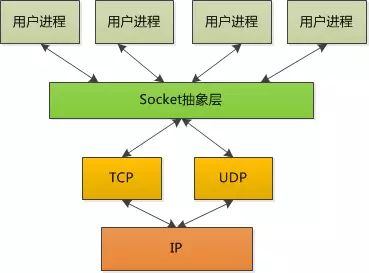
Socket
传输层协议很复杂,这些应该是属于操作系统内核的部分,没必要重复开发。但是对于应用程序来说,操作系统需要抽象出 一个概念,让上层应用去编程,这个概念就是”Socket”,就像插座一样,一个插头插进插座,建立了连接。Socket 可以 理解为”客户端 IP +客户端 Port + 服务器端 IP + 服务器端 Port”。Port 就是端口,通俗点讲就是一个数字。
IP 用来区分主机,端口号用来区分进程。一般来说,服务器端都是被动访问的,所以大家需要知道它提供服务的端口 号,例如 80,443 等,就是所谓知名端口号;而客户端访问服务器的时候,自己的端口号可以随机生成一个,只要不 和别的应用冲突即可。
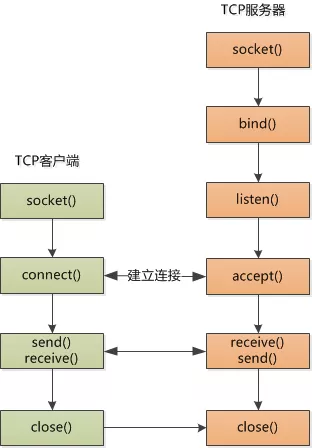
Socket 编程要分为客户端和服务器端。对于客户端来说很简单,需要创建一个 socket,然后向服务器发起连接, 连接上就可以发送,接收数据了,以下是伪代码。
clientfd = socket(...);
connect(clientfd, 服务器的 ip 和 port, ...);
send(clientfd, 数据);
receive(clientfd, ...);
close(clientfd);
以上伪代码中,没有出现客户端的 IP 和端口,系统可以自动获取 IP,也可以自动分配端口。connect() 其实就是 在和服务器发起三次握手。
服务器端要复杂一些。第一,服务器是被动的,所以它启动以后,需要监听客户端发起的连接,第二,服务器要应付 很多的客户端发起连接,所以它一定得各个 socket 给区分开了,伪代码如下:
listenfd = sockete(...);
bind(listenfd, 本机 ip 和知名端口 80, ...);
listen(listenfd, ...);
while(true) {
connfd = accept(listenfd, ...);
receive(connfd, ...);
send(connfd, ...);
}
listenfd 是为了要监听而创建的 socket 描述符,bind() 是为了声明占用该端口,listen() 开始监听。 接下来的无限循环是为了一直提供服务。由于服务器要区分开各个客户端,怎么区分呢?那只有用一个新的 socket 来表示,因此后面的操作都是基于 connfd 来做的。accept() 相当于和客户端的 connect() 一起完成了 TCP 的三次握手,至于之前的 listenfd,只是起到一个大门的作用了,意思是说,欢迎敲门,进门后我将为你生成一个 独一无二的 socket 描述符。
到这里,似乎有一个漏洞。socket 指的是 ip+port,现在已经有了一个 listenfd 的 socket,端口为 80, 然后每次客户端发起连接还要创建新的 socket,因为 80 端口已经被占用,难道服务器会为每个连接都创建新的 端口?
其实新创建的 connfd 并没有使用新的端口号,也是用的 80,可以这么理解,这个 socket 描述符指向一个数据 结构,例如 listenfd 指向的结构是这样的:
| socket | 客户端 IP | 客户端 port | 服务器端 IP | 服务器端 port |
|---|---|---|---|---|
| listenfd | 0.0.0.0 | * | 192.168.0.1 | 80 |
一旦 accept 新的连接,新的 connfd 就会生成如下表格,就生成了两个 connfd,它们俩服务器端的 ip 和 port 都是相同的,但是客户端的 ip 和 port 是不同的,自然就可以分开了。
| socket | 客户端 IP | 客户端 port | 服务器端 IP | 服务器端 port |
|---|---|---|---|---|
| listenfd | 0.0.0.0 | * | 192.168.0.1 | 80 |
| connfd1 | 192.168.1.10 | 13637 | 192.168.0.1 | 80 |
| connfd2 | 192.168.1.9 | 23697 | 192.168.0.1 | 80 |
严格来说,四元组还不太准确,因为以上都是 TCP 协议的 socket。所以更准确的定义还得加上协议这一项,变成 五元组(协议,客户端 IP,客户端 port,服务器端 IP,服务器端 port)。
从输入网址到最后浏览器呈现页面内容,中间发生了什么?
