非门也可以用下面的符号表示。

或非门的结果与或门相反,或非门的关系可用下表来描述。
| NOR | 0 | 1 |
|---|---|---|
| 0 | 1 | 0 |
| 1 | 0 | 0 |
与非门
两个断电器全部断开时,灯光发光。
POP3 简介
SMTP 协议是push协议,因此不能用于收邮件。POP3 协议是 Post Office Protocol。
$ telnet pop.qq.com 110
Trying 59.37.97.57...
Connected to pop.qq.com.
Escape character is '^]'.
+OK QQMail POP3 Server v1.0 Service Ready(QQMail v2.0)
user 1234567890
+OK
pass xxxxxxx
+OK
list
1 119
2 22
retr 1
+OK
(data bala bala bala)
.
dele 2
+OK
SMTP 简介
SMTP(Simple Mail Transfer Protocol) 是基于文本的简单邮件协议,默认使用 25 端口。下图展示了 SMTP 的基本操作。
-
Alice 通过 user agent 指定 Bob 的邮件地址以及编辑邮件,然后发送邮件;
-
Alice 的 user agent 先把邮件发送到 Alice 的邮件服务器,邮件服务器用把放到消息队列中;
-
与此同时,Alice 的邮件服务器的客户端(这个邮件服务器既充当服务器也充当客户端)在队列中发现了 Alice 发向 Bob 的邮件,于是就向 Bob 的邮件服务器发起连接;
-
在连接初始化后,Alice 邮件服务器把 Alice 的邮件通过连接发送出去;
-
Bob 的邮件服务器收到了来自 Alice 邮件服务器的邮件,把该邮件放到 Bob 的个人邮箱;
-
Bob 通过 user agent 读取邮件(注意:这里的读取用的并不是 SMTP 协议)。
由此可见,SMTP 不会使用中间邮件服务器发送邮件,即使两个邮件服务器之间在地球的两端。我们可以使用 telnet 进行邮件发送,以下是使用 qq 的 SMTP 服务器发送邮件的完整流程。
-
与 smtp.qq.com 服务器(这个就是发送者的邮件服务器)的 25 端口建立连接。
$ telnet smtp.qq.com 25 Trying 14.18.245.164... Connected to smtp.qq.com Escape character is '^]'. 200 smtp.qq.com Esmtp QQ Mail Server -
Hello。
对 https 工作方式的简要解释
Diffie-Hellman 算法
对于一个素数p来说,当一个数g满足以下条件:当1 <= x <= p-1时,如果(g^x) mod p能产生[1, p-1]的所有数值,就称 g 是 p 的 generator。例如,对素数 p = 7 来说,g = 3 就是它的 generator。`
3^1 mod 7 = 3
3^2 mod 7 = 2
3^3 mod 7 = 6
3^4 mod 7 = 4
3^5 mod 7 = 5
3^6 mod 7 = 1
g = 5 也是它的 generator。
5^1 mod 7 = 5
5^2 mod 7 = 4
5^3 mod 7 = 6
5^4 mod 7 = 2
5^5 mod 7 = 3
5^6 mod 7 = 1
举个例子,Alice 和 Bob 都想写信给对方。但是有人在监听他们的通信,于是他们决定使用 Diffie-Hellman 算法来加密通信。
Cookie 和 Session
HTTP 协议是无状态的,用户的每一次请求都是独立的。有时候我们需要知道哪些请求是跟用户相关的,例如,购物车的商品属于哪个用户。web 规范给出的解决方案是经典的 cookie 和 session。cookie 是一种客户端机制,将用户的数据保存到客户端;session 是一种服务端机制,将数据以类似于散列表的结构来保存信息,这是用 PHP 内置函数生成的 session 数据格式:last_regenerate|i:1550546460;app_id|s:1:"2";。每个网站访客都会被分配一个唯一的标识符,即 sessionID。
Cookie
cookie 是由服务端生成的,客户端通过请求获取 cookie 并保存在用户计算机,在之后的请求会把 cookie 附在 HTTP 报文中,用于标识用户身份。cookie 类似于我们的身份证,是由政府(服务端)生成用于标识我们的身份。Cookie 是有时间限制的。服务端是通过 HTTP 响应报文通知客户端设置 cookie 的,如下Set-Cookie头部所示:
HTTP/1.1 200 OK
Set-Cookie: test=testValue
Content-Length: 0
客户端在收到报文后会生成一个文件保存 cookie,并且在之后的请求中,客户端的请求都会带上一个 cookie 头部向服务端表明身份,服务端就能向客户端展示专属的信息:
GET / HTTP/1.1
Host: test.id
Cookie: test=testValue
Session
session 同样是由服务端生成的。由于 cookie 是保存在客户端的,存在一定的安全隐患,某些敏感数据不适合保存在 cookie 中,而 session 保存在服务端相对来说则比较安全。
session 的基本原理是由服务端为每个会话维护一份数据,并生成一个 sessionID 给客户端来访问这份数据,以达到交互的目的。创建 session 的过程可以概括为三个步骤:
- 生成全局唯一标识符(sessionID);
- 开辟数据存储空间。可以在内存或者文件、数据库中创建相应的数据结构,各种存储介质各有利弊,应根据实际选择;
- 将 sessionID 发送给客户端;
