根据国际标准 IEEE 754,任意一个二进制小数 V 可以表示成以下形式:
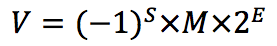
- \((-1)^s\) 表示符号位,当 s 为 0 时,V 为正数;当 s 为 1 时,V 为负数;
- M 表示有效数字,值范围为 [1, 2) 之间的实数;
- \(2^E\) 表示指数位,E 可为负数;
对于 32 位浮点数,最高 1 位是符号位 s,接着是 8 位指数 E,剩下 23 位是有效数字 M;对于 64 位浮点数,最高 1 位是符号位 s,接着是 11 位指数 E,剩下 52 位是有效数字 M。
代码提取浮点数二进制位
以下是一段提取 32 位浮点数所有位的小程序:
#include <stdio.h>
#include <string.h>
int main() {
float data;
unsigned long buff;
int i;
char s[35];
// 将 0.25 以单精度浮点数的形式存储在变量 data 中
data = (float)0.25; // 可以把 0.25 改为 0.1 看看
// 把数据复制到 4 字节长度的整数变量 buff 中逐个提取出每一位
memcpy(&buff, &data, 4);
// 逐一提取出每一位
for (i = 33; i >= 0; i --) {
if (i == 1 || i == 10) {
// 加入破折号来区分符号部分、指数部分和尾数部分
s[i] = '-';
} else {
// 为各个字节赋值 '0' 或 '1'
if (buff % 2 == 1) {
s[i] = '1';
} else {
s[i] = '0';
}
buff /= 2;
}
}
s[34] = '\0';
printf("%s\n", s);
}
data = (float)0.25
以上程序在data = (float)0.25时,结果为0-01111101-00000000000000000000000。十进制的0.25相当于二进制的0.01,即为$$1.0*2^{-2}$$因此,符号位 s 为0,指数位 E 为-2,有效数字 M 为1.0。
因此以上程序的结果中符号位 s 表示为二进制格式就是0;而有效数字 M 由于是范围是[1,2),默认整数为 1,只将小数位保存到计算机中,所以1.0保存的结果是00000000000000000000000;最后指数位 E 是一个无符号整数,但是在科学计数法中指数是可以为负数的,这意味着需要对指数位进行处理,在 IEEE 754 中规定,E 的真实值必须再减去一个中间数,对于 8 位的 E,这个中间数是 127,对于 11 位的 E,这个中间数是 1023,所以以上程序中的 E 为125 - 127 = -2,125 转为二进制表示即为01111101。
data = (float)1.5
当data = (float)1.5时,结果为0-01111111-10000000000000000000000。十进制1.5相当于二进制1.1,即为$$1.1*{2^0}$$因此,符号位 s 为0,指数位 E 为0,有效数字 M 为1.1。
同理可得,M = 10000000000000000000000,E = 127-127 = 0,十进制的127相当于二进制的01111111。
data = (float)0.1
当data = (float)0.1时,结果为0-01111011-10011001100110011001101。十进制0.1约等于二进制0.000110011001100110011001101,即为$$1.10011001100110011001101*2^{-4}$$因此,符号位 s 为0,指数位 E 为-4,有效数字 M 为1.10011001100110011001101。
同理可得,M = 10011001100110011001101,E = 123-127 = -4,十进制的123相当于二进制的01111111。
关于储存字节序(大小端)的扩展
谈到计算机中的浮点数表示方式,就涉及到字节序的问题。由于对此见识仅限皮毛,因此这里只是稍微展开一提。在 Go 语言中的 binary 库可以指定储存的字节序,现在有大小端两种字节序;所谓大端,则是高位字节在前,低位字节在后,这也是一般人所习惯的;小端则与其相反。
package main
import (
"bytes"
"encoding/binary"
"fmt"
)
func main() {
buf := bytes.NewBuffer([]byte{})
var data float32 = 1.5
if err := binary.Write(buf, binary.BigEndian, data); err != nil {
panic(err)
}
var mem int32
if err := binary.Read(buf, binary.BigEndian, &mem); err != nil {
panic(err)
}
// [0 0 1 1 1 1 1 1 - 1 1 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0]
print(mem)
if err := binary.Write(buf, binary.BigEndian, data); err != nil {
panic(err)
}
var mem2 int32
if err := binary.Read(buf, binary.LittleEndian, &mem2); err != nil {
panic(err)
}
// [0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 - 1 1 0 0 0 0 0 0 - 0 0 1 1 1 1 1 1]
print(mem2)
}
func print(mem int32) {
buff := make([]string, 35)
for b := 34; b >= 0; b-- {
if b%9 == 8 {
buff[b] = "-"
} else {
if mem%2 == 1 {
buff[b] = "1"
} else {
buff[b] = "0"
}
mem /= 2
}
}
fmt.Printf("%s\n", buff)
}
看以上示例,两次以大端字节序写入相同数据,但读取时分别使用了大端和小端字节序,其中大端的结果是:
[0 0 1 1 1 1 1 1 - 1 1 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0]
小端的结果是:
[0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 - 1 1 0 0 0 0 0 0 - 0 0 1 1 1 1 1 1]
可以发现,两个结果恰好按字节为单位,顺序完全相反,这就是大小端字节序最直观的区别。由于大端字节序更符合人类的习惯,先读取的是高位;而小端字节序更适合计算机处理,先读取低位,因此两者都有其存在价值,在读取时需要注意。