假设本机已经准备好了各种网络基础设施。
准备
在浏览器输入网址(例如:www.coder.com)并敲了回车之后,浏览器首先要做的事情就是获得 coder.com 的 IP 地址,具体做法是发送一个 UDP 包给 DNS 服务器,这时候浏览器通常会缓存 IP。
有了服务器的 IP,浏览器就可以发起 HTTP 请求了。但是 HTTP Request/Response 必须在 TCP 这个”虚拟的连接”上来发送和接收。要建立”虚拟”的 TCP 连接,需要本机 IP、本机端口、服务器 IP 和服务器端口。现在只知道本机 IP 和服务器 IP。
本机端口可以通过操作系统随机分配,服务器端口用的是一个”众所周知”的端口,HTTP 服务就是 80。
经过三次握手以后,客户端和服务器端的 TCP 连接就建立起来了,现在可以发送 HTTP 请求。
Web 服务器
一个 HTTP GET 请求经过多个路由器转发,到达服务器端(HTTP 数据包可能被下层进行分片传输,略去不表)。
Web 服务器需要着手处理,它有三种方式来处理:
-
一个线程处理所有请求,同一时刻只能处理一个,这种结构易于实现但性能太差。
-
为每个请求分配一个进程/线程,但当连接太多的时候,服务器端的进程/线程会耗费大量内存资源,进程/线程的切换也会让 CPU 不堪重负。
-
复用 I/O 的方式,很多 Web 服务器都采用了复用结构,例如通过 epoll 的方式监视所有连接,当连接的状态发生变化变化(发有数据可读),才 用一个进程/线程对那个连接进行处理,处理完以后继续监视,等待下次状态变化。用这种方式可以用少量的进程/线程应对成千上万的连接请求。
下面用 Nginx 来继续以下故事。
对 HTTP GET 请求,Nginx 利用 epoll 的方式给读取出来,Nginx 接下来要判断这是静态请求还是动态请求。如果是静态的请求自己就可以搞定(当然 依赖于 Nginx 配置,可能转发到别的缓存服务器去)读取本机硬盘上的相关文件并直接返回。
如果是动态请求,需要后端服务器(如 Tomcat)处理以后才能返回,那就需要向 Tomcat 转发,如果后端的 Tomcat 还不止一个,那就需要按照某种策略 选取一个。
例如 Nginx 支持这么几种:
- 轮询:按照次序挨个向后端服务器转发。
- 权重:给每个后端服务器指定一个权重,相当于向后端服务器转发的几率。
- ip_hash:根据 ip 做一个 hash 操作,然后找个服务器转发,这样的话同一个客户端 ip 总是会转发到同一个后端服务器。
- fair:根据后端服务器的响应时间来分配请求,响应时间段的优先分配。
不管用哪种算法,某个后端服务器最终被选中,然后 Nginx 需要把 HTTP Request 转发给后端的 Tomcat,并且把 Tomcat 输出的 HTTP Response 再转发给浏览器。在这种场景下,Nginx 是一个代理人的角色。
应用服务器
HTTP Request 来到 Tomcat,这是一个由 Java 写的、可以处理 Servlet/JSP 的容器。如同 Web 服务器一样,Tomcat 也可能为每个请求分配一个 线程去处理,即通常所说的 BIO 模式(Blocking I/O 模式)。也有可能使用 I/O 多路利用技术,仅仅使用若干线程来处理所有请求,即 NIO 模式。
不管用哪种方式,HTTP Request 都会被交给某个 Servlet 处理,这个 Servlet 又会把 HTTP Request 做转换,变成框架所使用的参数格式,然后分 发给某个 Controller(如果在用 Spring) 或 Action(如果在用 Struts)。
剩下的就是码农的各种业务逻辑。
归途
Tomcat 把 HTTP Response 发给 Nginx,Nginx 把 HTTP Response 发给了浏览器。完整请求响应后,如果使用连接 keep-alive,TCP 连接不能关闭。
浏览器再次工作
浏览器收到了响应,从其中读取了 HTML 页面,开始准备显示这个页面。但是这个 HTML 页面中可能引用了大量其他资源,例如 js、css 文件。浏览器 只好一个个地发出新的请求,重做之前的步骤。如果需要下载的外部资源太多,浏览器会创建多个 TCP 连接,并行地下载。但是同一时间对同一域名的请求 数量也不能太多,不然服务器访问量太大,所以浏览器要限制并行数。
当服务器给浏览器发送 js,css 这些文件时,会告诉浏览器这些文件什么时候过期(Cache-Control, Expire),浏览器可以把文件缓存到本地,当第二 次请求同样的文件时,如果不过期,直接从本地取就可以了。
如果过期了,浏览器可以访问服务端,文件有没有修改过?(依据上一次服务器发送的 Last-Modified 和 ETag),如果没有修改(304 Not Modified), 还可以使用缓存。否则的话服务器就会把最新的文件发回给浏览器。