以上三步关键在于如何发送 sessionID 到客户端。考虑到 HTTP 协议的定义,数据无非可以放到请求行、头域或 Body 里,所以一般来说会有两种常用的方式:cookie 和 URL 重写。cookie 好理解,就是把 sessionID 通过Set-Cookie头传送到客户端;URL 重写则是在返回给用户的页面的所有 URL 后面追加 sessionID,例如首页由http://example.com重写为http://example.com?sessionid=SESSIONID,这种做法不安全且比较麻烦,但是,如果客户端禁用了 cookie 的话,这种方案将会是首选。
Data URLs
语法
Data URLs,即前缀为data:协议的 URL,其允许内容创建者向文档中嵌入小文件。
Data URLs 由四个部分组成:前缀(data:)、指示数据类型的 MIME 类型、如果非文本则为可选的base64标记、数据本身:
data:[<mediatype>][;base64],<data>
mediatype是 MIME 类型的字符串,例如image/png表示 PNG 图像文件。如果省略,则默认值为text/plain;charset=US-ASCII。
如果数据是文本类型,可以直接将文本嵌入(根据文档类型,使用合适的实体字符或转义字符)。如果是二进制数据,可以将数据进行 base64 编码之后再进行嵌入,并且以数据前加上;base64表明编码。
以下是一些示例:
| Data URLs | 说明 |
|---|---|
| data:,Hello%2C%20World! | 简单的 text/plain 类型数据 |
| data:text/plain;base64,SGVsbG8sIFdvcmxkIQ%3D%3D | 上一条示例的 base64 编码版本 |
| data:text/html,%3Ch1%3EHello%2C%20World!%3C%2Fh1%3E | 一个 HTML 文档源代码 Hello, World |
| data:text/html,<script>alert(‘hi’);</script> | 一个会执行 JavaScript alert 的 HTML 文档。注意 script 标签必须封闭 |
使用 Go 语言生成 base64 编码数据
Data URLs 常用于图片中,把一些小尺寸图片转为 Data URLs 可以减少 HTTP 请求,但对于大尺寸图片不建议转换。以下是 Go 语言生成 base64 编码格式图片的示例:
package main
import (
"encoding/base64"
"os"
"log"
"bytes"
"io"
)
func main() {
reader, err := os.Open("./practice/images/test.png")
if err != nil {
log.Fatal(err)
}
defer reader.Close()
var buf bytes.Buffer
var b = make([]byte, 1024)
for {
n, err := reader.Read(b)
if err != nil {
if err == io.EOF {
buf.Write(b[:n])
break
}
log.Fatal(err)
}
n, err = buf.Write(b[:n])
if err != nil {
log.Fatal(err)
}
}
writer, err := os.OpenFile("./test.html", os.O_CREATE|os.O_RDWR,0644)
if err != nil {
log.Fatal(err)
}
defer writer.Close()
writer.WriteString("<img src='data:image/png;base64,")
encoder := base64.NewEncoder(base64.StdEncoding, writer)
encoder.Write(buf.Bytes())
encoder.Close()
writer.WriteString("'>")
}
以上代码对./practice/image/test.png中的内容进行 base64 编码,并输出到./test.html文件中。浏览器打开 test.html 文件即可看到效果。
内网穿透原理浅析
以前用过一下花生壳穿透内网,当时觉得这玩意太神奇了,有了这工具只需要在本地开发完就可以让别人直接访问,不需要烦琐的部署。可惜当初自己能力不够,只有眼馋的份。最近开始钻计算机网络这块知识,仅仅看理论觉得不过瘾,刚好看到 NAT 这块,找到了关于内网穿透的一些文章,希望自己写代码实现一个内网穿透工具,加深这方面的理解。
有时候都觉得自己有点走火入魔,总喜欢折腾些很多人都不怎么爱折腾的事,给人的感觉就是浪费时间,重复造轮子,何必呢?但个人还挺喜欢这种入迷的感觉,心怀好奇心,总是好事吧~极客精神?然而我的技术离极客还差远了。闲话就不多说了,下面进入正题。由于技术所限,难免出错。如果有心且发现本文的错误,可以到lwlwilliam.github.io给我提 issue。
由于 IP 地址(本文指的都是 IPv4)的紧缺,同一局域网内的所有主机一般都共用一个公网 IP 来访问互联网,在 IP 层中必须标明源地址和目标地址,如果局域网内多台主机同时上网会出现什么情况?这多台主机的源地址都是这同一个公网 IP,服务器的响应分组到了拥有这个 IP 的路由器应该把分组传给哪台主机?NAT 路由器都有一个 NAT 转发表,在主机到服务器的分组经过路由器时,路由器会对在 IP 层对其进行解开封装,其实现在很多 NAT 还会处理运输层,把分组的源地址和端口更换为路由器的接口的 IP 和端口,然后重新封装,把处理前后的 IP+端口对应关系记录到 NAT 转发表中,这样就可以对分组进行正确的传输。
现在如果我们想把本地的 HTTP 服务分享给其他人,但是其他人并不知道我们的本机地址,即使知道了也没有用,因为 NAT 转发表并没有记录我们 HTTP 服务的 IP 和端口。当然,这可以通过路由器对 NAT 转发表进行配置来实现(这个我没有亲自实践过),这种方法也稍显麻烦,还可能会被运营商封(这个我也没试过,道听途说的,哈)。还有没有其它办法呢?
通过以上的说明,我们知道了 NAT,那么可不可以利用 NAT 呢?答案是肯定的,前题是我们拥有一台自己的服务器。这种方法就是标题所说的内网穿透。内网穿透的原理如下图所示。
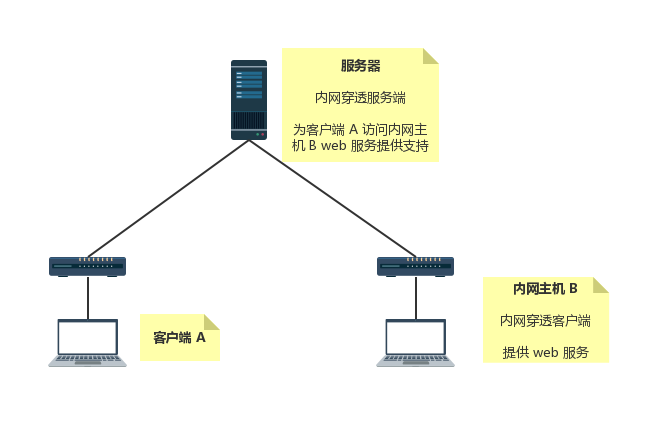
客户端 A 想要访问内网主机 A 的 web 服务,必须通过服务器作为中转。首先,服务器的穿透软件需要监听两个 socket,一个用来监听客户端 A 的请求,一个用来监听内网主机 B 的连接;接着内网主机 B 要通过内网穿透软件和服务器建立永久连接;当客户端 A 向服务器请求时,服务器的穿透软件就通过已有的两个 socket 把请求转发到内网主机 B 中,内网主机 B 读取到这个请求,再把这个请求发到 web 服务处进行处理,最后把 web 响应反向传给客户端 A。这就是内网穿透的大概原理。以下是示例代码。
SQL 在 Excel 中的应用
估计平时比较少用 Office 全家桶的程序员都不知道 Excel 中可直接用 SQL,如我,更不用说非程序员了。 当然一般情况下也不需要用 SQL,用到 SQL 就说明遇到棘手的问题了。
下面使用的是 Excel 2016,其它版本的应该也大同小异。
首先创建一个测试用的文件test.xlsx,内容如下。
第一行内容是字段名。保存后关闭该文件,并在新的工作簿选中下图红色箭头选项来自 Microsoft Query。
接着在弹出的对话框中选择Excel Files,点击确定。
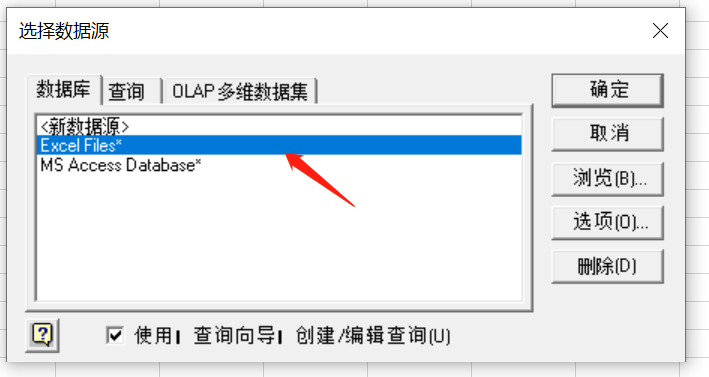
选择刚才的test.xlsx文件,点击确定。
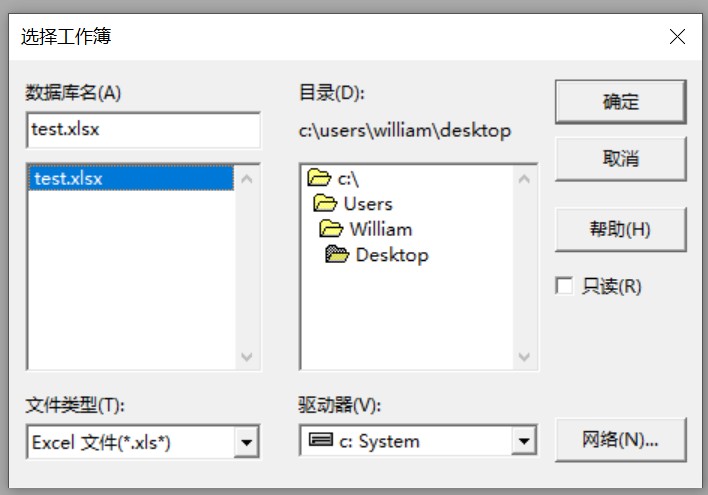
在下图左边框选择Sheet1$,点击中间的>按钮,点击下一步。以之后的弹窗可一直点击下一步。
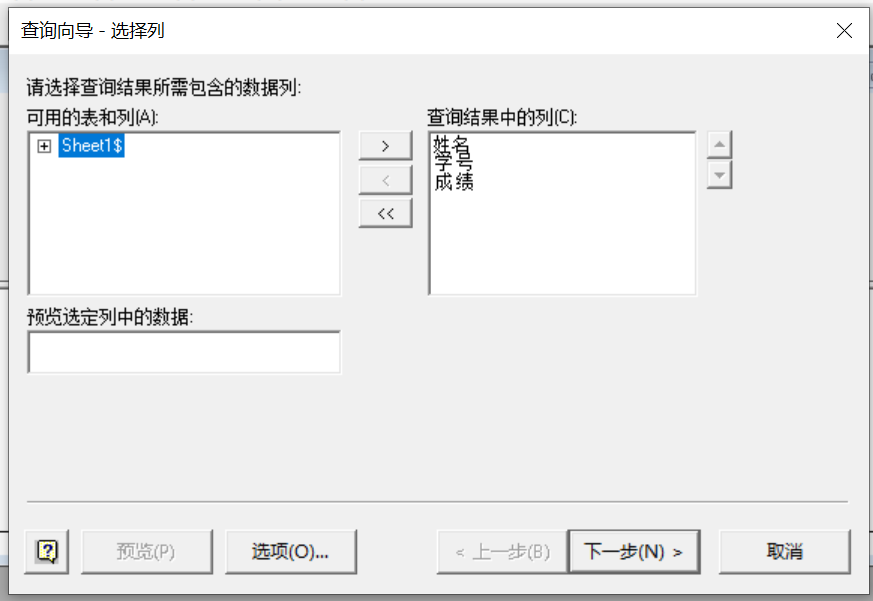
直到出现以下窗口,这里建议选择第二个选项,点击完成。
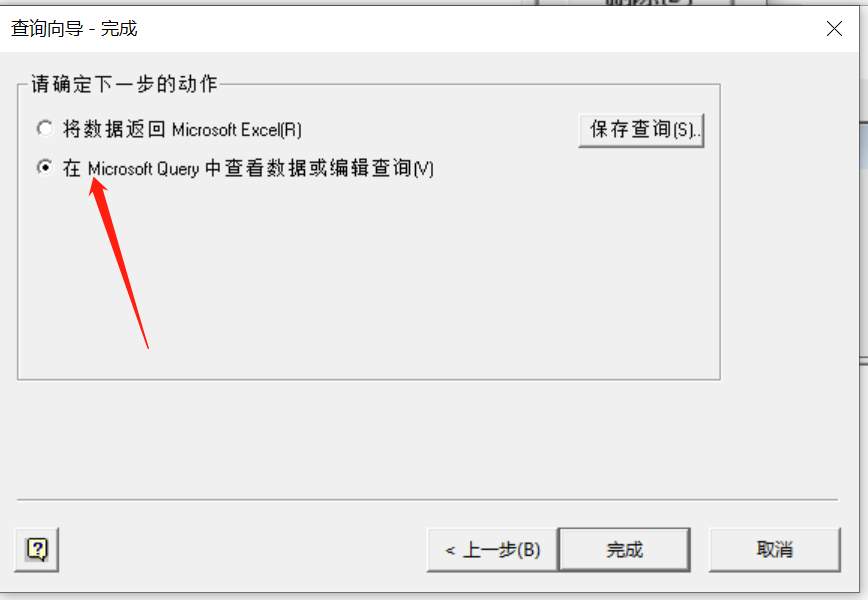
现在会出现刚才的结果。点击箭头方向的SQL按钮即可执行其它 SQL 语句。
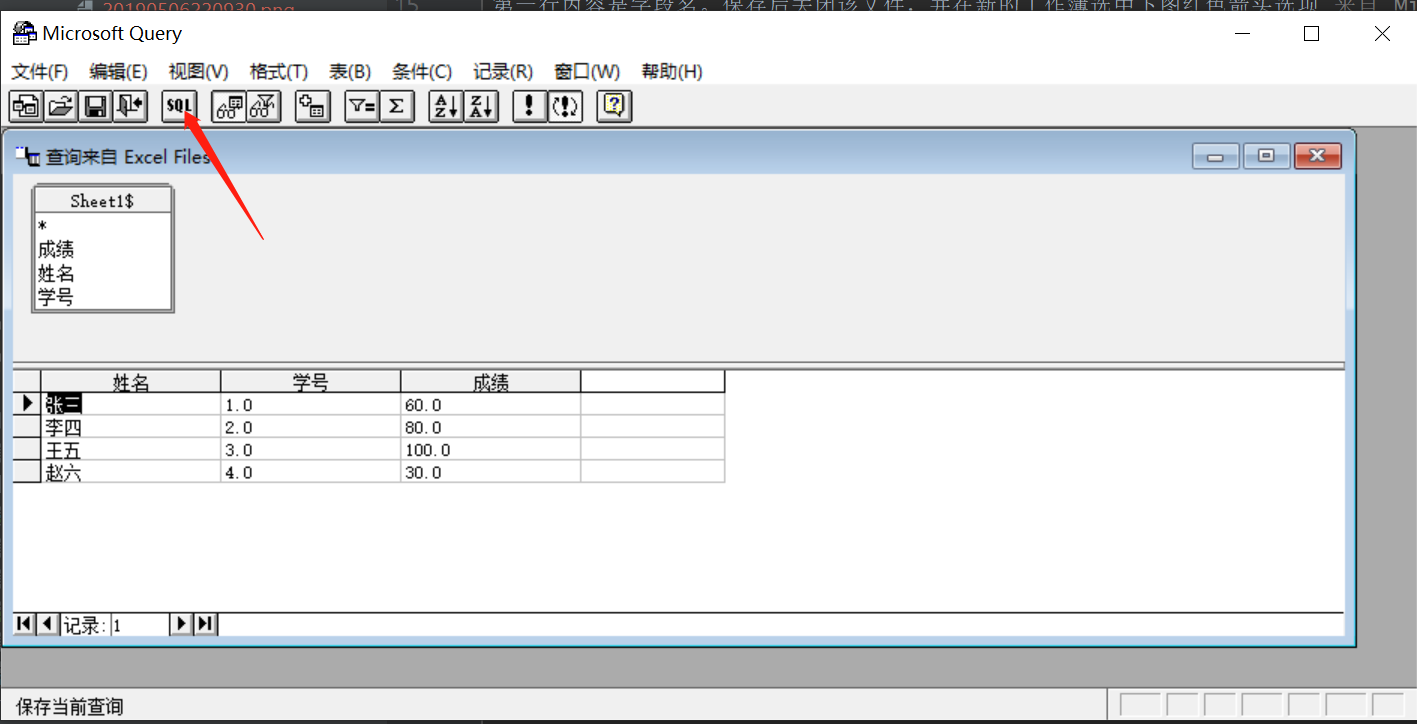
至此,已经准备好了,可以愉快地在 Excel 用 SQL 查询较大量的数据了。
通过 Socket 理解 HTTP
随着基于 web 的软件(web 应用、微服务、REST、SOAP 等)的日益流行,思考其背后的原理总是好的。当我冒险进入 Flask 或者 Django 这样的框架时 这对我特别有用。
那么我们对其深入了解到什么程度呢?协议栈中最主要的传输协议 TCP 和 UDP。
TCP 和 UDP
这里就不详细介绍了,TCP 和 UDP 是在网络中传输字节的两个主要标准。它们在连接上有着本质的区别,TCP 要求握手(在服务端与客户端进程间的一个正式连接) ,而客户端发送 UDP 消息到服务端时则不保证传输的完整性。
在本文,我们将重点讨论 TCP,因为对于使用 HTTP 的网络流量,几乎总是使用 TCP(因此网络协议栈的典型标签是 TCP/IP)。
那么我们如何 TCP 在网络上的两个进程之间传输消息呢?答案之一是 socket。
Socket
Socket 是程序与操作系统之间魔术般的接口。socket API 由操作系统提供,所有编译语言都可以通过库来访问,因此开发者可以选择任何一种,只要是 Python 的就可以了(译注:因为本文使用 Python)。
下面让我们来创建使用 TCP socket 来通信的服务端和客户端脚本(以下脚本都不兼容 Python3)。
# server_tcp.py
import socket
# socket.SOCK_STREAM indicates TCP
serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
serversocket.bind(("localhost", 10000))
serversocket.listen(1)
(clientsocket, address) = serversocket.accept()
msg = clientsocket.recv(1024)
print "server recieved " + msg
# client_tcp.py
import socket
# socket.SOCK_STREAM indicates TCP
clientsocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
clientsocket.connect(("localhost", 12345))
msg = "Hello world from client"
print "client sending: " + msg
首先在单独的进程中运行 server_tcp 脚本,然后再在另一进程运行 client_tcp 脚本,结果如下:
浮点数表示
根据国际标准 IEEE 754,任意一个二进制小数 V 可以表示成以下形式:
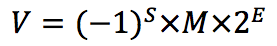
- $$(-1)^s$$ 表示符号位,当 s 为 0 时,V 为正数;当 s 为 1 时,V 为负数;
- M 表示有效数字,值范围为 [1, 2) 之间的实数;
- $$2^E$$ 表示指数位,E 可为负数;
对于 32 位浮点数,最高 1 位是符号位 s,接着是 8 位指数 E,剩下 23 位是有效数字 M;对于 64 位浮点数,最高 1 位是符号位 s,接着是 11 位指数 E,剩下 52 位是有效数字 M。
代码提取浮点数二进制位
以下是一段提取 32 位浮点数所有位的小程序:
#include <stdio.h>
#include <string.h>
int main() {
float data;
unsigned long buff;
int i;
char s[35];
// 将 0.25 以单精度浮点数的形式存储在变量 data 中
data = (float)0.25; // 可以把 0.25 改为 0.1 看看
// 把数据复制到 4 字节长度的整数变量 buff 中逐个提取出每一位
memcpy(&buff, &data, 4);
// 逐一提取出每一位
for (i = 33; i >= 0; i --) {
if (i == 1 || i == 10) {
// 加入破折号来区分符号部分、指数部分和尾数部分
s[i] = '-';
} else {
// 为各个字节赋值 '0' 或 '1'
if (buff % 2 == 1) {
s[i] = '1';
} else {
s[i] = '0';
}
buff /= 2;
}
}
s[34] = '\0';
printf("%s\n", s);
}
data = (float)0.25
从 Socket 编程到 HTTP 服务器
Socket
传输层协议很复杂,这些应该是属于操作系统内核的部分,没必要重复开发。但是对于应用程序来说,操作系统需要抽象出 一个概念,让上层应用去编程,这个概念就是"Socket",就像插座一样,一个插头插进插座,建立了连接。Socket 可以 理解为"客户端 IP +客户端 Port + 服务器端 IP + 服务器端 Port"。Port 就是端口,通俗点讲就是一个数字。
IP 用来区分主机,端口号用来区分进程。一般来说,服务器端都是被动访问的,所以大家需要知道它提供服务的端口 号,例如 80,443 等,就是所谓知名端口号;而客户端访问服务器的时候,自己的端口号可以随机生成一个,只要不 和别的应用冲突即可。
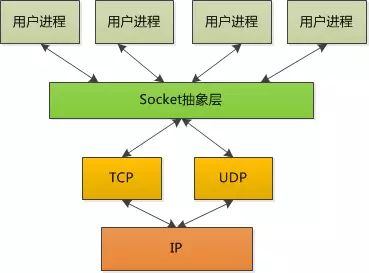
Socket 编程要分为客户端和服务器端。对于客户端来说很简单,需要创建一个 socket,然后向服务器发起连接, 连接上就可以发送,接收数据了,以下是伪代码。
clientfd = socket(...);
connect(clientfd, 服务器的 ip 和 port, ...);
send(clientfd, 数据);
receive(clientfd, ...);
close(clientfd);
以上伪代码中,没有出现客户端的 IP 和端口,系统可以自动获取 IP,也可以自动分配端口。connect() 其实就是 在和服务器发起三次握手。
服务器端要复杂一些。第一,服务器是被动的,所以它启动以后,需要监听客户端发起的连接,第二,服务器要应付 很多的客户端发起连接,所以它一定得各个 socket 给区分开了,伪代码如下:
listenfd = sockete(...);
bind(listenfd, 本机 ip 和知名端口 80, ...);
listen(listenfd, ...);
while(true) {
connfd = accept(listenfd, ...);
receive(connfd, ...);
send(connfd, ...);
}
listenfd 是为了要监听而创建的 socket 描述符,bind() 是为了声明占用该端口,listen() 开始监听。 接下来的无限循环是为了一直提供服务。由于服务器要区分开各个客户端,怎么区分呢?那只有用一个新的 socket 来表示,因此后面的操作都是基于 connfd 来做的。accept() 相当于和客户端的 connect() 一起完成了 TCP 的三次握手,至于之前的 listenfd,只是起到一个大门的作用了,意思是说,欢迎敲门,进门后我将为你生成一个 独一无二的 socket 描述符。
网卡与路由器
整理自:网卡与路由器
TODO: 以下只是梗概
DHCP
-
网卡都有一个全球唯一的地址,这个地址在网卡制造时就是确定的,称为 MAC 地址。如:11:27:F5:8A:79:54。
-
电脑初接网络时,需要确定 IP 地址,由 DHCP(动态主机配置协议)分配。
-
但是电脑刚接入网络,不知道 DHCP 在哪里,如何配置?操作系统在应用层创建 DHCP 发现报文,由 UDP 报文封装,再被 IP 数据报封装:
收件人:255.255.255.255: 67 发件人:0.0.0.0: 68 内容:新电脑需要租用一个 IP 地址,谁有? -
以上 IP 数据报到达网卡处,网卡工作在数据链路层,必须要知道对方的 MAC 地址才可以发送数据,如果不知道的时候就对外广播,使所有电脑都收 到该数据,现在不知道 DHCP 服务器 MAC 地址,所以要广播。于是把 IP 数据报再次封装:
目的地:FF:FF:FF:FF:FF:FF(广播到同一子网内的所有电脑) 发件人:11:27:F5:8A:79:54(当前电脑)之后把数据通过网线发给了交换机。
-
交换机收到目的地为 FF:FF:FF:FF:FF:FF,转发给所有连到交换机的设备;
-
局域网内存在 DHCP 服务器,且不止一台,交换机把 DHCP 的回信转回当前电脑,其中一封信的内容如下:
我是 DHCP 服务器 192.168.1.1,我这里有空闲 IP `192.168.1.2`,你要不要租?其他信内容也差不多,提供了另外的 IP。
-
操作系统选择了其中一个 IP,如上步骤向写了回信广播出去:
你好,服务器 192.168.1.1,我要 IP 192.168.1.2 了。 -
DHCP 服务器确认后向本机发回信:
这是确认信,IP 192.168.1.2 就给你了。网关路由器是 192.168.1.1,DNS 服务器地址是 202.102.224.68。操作系统把这些网络信息都保存下来:
IP: 192.168.1.2 Gateway: 192.168.1.1 DNS: 202.102.224.68除非手动配置,否则电脑重启后都要重复以上步骤。
网络协议入门
刚系统学习网络协议不久,苦于一直找不到适合自己思路的教程,只好东拼西凑地阅读各种文章书籍,好不容易才拼凑出便于自己理解的网络协议说明书。 该说明书从最常用的网络程序——浏览器入手。
OSI 模型把网络通信工作分为七层:应用层、表示层、会话层、传输层、网络层、数据链路层以及物理层;实际上使用的 TCP/IP 模型则划分五层(貌似一 开始是划分为四层的,把现在的数据链路层和物理层划到一起):应用层(对应 OSI 中的应用层、表示层和会话层)、传输层、网络层、数据链路层和物理层。 以下内容均为 TCP/IP 模型分层。
我们常用的浏览器位于应用层,协议为 HTTP。在浏览网页时,用户会在地址栏输入网页地址或者通过搜索引擎获取地址,浏览器会向该地址对应的服务器发出请求, 服务器根据请求返回相应的内容,最终呈现到用户面前的就是各式各样的网页,这都是可以想象的。
应用层
从网络协议的角度来看,在用户输入访问地址后,浏览器会先分析地址。如果是通过域名访问,会先通过 DNS 查询出域名对应的 IP 地址;然后,构造 HTTP 报文, 报文格式如下:
HEAD / HTTP/1.1
Host: 127.0.0.1
HTTP 报文最终会由目标服务器接收,报文就是浏览器和服务器的沟通语言。
传输层
HTTP 报文来到传输层。传输层的协议有 TCP 和 UDP,对应用层数据进行分段封装,负责端到端的通信。由于主机上有多个程序需要用到网络,通信时还需要一个
参数来确定数据包到底属于哪个程序,这个参数叫做端口(port),这样不同的程序就能发送、获取各自的数据。端口是每一个使用网卡的程序的编号,它的范围是 0 到
65535 之间的整数,其中 0 到 1023 端口被系统占用,用户只能选用大于 1023 的端口。浏览器会随机选用一个端口和服务器通信,这也是传输层要做的。
网络层
传输层数据来到网络层。该层主要有 IP 协议,IP 协议用来规定网络地址,即 IP 地址。IP 地址分为两部分,前面一部分为网络部分,后面一部分为主机部分。网络
部分相同的地址位于同一子网,通过子网掩码(subnet mast)可以判断两台主机是否同属一个子网。例如主机 A 的 IP 地址为 192.168.10.10,主机 B 的 IP
地址为 192.168.10.20,子网掩码为 255.255.255.0。两个 IP 地址分别与子网掩码进行按位与运算(&):
DNS 原理
整理自DNS 原理入门
DNS(Domain Name System)的作用是根据域名查询对应的 IP 地址,DNS 协议是应用层协议。
查询过程
DNS 的查询过程非常复杂,分成多个步骤。可以用工具dig显示整个查询过程。
$ dig github.com
; <<>> DiG 9.8.3-P1 <<>> github.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 23873
;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;github.com. IN A
;; ANSWER SECTION:
github.com. 23 IN A 13.250.177.223
github.com. 23 IN A 52.74.223.119
github.com. 23 IN A 13.229.188.59
;; Query time: 22 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Fri Mar 8 14:22:32 2019
;; MSG SIZE rcvd: 76
在Mac OS X EI Capitan 10.11.2系统中只有如上信息返回,并以空行分隔为四个部分,在其他系统有待试验。
浅谈 HTTP
学习开发时间也不短了,越是深入学习,越是觉得自己的知识体系不够系统,对一些通用知识不够了解。之前看的书不少, 有一定拓展,但缺点就是少了思考及练习,窃以为写文章总结是一种很好的学习方法,当然平时还得多敲代码。这里结合 最近看的一些书以及一些开发的经历来整理一下自己对 HTTP 的理解。由于能力所限,这些总结带有猜测成分,有待日后完善。
HTTP 协议是一种应用层的通信规范。HTTP 报文本质上就是有特定格式的一些文本,报文依次通过传输层、网络层和数据 链路层和物理层的配合传递到其他主机,最后到达其应用层,接收端并按照 HTTP 规范对报文进行解析。HTTP 报文分为请求 报文和响应报文。
请求报文
请求报文一般格式如下:
POST /cgi-bin HTTP/1.1
Host: example.com
paramA=A¶mB=B
以上请求报文分为请求行、请求首部以及请求体;请求行分为请求方法、请求路径以及协议版本三个部分,每个部分以空格分隔。
常见的请求方法有 GET、POST、PUT、DELETE 等;请求协议一般为HTTP/1.1或者HTTP/1.0。请求首部是对请求
的详细说明,也可以将其理解为编程里的函数参数,格式为Key: Value。例如以上的Host: example.com是指Host的
值为example.com,表示要请求主机example.com。除了 Host 还有 Content-Length 等首部。请求体与请求首部之
间以空行分隔,一般用来传输额外的数据,既可以为文本,也可以为二进制数据等。
最常用的请求方法应该是 GET 和 POST 了,也有很多文章会解释这两个方法有什么区别。最近我也看了一些类似的文章,也用 telnet 配合一些的代码进行过简单的试验。以我目前的理解,现在一般的 web 服务器都会忽略 GET 方法的请求体,也就是 说 GET 方法也是可以有请求体的,至于服务器接不接收那是另一回事。 GET 方法使用 URL 来传递参数,主要用来进行请求资源。 由于 URL 有长度的限制,所以也可以说 GET 方法传参会有长度限制。虽然 POST 方法一般都通过请求体来传递参数,但其实 也可以在 URL 上附加参数,web 服务器当然也可以接收 POST 方法通过 URL 传过来的参数了。因此 POST 方法可传输的数据 也就比 GET 方法大得多(这里也可以说 POST 可以传递无限的数据,有待查证)。 POST 方法一般用于提交数据。
Go 代码测试
Go 有一个由go test命令和testing包组成的轻量级测试框架。testing包为 Go 包提供自动化测试支持,并和go test命令配合使用,自动运行符合以下形式的任意函数:
func TestXxx(*testing.T)
被测试函数Xxx首字母为大写。在测试函数中使用Error、Fail或相关方法来标记失败。如果测试函数调用一个失败的函数,如t.Error或者t.Fail,则认为测试失败。
测试文件以_test.go结尾,该文件包含名为TestXxx、签名为func (t *testing.T)的函数,测试文件与被测试文件放在同一个包中。测试文件在一般的包编译时
被忽略,在运行go test命令时才会被使用。
以下是一个完整的例子,创建一个stringutil包,包文件有reverse.go和reverse_test.go,reverse.go文件为普通的包文件,代码如下:
package stringutil
func Reverse(s string) string {
r := []rune(s)
for i, j := 0, len(r) - 1; i < len(r) / 2; i, j = i + 1, j - 1 {
r[i], r[j] = r[j], r[i]
}
return string(r)
}
reverse_test.go文件为reverse.go的测试文件,代码如下:
package stringutil
import (
"testing"
)
func TestReverse(t *testing.T) {
cases := []struct {
in, want string
}{
{"Hello, world", "AAAdlrow ,olleH"},
{"Hello, 世界", "界世 ,olleH"},
{"", ""},
}
for _, c := range cases {
got := Reverse(c.in)
if got != c.want {
t.Errorf("Reverse(%q) == %q, want %q", c.in, got, c.want)
}
}
}
如上所示,TestReverse函数为Reverse函数的测试函数。现在可以进入stringutil目录,运行以下命令:
Linux 下 PHP 扩展安装
官方扩展
在 Linux 下通过源码安装 PHP,一般都不会把所有的官方扩展都装上。面我之前看官网手册介绍,这些官方扩展都必须要
在编译期间的./configure配置阶段加上--with-*等参数进行安装的。以至于我一度认为万一用到这些未安装的官方扩展时
都要重装一下 PHP。
刚才重装 Linux 时顺带配了下 PHP 环境,才发现原来这些官方扩展也可以跟第三方扩展一样单独编译的。看来还是基础不够牢, 对一些概念理解不到位才会造成这个误解。
在 PHP 的源码目录中有一个ext目录,该目录放的就是官方扩展。既然有源码,一切都好办了,按照一般的扩展安装步骤处理即可:
- 进入扩展目录:
cd ext; - 运行
phpize,生成configure文件,如果系统安装了多个版本的 PHP,注意调用对应版本的phpize; - 运行
./configure --with-php-config=/path/to/php-config; make编译;make test进行测试,注意,这一步如果出现错误可以先忽略,只要可以正确安装扩展即可;- 源码安装可能会找不到 PHP 的配置文件,这时候运行
php -i | grep php.ini查看了下配置文件所在的目录,然后把 PHP 源码目录中的php.ini-*复制到配置文件目录:cp php.ini-* /path/to/php.ini,php.ini-*特指某一配置文件; - 在
php.ini添加正确的扩展目录以及extension=*.so,*.so特指某一个扩展; - 重启服务器;
第三方扩展
pecl 安装
PECL 是 PHP 官方提供的扩展仓库,里面的扩展相对比较有保障,当然只是相对。使用 pecl 工具可以方便地了解安装这些扩展。
以下命令用来安装 pecl 工具。
$ wget http://pear.php.net/go-pear.phar
$ php go-pear.phar
$ pecl
...
一般情况下使用pecl search和pecl install即可,第一个命令用于搜索扩展,第二个命令用于安装扩展。有时候由于版本限制,需要安装指定扩展,可以先在http://pecl.php.net搜索扩展主页,查看版本列表,指定版本安装,如pecl install channel://pecl.php.net/redis-5.3.1。
源码安装
源码安装的步骤跟官方扩展的差不多,主要的不同就是需要自己下载扩展库的源码包。
error 类型 Error() 方法的无限递归
在 Go 语言中使用 error 值来表示错误状态。事实上,error 类型是内置的接口,定义如下:
type error interface {
Error() string
}
函数一般会返回一个 error 类型的值,因此调用函数时应该通过测试 error 是否等于 nil 来处理错误,如:
i, err := strconv.Atoi("42")
if err != nil {
fmt.Printf("Could'n convert number: %v.\n", err)
return
}
fmt.Println("Converted integer:", i)
如果 error 为 nil 说明调用成功,否则调用失败。
在编程过程中,常常需要自定义错误:
type ErrNegativeSqrt float64
func (e ErrNegativeSqrt) Error() string
假如在 Error 方法中调用了 fmt.Sprint(e) 及其它类似调用,会导致死循环,这是为什么呢?以下通过一个完整示例来说明:
package main
import (
"fmt"
)
type ErrNegativeSqrt float64
func (e ErrNegativeSqrt) Error() string {
// 死循环
//return fmt.Sprintf("Could'n convert number: %v.\n", e)
return fmt.Sprintf("Could'n convert number: %v.\n", float64(e))
}
func Sqrt(x float64) (float64, error) {
if x >= 0 {
return 0, nil
} else {
return 0, ErrNegativeSqrt(x)
}
}
func main() {
fmt.Println(Sqrt(2))
fmt.Println(Sqrt(-2))
}
现在来看 Error() 方法体,两个 fmt.Sprintf() 调用的区别就在于是否对 e 进行了类型转换,没有进行类型转换的会导致死循环。这是由于没有进行转换时,fmt.Sprintf() 使用 e 参数时会调用 e.Error(),e.Error() 调用时又会导致 e.Error() 被递归调用,无限递归下去,于是就产生了死循环。对其进行类型转换则避免了 e.Error() 的递归调用。
Hello Pages
入驻 Github Pages。
常写文章,多做总结,深入思考,少些浮躁。
搜索数据
{{ $pages := where .Site.RegularPages “Type” “posts” }} [ {{ range $index, $page := $pages }} { “title”: {{ $page.Title | jsonify }}, “url”: {{ $page.RelPermalink | jsonify }}, “content”: {{ $page.Plain | jsonify }}, “date”: {{ $page.Date.Format “2006-01-02” | jsonify }}, “categories”: {{ $page.Params.categories | jsonify }} }{{ if ne $index (sub (len $pages) 1) }},{{ end }} {{ end }} ]